Needle Threading: Can LLMs Follow Threads through Near-Million-Scale Haystacks?
作者: Jonathan Roberts, Kai Han, Samuel Albanie
分类: cs.CL
发布日期: 2024-11-07 (更新: 2025-04-23)
备注: Accepted at ICLR 2025
💡 一句话要点
评估LLM在近百万规模文档中追踪信息线程的能力,揭示有效上下文长度限制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文学习 信息检索 大型语言模型 线程安全 上下文窗口
📋 核心要点
- 现有方法难以有效利用长上下文信息,导致在海量文档中检索特定信息时效率低下。
- 论文设计实验评估LLM在长上下文中追踪多个信息线程的能力,考察其线程安全性和有效上下文长度。
- 实验结果表明,部分LLM具有线程安全性,但有效上下文长度通常小于模型支持的长度,准确率随上下文增长而下降。
📝 摘要(中文)
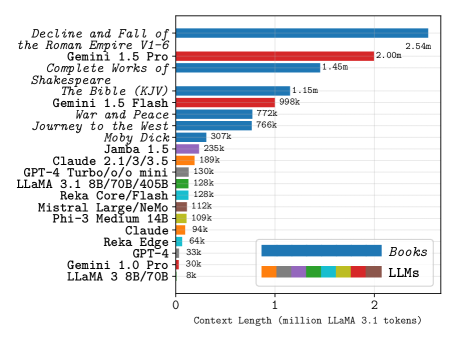
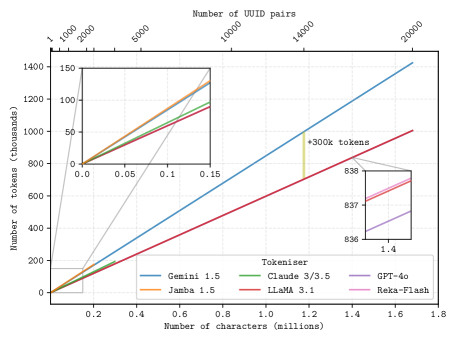
随着大型语言模型(LLM)的上下文窗口长度不断增加,其应用范围和下游功能也随之扩展。在许多实际任务中,决策依赖于分散在大量通常不相关文档中的细节信息。长上下文LLM似乎非常适合这种复杂的信息检索和推理,而传统上这种任务既耗时又昂贵。然而,尽管近年来长上下文模型的发展迅速,但我们对LLM如何有效地利用其上下文的理解并没有跟上。为了解决这个问题,我们进行了一系列检索实验,旨在评估17个领先LLM的能力,例如它们在上下文窗口中追踪信息线程的能力。令人惊讶的是,我们发现许多模型具有显著的线程安全性:能够同时追踪多个线程而不会显著降低性能。尽管如此,对于许多模型,我们发现有效的上下文长度远小于支持的上下文长度,并且随着上下文窗口的增长,准确性会降低。我们的研究还强调了一个重要的观点,即来自不同分词器的token计数不应直接比较——它们通常对应于截然不同的书面字符数。我们发布了我们的代码和长上下文实验数据。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在处理长上下文信息时的能力,特别是它们在近百万规模的文档中追踪多个信息线程的性能。现有方法在处理此类任务时面临挑战,因为LLM的上下文窗口长度虽然在增加,但模型如何有效利用这些长上下文仍然是一个未知数。现有方法的痛点在于,难以确定LLM是否能够准确地从大量无关信息中检索和推理出所需的信息,以及有效上下文长度的限制。
核心思路:论文的核心思路是通过设计一系列检索实验,模拟真实世界中需要从大量文档中提取和关联信息的场景。通过在长上下文中插入多个“线程”(即需要追踪的信息),并评估LLM在追踪这些线程时的准确性,从而评估LLM的线程安全性和有效上下文长度。这样设计的目的是为了更真实地反映LLM在实际应用中的表现,并揭示其在处理长上下文信息时的局限性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据生成:创建包含多个信息线程的长上下文文档。2) 模型选择:选择17个领先的LLM进行评估。3) 实验设计:设计检索实验,要求LLM从长上下文中提取特定信息。4) 性能评估:评估LLM在追踪不同线程时的准确性,并分析有效上下文长度。整体流程旨在系统地评估LLM在长上下文信息检索方面的能力。
关键创新:论文最重要的技术创新点在于其评估LLM长上下文信息处理能力的方法。通过设计专门的检索实验,模拟真实世界中的信息检索场景,并关注LLM在追踪多个信息线程时的表现,从而更全面地评估LLM的线程安全性和有效上下文长度。与以往的研究相比,该方法更注重评估LLM在处理复杂、长上下文信息时的实际能力。
关键设计:论文的关键设计包括:1) 上下文长度的设置:实验中使用了不同长度的上下文窗口,以评估LLM在不同上下文长度下的性能。2) 线程数量的设置:实验中使用了多个信息线程,以评估LLM的线程安全性。3) 评估指标的选择:实验中使用了准确率等指标来评估LLM的性能。4) 模型选择:选择了17个领先的LLM,以确保评估结果的代表性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,许多LLM具有一定的线程安全性,能够同时追踪多个信息线程。然而,对于许多模型,有效上下文长度远小于支持的上下文长度,并且随着上下文窗口的增长,准确性会降低。此外,研究还强调了不同分词器产生的token计数不应直接比较,因为它们对应于不同的字符数量。例如,某些模型在长上下文任务中表现出显著的性能下降,这表明其上下文利用效率有待提高。
🎯 应用场景
该研究成果可应用于需要处理大量文档的场景,如法律文件分析、金融报告解读、医学文献检索等。通过了解LLM在长上下文中的信息检索能力,可以更好地利用LLM来提高工作效率,辅助决策,并降低信息过载带来的风险。未来的研究可以进一步探索如何优化LLM的上下文利用效率,提高其在长上下文中的推理能力。
📄 摘要(原文)
As the context limits of Large Language Models (LLMs) increase, the range of possible applications and downstream functions broadens. In many real-world tasks, decisions depend on details scattered across collections of often disparate documents containing mostly irrelevant information. Long-context LLMs appear well-suited to this form of complex information retrieval and reasoning, which has traditionally proven costly and time-consuming. However, although the development of longer context models has seen rapid gains in recent years, our understanding of how effectively LLMs use their context has not kept pace. To address this, we conduct a set of retrieval experiments designed to evaluate the capabilities of 17 leading LLMs, such as their ability to follow threads of information through the context window. Strikingly, we find that many models are remarkably threadsafe: capable of simultaneously following multiple threads without significant loss in performance. Still, for many models, we find the effective context limit is significantly shorter than the supported context length, with accuracy decreasing as the context window grows. Our study also highlights the important point that token counts from different tokenizers should not be directly compared -- they often correspond to substantially different numbers of written characters. We release our code and long-context experimental data.