VTechAGP: An Academic-to-General-Audience Text Paraphrase Dataset and Benchmark Models
作者: Ming Cheng, Jiaying Gong, Chenhan Yuan, William A. Ingram, Edward Fox, Hoda Eldardiry
分类: cs.CL, cs.DL, cs.LG
发布日期: 2024-11-07 (更新: 2025-02-21)
备注: 21 pages, 3 figures, accepted for publication in NAACL 2025 Main Conference
💡 一句话要点
提出VTechAGP学术-通俗文本释义数据集与DSPT5模型,解决学术文本通俗化难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本释义 学术文本通俗化 动态软提示 对比学习 自然语言生成
📋 核心要点
- 现有文本简化或释义数据集主要集中于通用领域的句子级文本生成,缺乏领域知识。
- 论文提出动态软提示生成语言模型DSPT5,并结合对比生成损失和众包采样解码策略。
- 实验表明,DSPT5模型性能优于现有大型语言模型,为学术文本通俗化提供有效方案。
📝 摘要(中文)
本文发布了一个新的数据集VTechAGP,这是第一个学术-通俗文本释义数据集,包含来自8所大学25年间的论文和学位论文的学术摘要与通俗摘要配对。同时,提出了一种新的动态软提示生成语言模型DSPT5。在训练中,利用对比生成损失函数来学习动态提示中的关键词向量。在推理中,采用语义和结构层面的众包采样解码策略,以进一步选择最佳输出候选。从多个角度评估了DSPT5和各种最先进的大型语言模型(LLM)。结果表明,SOTA LLM没有提供令人满意的结果,而轻量级的DSPT5可以取得有竞争力的结果。据我们所知,我们是第一个为学术-通俗文本释义数据集构建基准数据集和解决方案的人。模型将在接收后公开。
🔬 方法详解
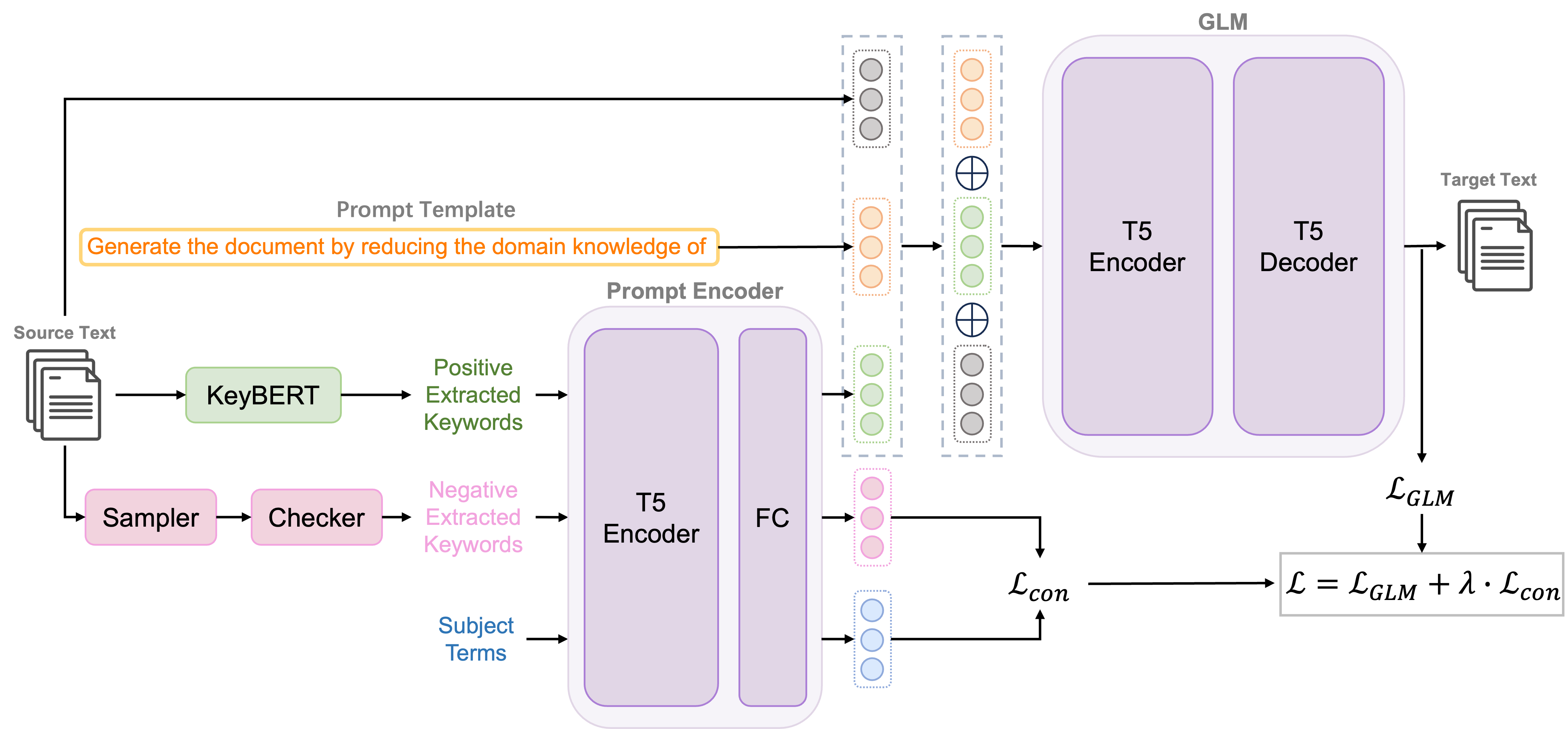
问题定义:论文旨在解决学术文本到通俗文本的释义问题,即如何将学术论文或学位论文的摘要转换为更易于普通大众理解的通俗版本。现有方法或数据集通常侧重于通用领域的句子级释义,缺乏针对特定领域(如学术领域)的知识,导致释义效果不佳。
核心思路:论文的核心思路是利用动态软提示(Dynamic Soft Prompt)来引导生成模型,使其能够更好地捕捉学术文本的特征,并生成更符合通俗化要求的文本。通过对比生成损失函数,模型可以学习到关键词向量,从而更好地理解学术文本的语义。同时,采用众包采样解码策略,从多个候选输出中选择最佳结果。
技术框架:整体框架包括三个主要部分:1) 数据集构建:构建VTechAGP数据集,包含学术摘要和通俗摘要的配对数据;2) 模型训练:使用DSPT5模型,并结合对比生成损失函数进行训练;3) 模型推理:采用众包采样解码策略,生成并选择最佳的通俗化文本。
关键创新:论文的关键创新在于提出了动态软提示生成模型DSPT5,并将其应用于学术文本通俗化任务。与传统的静态提示方法相比,动态软提示可以根据输入文本动态调整提示内容,从而更好地适应不同的学术文本。此外,对比生成损失函数和众包采样解码策略也有助于提高生成文本的质量。
关键设计:DSPT5模型基于T5架构,并在输入层添加了动态软提示。动态软提示由一组可学习的向量组成,这些向量通过对比生成损失函数进行训练,以捕捉学术文本的关键词信息。对比生成损失函数旨在最大化正样本(即通俗摘要)的生成概率,同时最小化负样本(即其他不相关的文本)的生成概率。众包采样解码策略则通过从多个候选输出中选择最佳结果来提高生成文本的质量。具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DSPT5模型在VTechAGP数据集上取得了具有竞争力的结果,优于现有的SOTA大型语言模型。虽然具体性能数据未知,但论文强调DSPT5模型在学术文本通俗化任务上的有效性,并为该领域的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于学术知识普及、科研成果转化、在线教育等领域。通过自动将学术论文转换为通俗易懂的文本,可以帮助普通大众更好地理解科学研究,促进科研成果的传播和应用,并提升在线教育资源的质量。
📄 摘要(原文)
Existing text simplification or paraphrase datasets mainly focus on sentence-level text generation in a general domain. These datasets are typically developed without using domain knowledge. In this paper, we release a novel dataset, VTechAGP, which is the first academic-to-general-audience text paraphrase dataset consisting of document-level these and dissertation academic and general-audience abstract pairs from 8 colleges authored over 25 years. We also propose a novel dynamic soft prompt generative language model, DSPT5. For training, we leverage a contrastive-generative loss function to learn the keyword vectors in the dynamic prompt. For inference, we adopt a crowd-sampling decoding strategy at both semantic and structural levels to further select the best output candidate. We evaluate DSPT5 and various state-of-the-art large language models (LLMs) from multiple perspectives. Results demonstrate that the SOTA LLMs do not provide satisfactory outcomes, while the lightweight DSPT5 can achieve competitive results. To the best of our knowledge, we are the first to build a benchmark dataset and solutions for academic-to-general-audience text paraphrase dataset. Models will be public after acceptance.