How Does A Text Preprocessing Pipeline Affect Ontology Matching?
作者: Zhangcheng Qiang, Kerry Taylor, Weiqing Wang
分类: cs.CL, cs.IR
发布日期: 2024-11-06 (更新: 2025-10-17)
备注: 14 pages, 16 figures, 3 tables
💡 一句话要点
研究文本预处理流程对本体匹配的影响,并提出基于逻辑和LLM的修复方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本体匹配 文本预处理 知识图谱 大型语言模型 逻辑推理
📋 核心要点
- 现有的本体匹配系统依赖于标准文本预处理流程,但缺乏标准化的预处理导致映射结果多样且可能引入错误。
- 论文提出两种修复方法:一是预处理前基于本体逻辑的修复,针对常用词导致的错误;二是预处理后基于LLM的修复,针对不存在或违反直觉的错误。
- 实验结果表明,提出的两种修复方法能够显著提高本体匹配的正确性和整体性能,验证了方法的有效性。
📝 摘要(中文)
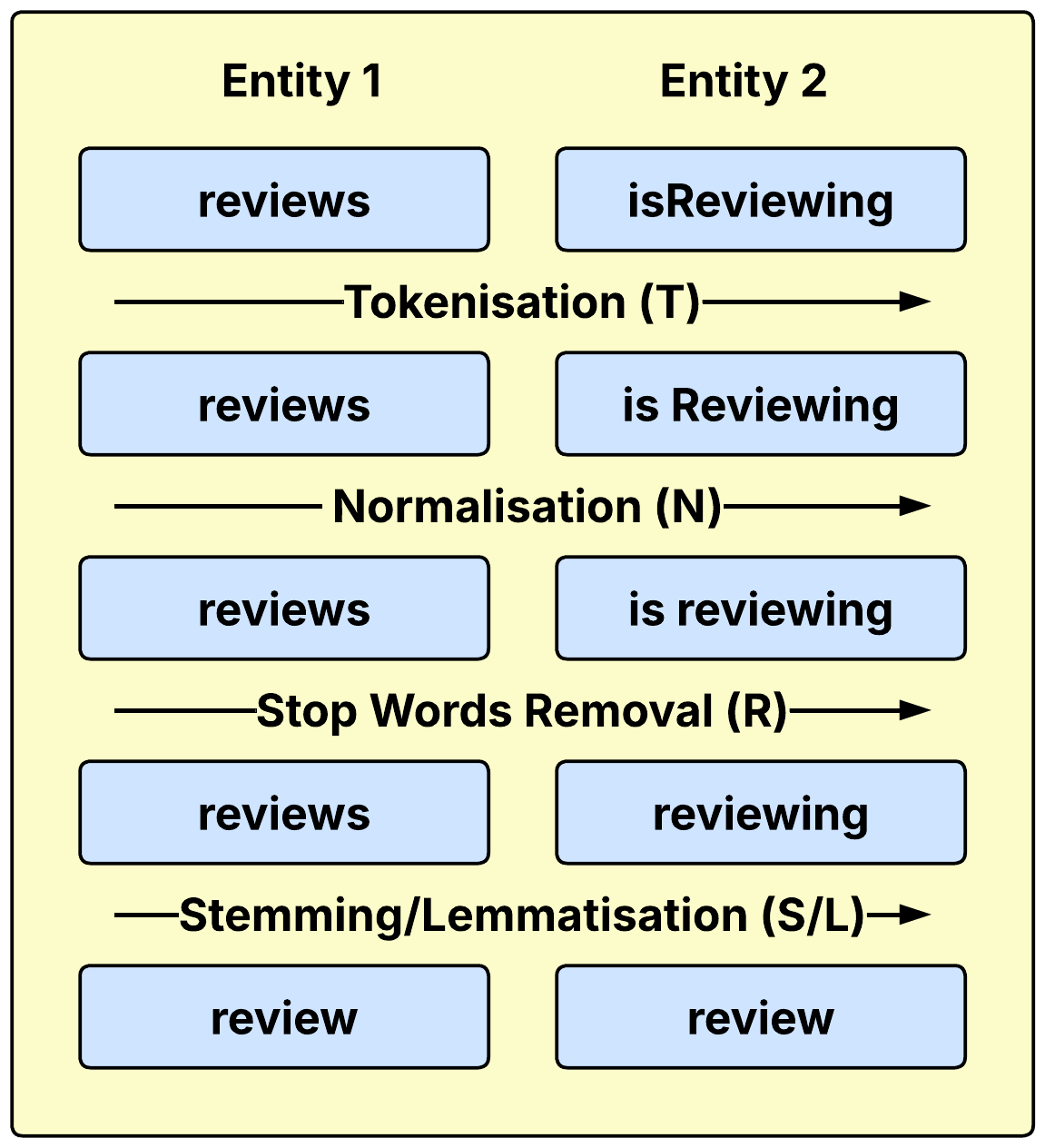
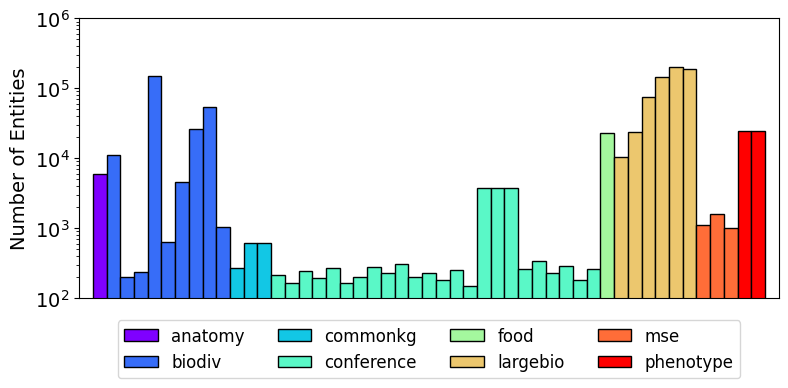
本文研究了经典的文本预处理流程(包括分词、归一化、停用词移除和词干提取/词形还原)对本体匹配(OM)的影响。该流程已在许多系统中实现。由于文本预处理缺乏标准化,导致映射结果存在多样性。本文在8个本体对齐评估倡议(OAEI)的track上,针对49个不同的对齐进行了研究。研究发现,分词和归一化(归类为第一阶段文本预处理)比停用词移除和词干提取/词形还原(归类为第二阶段文本预处理)更有效。针对第二阶段文本预处理中出现的不良虚假映射,提出了两种新的修复方法。一种是基于特定本体检查的、在文本预处理之前使用的、临时的基于逻辑的修复方法,用于查找导致虚假映射的常用词。另一种是基于大型语言模型(LLM)的后验方法,在文本预处理之后使用,利用LLM提供的强大的背景知识来修复不存在的和违反直觉的虚假映射。实验结果表明,这两种方法可以显著提高匹配的正确性和整体匹配性能。
🔬 方法详解
问题定义:本体匹配任务旨在发现不同本体中语义上对应的实体。现有的文本预处理流程虽然被广泛应用,但由于缺乏统一标准,不同预处理策略导致匹配结果差异大,甚至引入错误的匹配。第二阶段的停用词移除和词干提取/词形还原操作,可能会过度简化文本,导致原本不应匹配的实体产生虚假匹配。
核心思路:论文的核心思路是针对文本预处理流程中引入的错误进行修复。具体而言,针对第二阶段预处理可能导致的虚假匹配,提出了两种互补的修复策略:一种是预处理前的基于本体逻辑的修复,另一种是预处理后的基于LLM的修复。这种思路旨在在不改变现有预处理流程的前提下,通过额外的修复步骤来提升匹配质量。
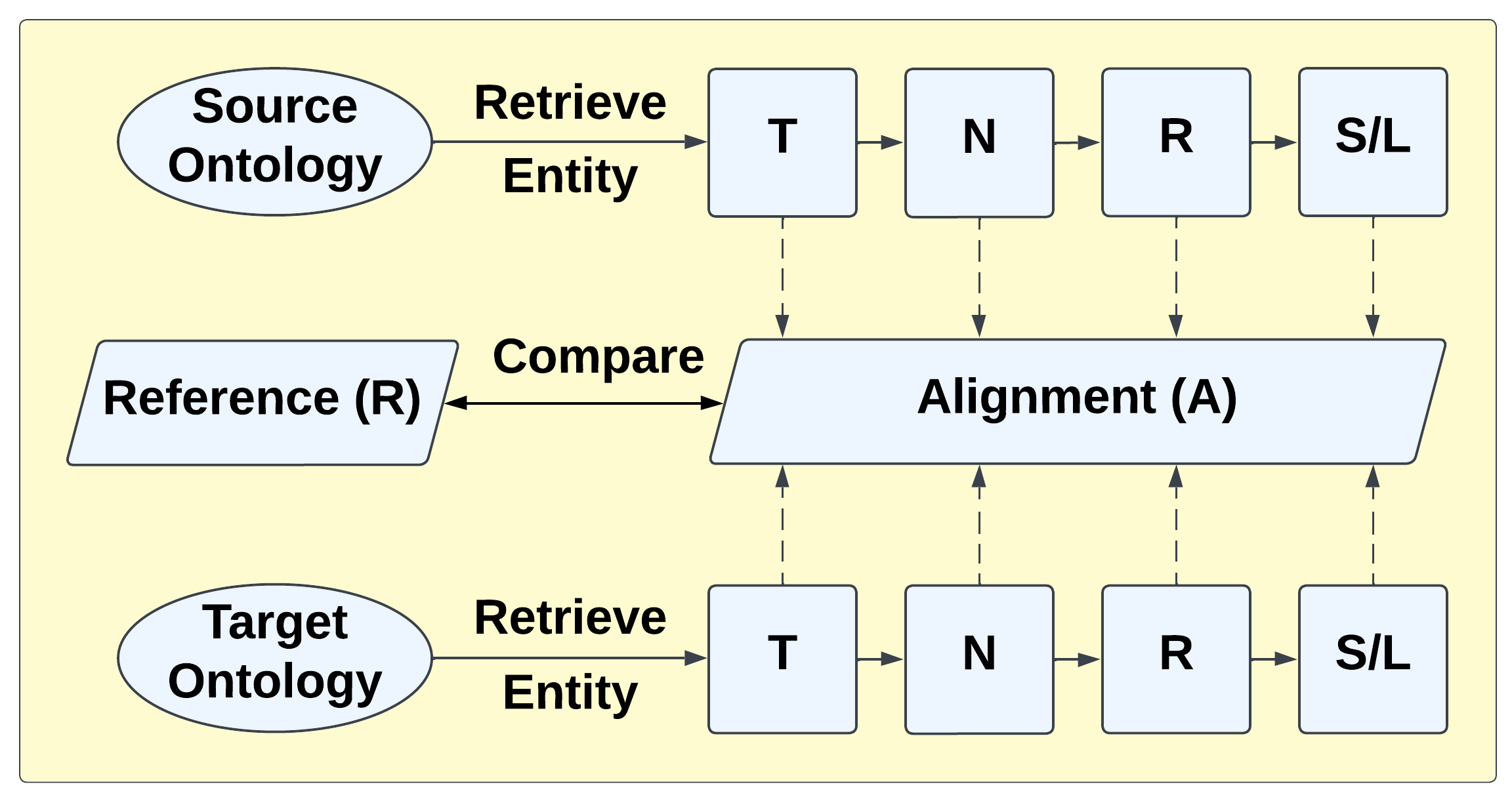
技术框架:整体框架包含标准的文本预处理流程(分词、归一化、停用词移除、词干提取/词形还原),以及两个修复模块。第一个修复模块是预处理前的逻辑修复,针对特定本体的常用词进行检查。第二个修复模块是预处理后的LLM修复,利用LLM的知识进行错误识别和修正。最终,将修复后的文本用于本体匹配。
关键创新:论文的关键创新在于提出了两种针对文本预处理引入错误的修复方法。预处理前的逻辑修复方法利用本体自身的知识,针对性地解决常用词导致的错误。预处理后的LLM修复方法则利用LLM的强大背景知识,能够识别和修正更复杂的、违反直觉的错误。这两种方法与现有的预处理流程兼容,可以灵活地应用于不同的本体匹配场景。
关键设计:预处理前的逻辑修复方法需要人工定义规则,识别可能导致虚假匹配的常用词。预处理后的LLM修复方法需要设计合适的prompt,引导LLM判断匹配的正确性。具体的prompt设计和LLM选择是影响修复效果的关键因素。论文中可能使用了特定的LLM和prompt工程技术,但具体细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的两种修复方法能够显著提高本体匹配的正确性和整体性能。具体性能数据未知,但摘要中强调了“显著提高”,表明该方法具有实际效果。该研究在8个OAEI track上进行了评估,涵盖了49个不同的对齐,验证了方法的泛化能力。
🎯 应用场景
该研究成果可应用于知识图谱构建、数据集成、语义搜索等领域。通过提高本体匹配的准确性,可以提升知识图谱的质量,促进不同数据源之间的互操作性,并改善语义搜索的精度。该方法具有广泛的应用前景,尤其是在需要处理大量文本数据的知识密集型应用中。
📄 摘要(原文)
The classical text preprocessing pipeline, comprising Tokenisation, Normalisation, Stop Words Removal, and Stemming/Lemmatisation, has been implemented in many systems for ontology matching (OM). However, the lack of standardisation in text preprocessing creates diversity in the mapping results. In this paper, we investigate the effect of the text preprocessing pipeline on 8 Ontology Alignment Evaluation Initiative (OAEI) tracks with 49 distinct alignments. We find that Tokenisation and Normalisation (categorised as Phase 1 text preprocessing) are more effective than Stop Words Removal and Stemming/Lemmatisation (categorised as Phase 2 text preprocessing). We propose two novel approaches to repair unwanted false mappings that occur in Phase 2 text preprocessing. One is an ad hoc logic-based repair approach used before text preprocessing, employing an ontology-specific check to find common words that cause false mappings. The other repair approach is the post hoc large language model (LLM)-based approach, used after text preprocessing, which utilises the strong background knowledge provided by LLMs to repair non-existent and counter-intuitive false mappings. The experimental results indicate that these two approaches can significantly improve the matching correctness and the overall matching performance.