Explaining Mixtures of Sources in News Articles
作者: Alexander Spangher, James Youn, Matt DeButts, Nanyun Peng, Emilio Ferrara, Jonathan May
分类: cs.CL, cs.AI
发布日期: 2024-11-07
备注: 9 pages
💡 一句话要点
提出新闻文章中来源选择的解释框架,通过预测来源选择模式理解记者写作计划。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 新闻生成 来源选择 写作计划 长文本生成 贝叶斯模型
📋 核心要点
- 现有长文本生成模型缺乏对人类写作计划的理解,尤其是在新闻领域,来源选择是关键的计划步骤。
- 该论文提出了一种基于来源选择模式的框架,通过预测记者使用的模式来理解文章的写作计划。
- 实验表明,立场和社会关系模式最能解释大多数新闻文章的来源选择,而文本蕴含模式在科学类文章中表现更好。
📝 摘要(中文)
为了使大型语言模型(LLM)在长篇新闻文章生成中发挥作用,我们需要理解人类在写作前的计划步骤。本文以新闻中的来源选择为例,探索一种计划类型,用于评估长篇生成中的计划。我们探究了为什么特定的故事需要特定类型的来源。我们设想了一个故事写作的生成过程,记者首先选择一个来源选择模式,然后根据该模式中的类别选择来源。学习文章的计划意味着预测记者最初选择的模式。我们与专业记者合作,调整了五个现有的模式,并引入了三个新的模式来描述新闻记者在文档中包含来源的计划。然后,受到贝叶斯隐变量建模的启发,我们开发了指标来选择故事背后最可能的计划或模式,并用它来比较不同的模式。我们发现,立场和社会关系这两种模式最能解释大多数文档中的来源计划。然而,其他模式,如文本蕴含,可以解释“科学”等事实丰富的文章中的来源计划。最后,我们发现仅根据文章的标题就可以合理地预测最合适的模式。我们认为这是一个重要的人类计划案例研究,并为评估其他类型的计划提供了一个框架和方法。我们发布了一个包含400万篇文章注释的语料库NewsSources。
🔬 方法详解
问题定义:论文旨在解决长文本生成中,大型语言模型缺乏对人类写作计划理解的问题,特别是在新闻领域,记者如何选择信息来源是一个重要的计划环节。现有方法难以解释为什么特定新闻故事需要特定类型的来源,缺乏对记者写作意图的建模。
核心思路:论文的核心思路是将新闻写作过程建模为一个生成过程,记者首先选择一个来源选择模式(schema),然后根据该模式选择具体的来源。通过预测文章对应的来源选择模式,可以理解记者的写作计划,从而指导长文本生成。这种方法借鉴了贝叶斯隐变量建模的思想,将来源选择模式视为隐变量。
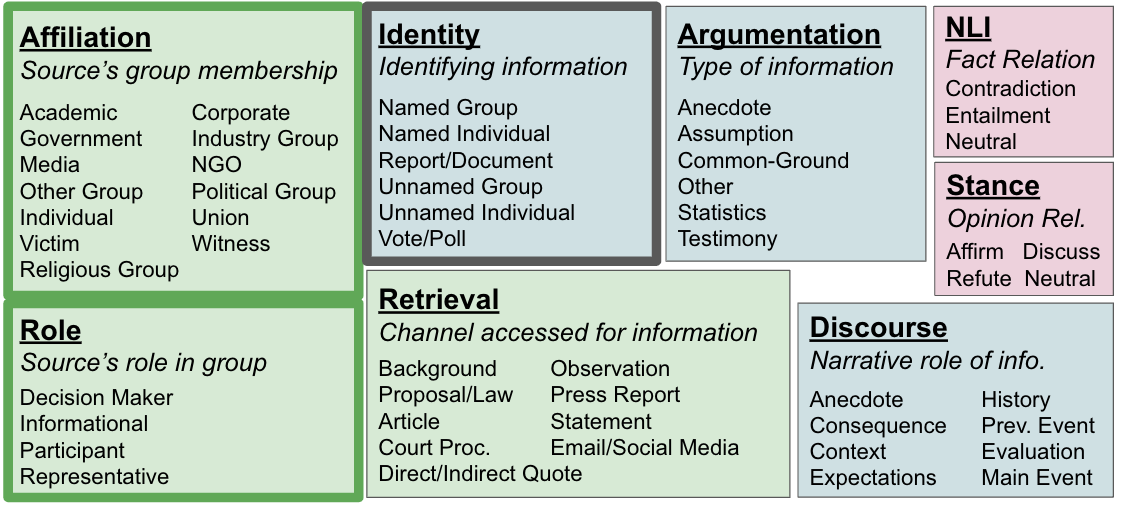
技术框架:整体框架包括以下几个阶段:1) 定义来源选择模式:与专业记者合作,定义了8种来源选择模式(5个现有模式+3个新模式),用于描述记者在文章中选择来源的计划。2) 数据标注:构建了一个包含400万篇新闻文章的语料库NewsSources,并对文章的来源选择模式进行标注。3) 模式预测:开发了基于贝叶斯隐变量建模的指标,用于选择最能解释文章来源选择的模式。4) 评估:通过实验评估了不同模式的解释能力,并验证了仅使用文章标题预测来源选择模式的可行性。
关键创新:论文的关键创新在于:1) 提出了基于来源选择模式的新闻写作计划建模方法,为理解长文本生成中的人类计划提供了一个新的视角。2) 构建了一个大规模的新闻文章来源选择模式标注语料库NewsSources,为相关研究提供了数据基础。3) 开发了基于贝叶斯隐变量建模的模式预测指标,能够有效地选择最能解释文章来源选择的模式。
关键设计:论文的关键设计包括:1) 来源选择模式的定义:与专业记者合作,定义了8种来源选择模式,包括立场、社会关系、文本蕴含等。2) 模式预测指标:基于贝叶斯隐变量建模,设计了用于选择最可能模式的指标,具体细节未知。3) 实验设置:通过实验评估了不同模式的解释能力,并验证了仅使用文章标题预测来源选择模式的可行性,具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,立场和社会关系模式最能解释大多数新闻文章的来源选择,而文本蕴含模式在科学类文章中表现更好。此外,仅使用文章标题就可以合理地预测最合适的来源选择模式,这表明文章标题包含了重要的写作计划信息。具体性能数据未知。
🎯 应用场景
该研究成果可应用于新闻自动生成、新闻内容理解、信息检索等领域。通过理解新闻文章的来源选择计划,可以生成更符合人类写作习惯的新闻内容,提高新闻生成质量。此外,该方法还可以用于分析新闻文章的偏见和立场,辅助信息检索和舆情分析。
📄 摘要(原文)
Human writers plan, then write. For large language models (LLMs) to play a role in longer-form article generation, we must understand the planning steps humans make before writing. We explore one kind of planning, source-selection in news, as a case-study for evaluating plans in long-form generation. We ask: why do specific stories call for specific kinds of sources? We imagine a generative process for story writing where a source-selection schema is first selected by a journalist, and then sources are chosen based on categories in that schema. Learning the article's plan means predicting the schema initially chosen by the journalist. Working with professional journalists, we adapt five existing schemata and introduce three new ones to describe journalistic plans for the inclusion of sources in documents. Then, inspired by Bayesian latent-variable modeling, we develop metrics to select the most likely plan, or schema, underlying a story, which we use to compare schemata. We find that two schemata: stance and social affiliation best explain source plans in most documents. However, other schemata like textual entailment explain source plans in factually rich topics like "Science". Finally, we find we can predict the most suitable schema given just the article's headline with reasonable accuracy. We see this as an important case-study for human planning, and provides a framework and approach for evaluating other kinds of plans. We release a corpora, NewsSources, with annotations for 4M articles.