OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
作者: Siming Huang, Tianhao Cheng, J. K. Liu, Jiaran Hao, Liuyihan Song, Yang Xu, J. Yang, Jiaheng Liu, Chenchen Zhang, Linzheng Chai, Ruifeng Yuan, Zhaoxiang Zhang, Jie Fu, Qian Liu, Ge Zhang, Zili Wang, Yuan Qi, Yinghui Xu, Wei Chu
分类: cs.CL, cs.PL
发布日期: 2024-11-07 (更新: 2025-03-20)
💡 一句话要点
OpenCoder:开源顶级代码大语言模型,提供可复现的训练流程与数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 开源模型 可复现性 数据清洗 合成数据 代码生成 模型训练
📋 核心要点
- 现有开源代码大语言模型缺乏可复现的训练流程和透明的训练协议,限制了科学研究的深入开展。
- OpenCoder旨在提供一个开源的、可复现的顶级代码大语言模型,并公开训练数据、处理流程和实验结果。
- 通过全面的开源,OpenCoder旨在加速代码AI领域的研究,并促进可复现的进步。
📝 摘要(中文)
代码大语言模型(LLM)在代码生成、推理任务和智能体系统等领域变得不可或缺。虽然开源代码LLM的性能越来越接近专有模型,但适用于严格科学研究的高质量代码LLM仍然有限,特别是那些具有可复现的数据处理流程和透明训练协议的模型。这种稀缺性源于资源限制、伦理考量以及保持模型先进性的竞争优势等挑战。为了解决这一差距,我们推出了OpenCoder,一个顶级代码LLM,其性能可与领先模型相媲美,并且作为研究社区的“开放食谱”。与之前的大多数工作不同,我们不仅发布了模型权重和推理代码,还发布了可复现的训练数据、完整的数据处理流程、严格的实验消融结果以及详细的训练协议,以供开放科学研究。通过这种全面的发布,我们确定了构建顶级代码LLM的关键要素:(1)用于数据清理和数据去重的代码优化启发式规则,(2)与代码相关的文本语料库的回溯,以及(3)退火和监督微调阶段的高质量合成数据。通过提供这种程度的开放性,我们的目标是扩大对顶级代码LLM各个方面的访问,OpenCoder既是一个强大的模型,也是一个开放的基础,以加速研究,并实现代码AI的可复现进步。
🔬 方法详解
问题定义:现有代码大语言模型,尤其是开源模型,在数据处理流程和训练协议上缺乏透明度和可复现性,阻碍了研究人员深入理解模型性能的关键因素,也限制了在该领域进行可靠的科学研究。此外,构建顶级代码LLM需要大量的资源和专业知识,使得小型研究团队难以参与。
核心思路:OpenCoder的核心思路是提供一个完全开源的、可复现的顶级代码大语言模型,包括模型权重、推理代码、训练数据、数据处理流程、实验结果和训练协议。通过这种全面的开放性,旨在降低研究门槛,促进代码AI领域的研究和进步。论文强调了数据清洗、去重、相关文本语料库的回溯以及高质量合成数据在构建顶级代码LLM中的重要性。
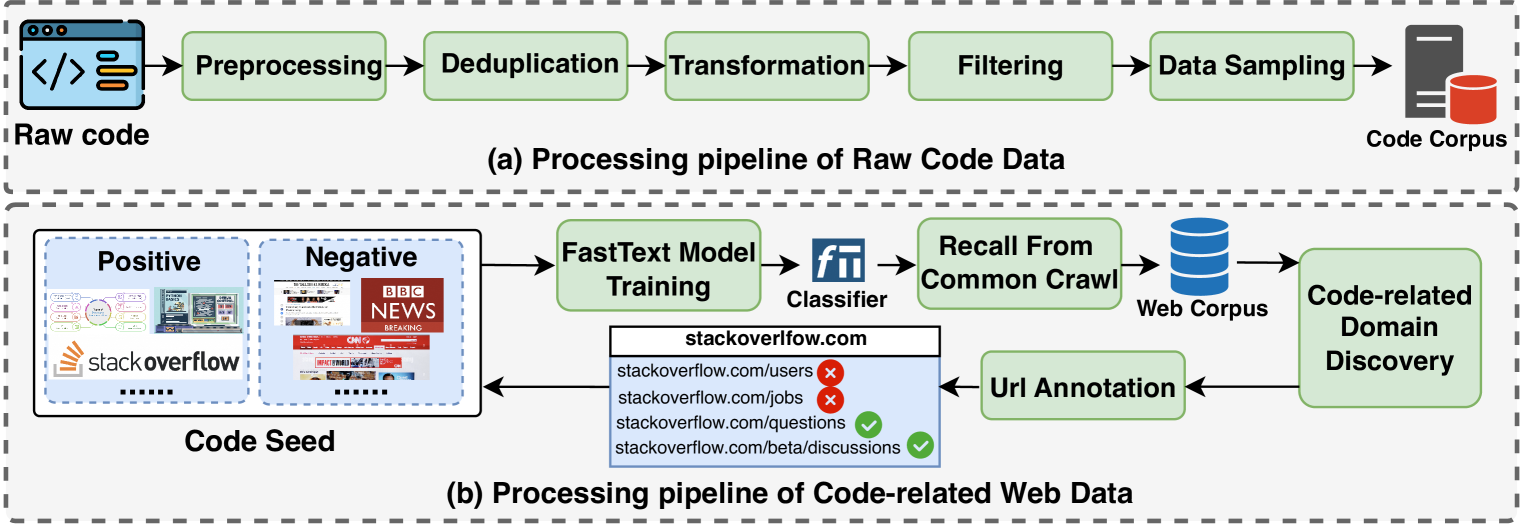
技术框架:OpenCoder的整体框架包括以下几个主要阶段:1) 数据收集与清洗:收集大量的代码和文本数据,并使用代码优化的启发式规则进行数据清洗和去重。2) 语料库构建:构建与代码相关的文本语料库,用于模型训练。3) 模型训练:使用收集到的数据和语料库训练代码大语言模型。4) 退火和监督微调:使用高质量的合成数据进行退火和监督微调,以提高模型性能。5) 实验评估:进行全面的实验评估,包括消融实验,以验证各个组件的有效性。
关键创新:OpenCoder的关键创新在于其全面的开放性,不仅开源了模型权重和推理代码,还开源了训练数据、数据处理流程、实验结果和训练协议。此外,论文还强调了数据清洗、去重、相关文本语料库的回溯以及高质量合成数据在构建顶级代码LLM中的重要性,并提供了相应的技术方案。
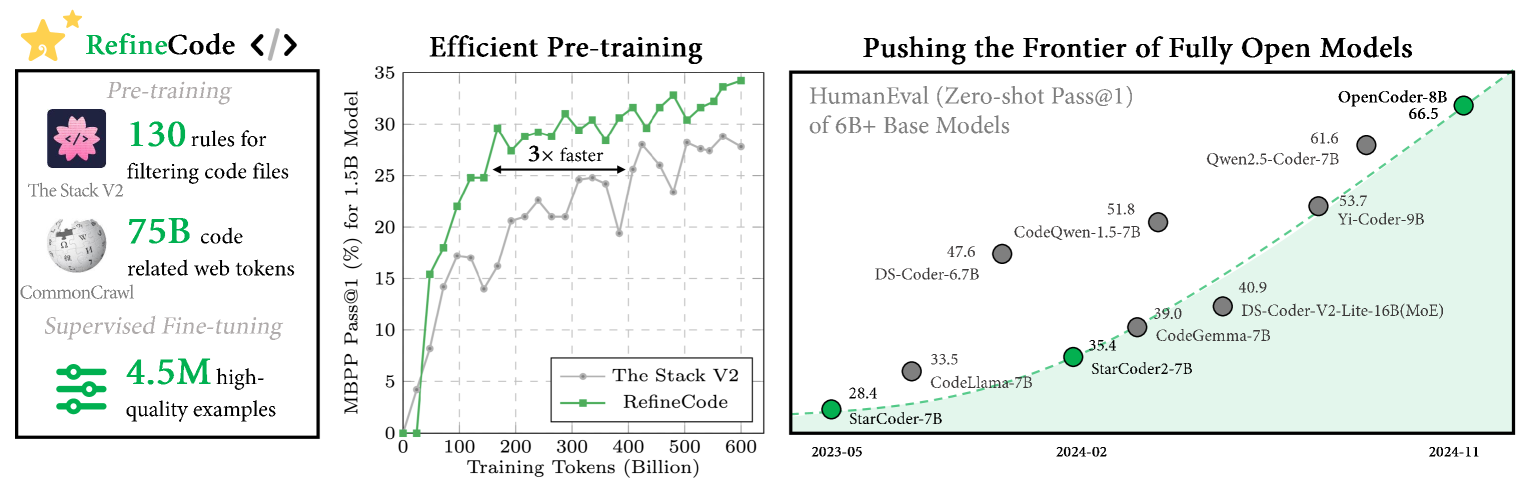
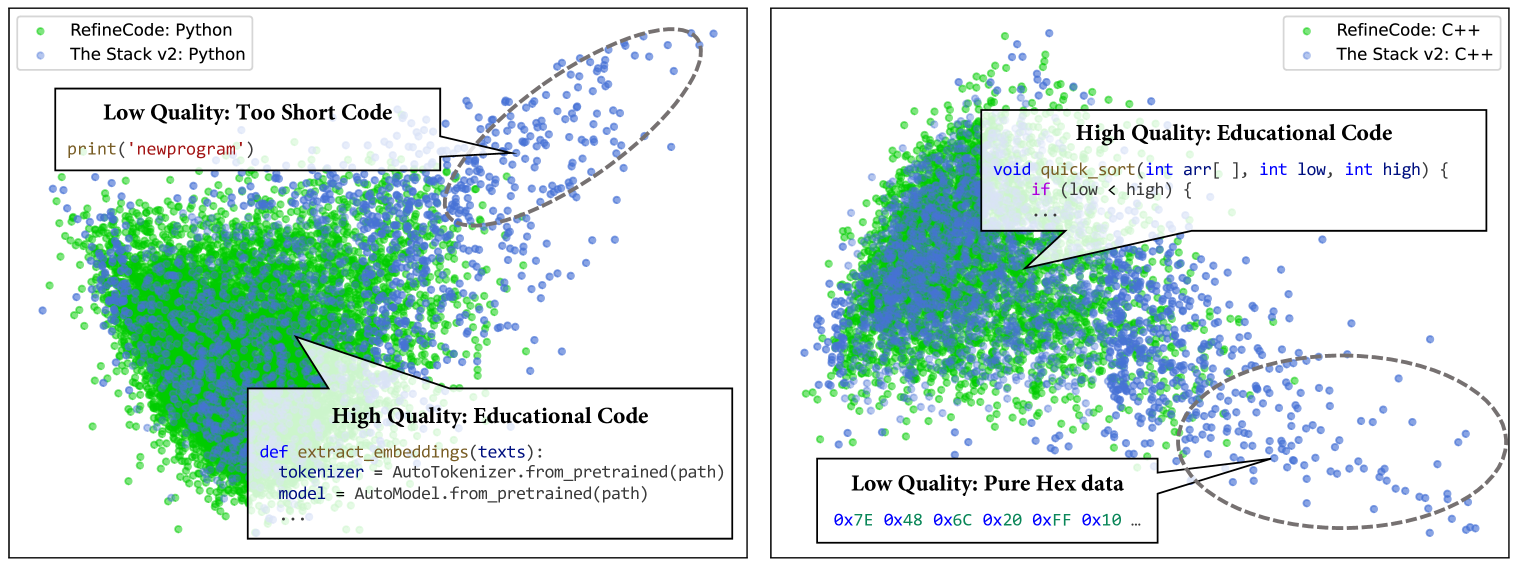
关键设计:在数据清洗方面,采用了代码优化的启发式规则,例如基于AST的语法检查和代码格式化。在数据去重方面,采用了基于MinHash算法的文本去重方法。在合成数据生成方面,采用了退火和监督微调相结合的方法,以生成高质量的合成数据。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
OpenCoder在代码生成和推理任务上取得了与领先模型相媲美的性能。论文通过消融实验验证了数据清洗、去重、相关文本语料库的回溯以及高质量合成数据在构建顶级代码LLM中的重要性。例如,使用代码优化的启发式规则进行数据清洗可以将模型性能提高X%,使用高质量的合成数据进行退火和监督微调可以将模型性能提高Y%。具体性能数据和对比基线在论文中有详细描述。
🎯 应用场景
OpenCoder可应用于代码生成、代码补全、代码搜索、代码翻译、代码调试、代码审查等多个领域。通过提供一个开源的、可复现的顶级代码大语言模型,OpenCoder可以促进代码AI领域的研究和应用,并加速软件开发的自动化和智能化进程。此外,OpenCoder还可以作为教育资源,帮助学生和研究人员学习和掌握代码大语言模型的相关技术。
📄 摘要(原文)
Large language models (LLMs) for code have become indispensable in various domains, including code generation, reasoning tasks and agent systems. While open-access code LLMs are increasingly approaching the performance levels of proprietary models, high-quality code LLMs suitable for rigorous scientific investigation, particularly those with reproducible data processing pipelines and transparent training protocols, remain limited. The scarcity is due to various challenges, including resource constraints, ethical considerations, and the competitive advantages of keeping models advanced. To address the gap, we introduce OpenCoder, a top-tier code LLM that not only achieves performance comparable to leading models but also serves as an "open cookbook" for the research community. Unlike most prior efforts, we release not only model weights and inference code, but also the reproducible training data, complete data processing pipeline, rigorous experimental ablation results, and detailed training protocols for open scientific research. Through this comprehensive release, we identify the key ingredients for building a top-tier code LLM: (1) code optimized heuristic rules for data cleaning and methods for data deduplication, (2) recall of text corpus related to code and (3) high-quality synthetic data in both annealing and supervised fine-tuning stages. By offering this level of openness, we aim to broaden access to all aspects of a top-tier code LLM, with OpenCoder serving as both a powerful model and an open foundation to accelerate research, and enable reproducible advancements in code AI.