Performance-Guided LLM Knowledge Distillation for Efficient Text Classification at Scale
作者: Flavio Di Palo, Prateek Singhi, Bilal Fadlallah
分类: cs.CL
发布日期: 2024-11-07
备注: Published in EMNLP 2024
💡 一句话要点
提出性能引导的LLM知识蒸馏PGKD,用于高效大规模文本分类
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 文本分类 主动学习 难负样本挖掘 性能优化 模型压缩
📋 核心要点
- 现有LLM计算需求高,推理成本大,难以满足大规模文本分类的生产需求。
- PGKD通过性能引导的知识蒸馏,将LLM知识迁移到小型模型,降低推理成本。
- 实验表明,PGKD在多类分类数据集上优于BERT-base等模型,推理速度提升显著。
📝 摘要(中文)
大型语言模型(LLM)由于其高计算需求,在推理时面临重大挑战。为了解决这个问题,我们提出了一种经济高效且高吞吐量的解决方案,即性能引导的知识蒸馏(PGKD),用于生产文本分类应用。PGKD利用教师-学生知识蒸馏将LLM的知识提炼到更小的、特定于任务的模型中。PGKD在学生模型和LLM之间建立了一个主动学习例程;LLM不断生成新的训练数据,利用难负样本挖掘、学生模型验证性能和早停协议来指导数据生成。通过采用一种循环的、性能感知的策略,专门为工业文本分类中普遍存在的高度多类、稀疏注释数据集量身定制,PGKD有效地解决了训练挑战,并在多个多类分类数据集上优于传统的BERT-base模型和其他知识蒸馏方法。此外,成本和延迟基准测试表明,使用PGKD微调的模型在相同分类任务上的推理速度比LLM快130倍,成本降低25倍。虽然PGKD主要用于文本分类任务,但其通用的框架可以扩展到任何LLM蒸馏任务,包括语言生成,使其成为优化各种AI应用性能的强大工具。
🔬 方法详解
问题定义:论文旨在解决大规模文本分类任务中,直接使用大型语言模型(LLM)进行推理时,计算成本过高、延迟过大的问题。现有方法,如直接微调LLM或使用传统的知识蒸馏方法,在处理高度多类、稀疏标注的数据集时,往往效果不佳,无法在性能和效率之间取得良好平衡。
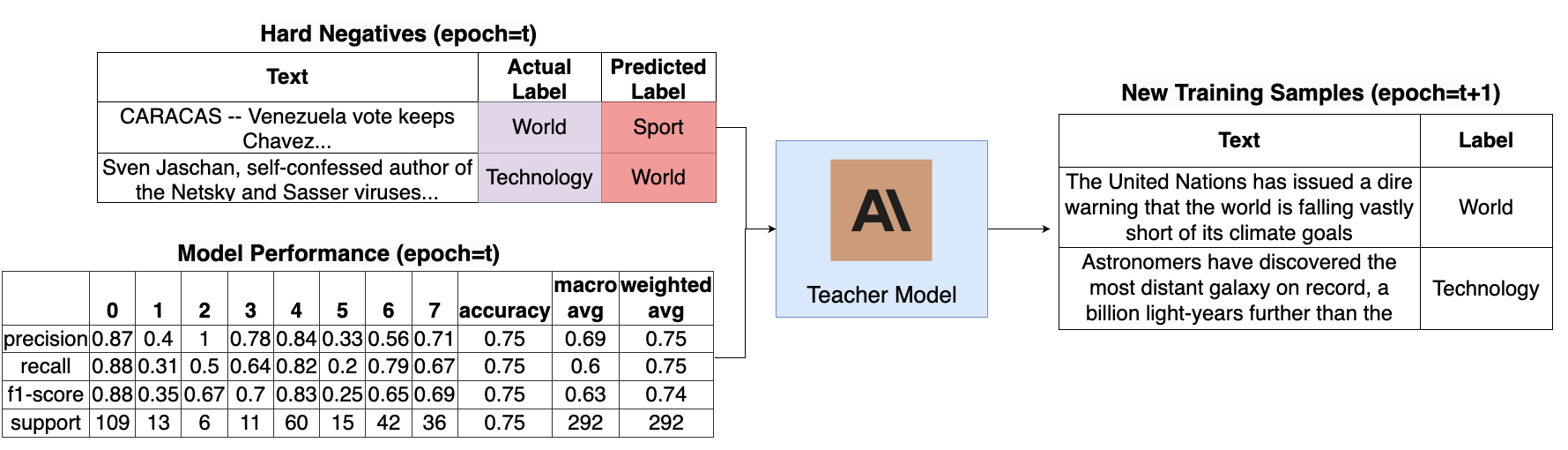
核心思路:论文的核心思路是利用性能引导的知识蒸馏(PGKD),通过主动学习的方式,让LLM作为教师模型,指导小型学生模型的训练。学生模型的训练过程受到其自身性能的反馈,LLM根据学生模型的表现,有针对性地生成新的训练数据,从而提高学生模型的性能,并最终实现高效的文本分类。
技术框架:PGKD的技术框架主要包含以下几个阶段:1) 初始化学生模型;2) LLM根据初始数据生成训练数据;3) 学生模型在生成的数据上进行训练;4) 评估学生模型在验证集上的性能;5) LLM根据学生模型的性能,利用难负样本挖掘等策略,生成新的训练数据;6) 重复步骤3-5,直到满足早停条件。整个过程形成一个循环,学生模型的性能不断提升。
关键创新:PGKD的关键创新在于其性能引导的主动学习机制。传统的知识蒸馏方法往往使用固定的训练数据集,而PGKD则根据学生模型的性能,动态地生成新的训练数据。这种方法能够更有效地利用LLM的知识,提高学生模型的性能,尤其是在处理高度多类、稀疏标注的数据集时。此外,PGKD还采用了难负样本挖掘和早停协议等策略,进一步优化了训练过程。
关键设计:PGKD的关键设计包括:1) LLM生成训练数据时,采用难负样本挖掘策略,选择学生模型容易出错的样本进行标注,从而提高学生模型的区分能力;2) 使用学生模型在验证集上的性能作为反馈信号,指导LLM生成新的训练数据;3) 采用早停协议,防止学生模型过拟合;4) 损失函数通常采用交叉熵损失或KL散度损失,用于衡量学生模型和教师模型之间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PGKD在多个多类分类数据集上优于传统的BERT-base模型和其他知识蒸馏方法。与直接使用LLM进行推理相比,使用PGKD微调的模型推理速度提升高达130倍,成本降低25倍。这些结果表明,PGKD是一种高效且经济的LLM知识蒸馏方法,能够有效解决大规模文本分类任务中的性能和效率问题。
🎯 应用场景
PGKD可应用于各种需要大规模文本分类的场景,例如:电商平台商品分类、新闻资讯主题分类、社交媒体内容审核、客户服务工单分类等。该方法能够显著降低推理成本和延迟,提高系统的吞吐量,具有重要的实际应用价值。未来,PGKD可以扩展到其他LLM蒸馏任务,例如语言生成,从而优化更广泛的AI应用。
📄 摘要(原文)
Large Language Models (LLMs) face significant challenges at inference time due to their high computational demands. To address this, we present Performance-Guided Knowledge Distillation (PGKD), a cost-effective and high-throughput solution for production text classification applications. PGKD utilizes teacher-student Knowledge Distillation to distill the knowledge of LLMs into smaller, task-specific models. PGKD establishes an active learning routine between the student model and the LLM; the LLM continuously generates new training data leveraging hard-negative mining, student model validation performance, and early-stopping protocols to inform the data generation. By employing a cyclical, performance-aware approach tailored for highly multi-class, sparsely annotated datasets prevalent in industrial text classification, PGKD effectively addresses training challenges and outperforms traditional BERT-base models and other knowledge distillation methods on several multi-class classification datasets. Additionally, cost and latency benchmarking reveals that models fine-tuned with PGKD are up to 130X faster and 25X less expensive than LLMs for inference on the same classification task. While PGKD is showcased for text classification tasks, its versatile framework can be extended to any LLM distillation task, including language generation, making it a powerful tool for optimizing performance across a wide range of AI applications.