Meta-Reasoning Improves Tool Use in Large Language Models
作者: Lisa Alazraki, Marek Rei
分类: cs.CL, cs.AI
发布日期: 2024-11-07 (更新: 2025-02-08)
备注: NAACL 2025 Findings
DOI: 10.18653/v1/2025.findings-naacl.440
💡 一句话要点
TECTON:通过元推理提升大型语言模型工具使用能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 元推理 数学推理 工具选择
📋 核心要点
- 现有工具使用方法依赖贪婪解码,忽略了候选工具集选择的重要性,限制了模型性能。
- TECTON通过两阶段流程,先生成候选工具集,再进行元推理选择,提升工具选择的准确性。
- 实验表明,TECTON在数学推理任务上,无论分布内还是分布外,均取得了显著的性能提升。
📝 摘要(中文)
外部工具能够帮助大型语言模型成功完成那些它们通常无法胜任的任务。在现有的框架中,测试时选择工具依赖于简单的贪婪解码,而不管模型是否已经在工具标注的数据上进行了微调,或者使用了上下文示例进行提示。与此相反,我们发现收集和选择一组合适的候选工具更有可能实现最佳选择。我们提出了通过元推理进行工具选择(TECTON),这是一个两阶段系统,首先对任务进行推理,并使用自定义的微调语言建模头输出候选工具。然后,在禁用自定义头的情况下,它进行元推理(即,它对先前的推理过程进行推理)以做出最终选择。我们表明,TECTON 在一系列数学推理数据集上实现了显著的收益——无论是在分布内还是分布外。
🔬 方法详解
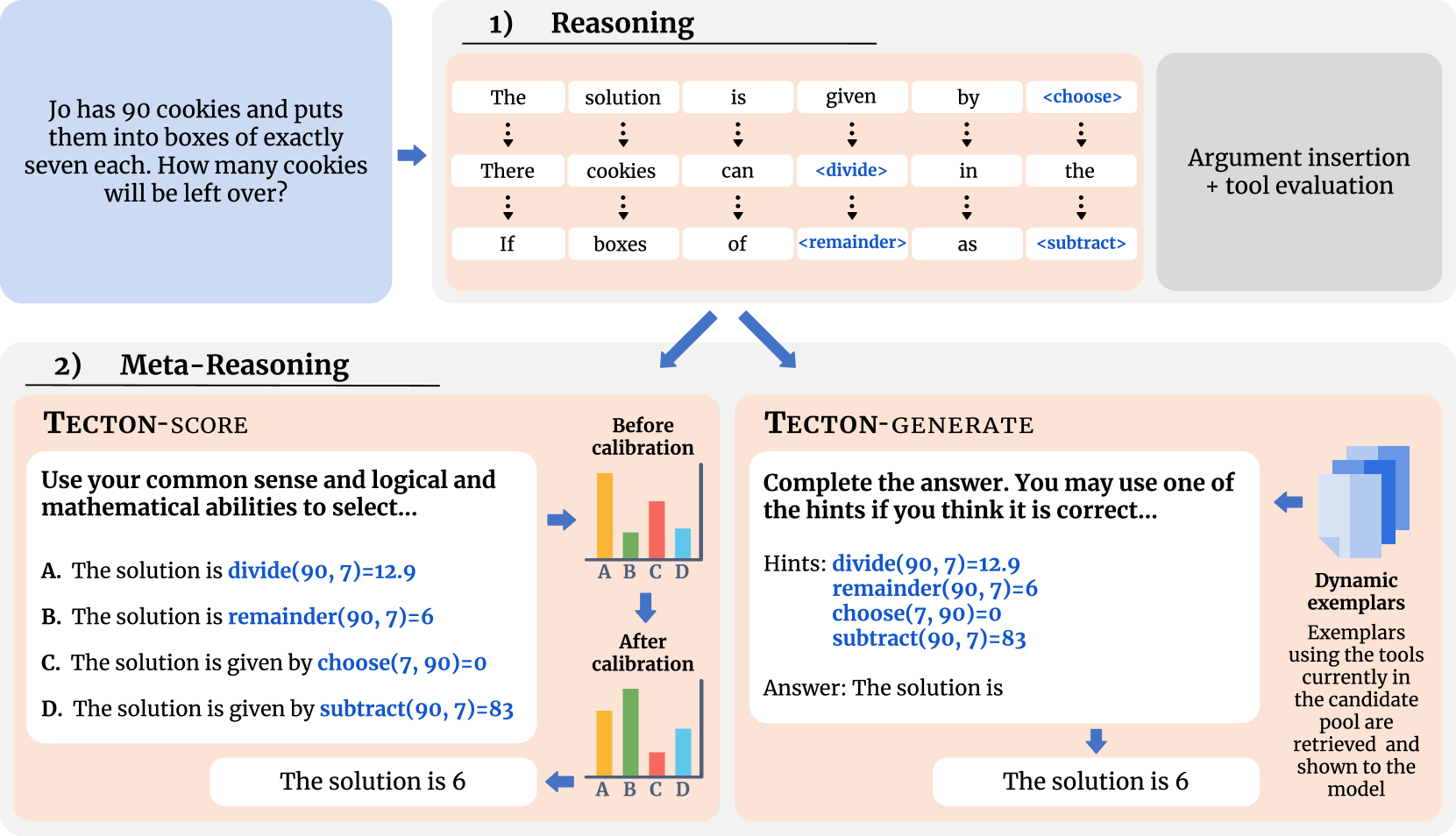
问题定义:现有的大型语言模型在使用外部工具时,通常采用贪婪解码的方式选择工具,即每次选择概率最高的工具。这种方法忽略了工具之间的依赖关系以及全局最优解的可能性,尤其是在复杂任务中,容易导致次优的工具选择,从而影响最终任务的完成质量。现有的微调和上下文学习方法也难以有效解决这个问题。
核心思路:TECTON的核心思路是引入元推理(meta-reasoning)机制,让模型不仅对任务本身进行推理,还对自身的推理过程进行反思和评估。通过生成多个候选工具,并对这些候选工具进行排序和选择,从而更全面地考虑各种可能性,最终选择最合适的工具组合。这种方法模拟了人类解决问题时“三思而后行”的策略。
技术框架:TECTON是一个两阶段的系统: 1. 候选工具生成阶段:使用一个经过微调的语言模型头部,根据任务描述生成一组候选工具。这个头部专门用于预测可能的工具序列。 2. 元推理选择阶段:禁用之前的语言模型头部,模型对第一阶段生成的候选工具集进行推理,评估每个工具的有效性和适用性,最终选择一个或多个工具来完成任务。这个阶段利用了大型语言模型强大的推理能力,对候选工具进行综合评估。
关键创新:TECTON的关键创新在于引入了元推理的概念,将工具选择问题转化为一个更高级别的推理问题。与传统的贪婪解码方法不同,TECTON不是简单地选择概率最高的工具,而是通过对候选工具集进行评估和排序,从而选择最合适的工具。这种方法能够更好地利用大型语言模型的推理能力,提高工具选择的准确性。
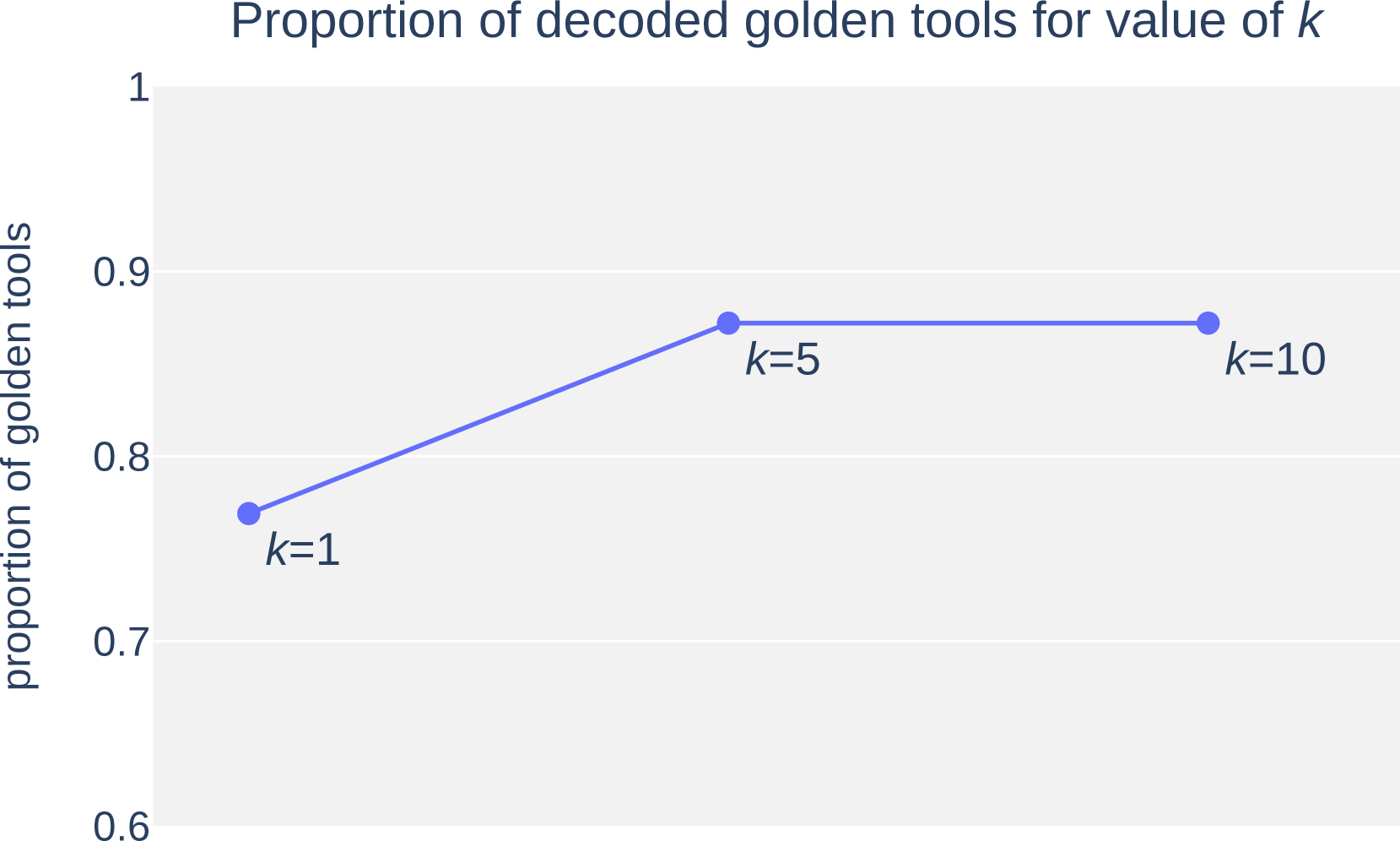
关键设计: * 微调的语言模型头部:用于生成候选工具集,其训练目标是最大化正确工具序列的概率。 * 元推理选择机制:使用大型语言模型对候选工具集进行评估,可以采用不同的策略,例如基于规则的排序、基于模型的排序等。 * 损失函数:在候选工具生成阶段,通常使用交叉熵损失函数来训练语言模型头部。 * 超参数:候选工具集的数量是一个重要的超参数,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
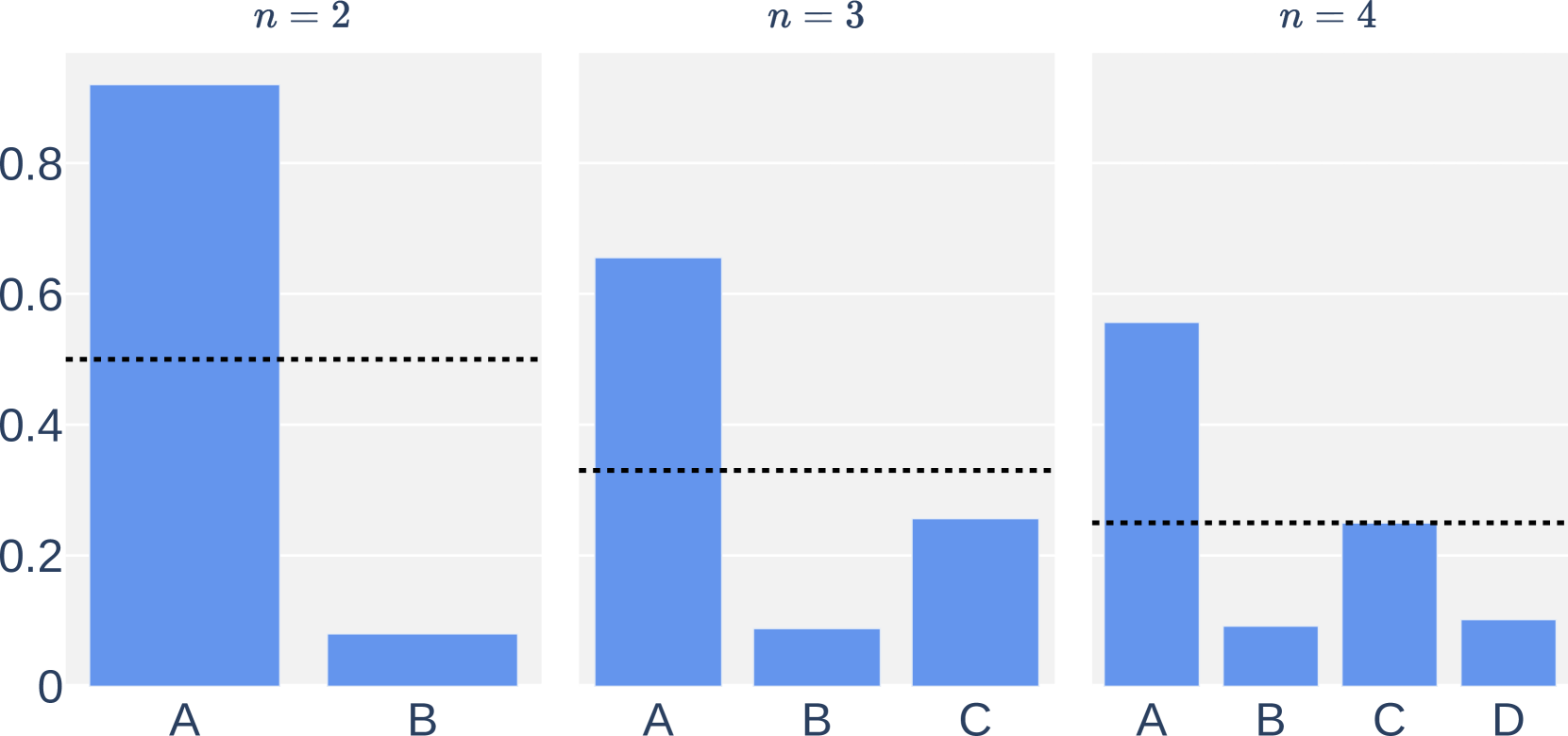
实验结果表明,TECTON 在数学推理数据集上取得了显著的性能提升。例如,在某些数据集上,TECTON 的准确率比基线方法提高了 10% 以上。此外,TECTON 在分布外数据上也表现出良好的泛化能力,表明该方法具有较强的鲁棒性。这些结果验证了元推理在工具选择中的有效性。
🎯 应用场景
TECTON 方法可应用于各种需要大型语言模型使用外部工具的场景,例如科学计算、数据分析、知识检索等。该方法能够提升模型在复杂任务中的表现,提高自动化程度和效率,具有广泛的应用前景。未来,可以进一步探索如何将元推理应用于更复杂的工具使用场景,例如多步工具调用、工具组合等。
📄 摘要(原文)
External tools help large language models succeed at tasks where they would otherwise typically fail. In existing frameworks, choosing tools at test time relies on naive greedy decoding, regardless of whether the model has been fine-tuned on tool-annotated data or prompted with in-context examples. In contrast, we find that gathering and choosing among a suitable set of candidate tools has greater potential to lead to an optimal selection. We present Tool selECTion via meta-reasONing (TECTON), a two-phase system that first reasons over a task and outputs candidate tools using a custom fine-tuned language modelling head. Then, with the custom head disabled, it meta-reasons (i.e., it reasons over the previous reasoning process) to make a final choice. We show that TECTON results in substantial gains--both in-distribution and out-of-distribution--on a range of math reasoning datasets.