Understanding the Effects of Human-written Paraphrases in LLM-generated Text Detection
作者: Hiu Ting Lau, Arkaitz Zubiaga
分类: cs.CL
发布日期: 2024-11-06
💡 一句话要点
提出HLPC数据集,研究人工释义对LLM生成文本检测的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM生成文本检测 人工释义 数据集构建 自然语言处理 文本分类
📋 核心要点
- 现有LLM生成文本检测器在区分机器和人工文本方面表现良好,但在面对释义文本时性能下降。
- 论文构建了包含人工和LLM释义的HLPC数据集,用于评估释义对检测器性能的影响。
- 实验表明,人工释义的加入显著影响了LLM生成文本检测器的性能,提高了TPR@1%FPR。
📝 摘要(中文)
随着大型语言模型(LLM)的出现,自然语言生成技术得到了迅速发展。虽然它们的使用引起了公众的广泛关注,但让读者意识到一段文本是否由LLM生成非常重要。这促使人们需要构建能够自动检测LLM生成文本的模型,以减轻此类内容可能带来的负面影响。现有的LLM生成文本检测器在区分LLM生成文本和人工撰写文本方面表现出较强的性能,但当考虑释义文本时,这种性能可能会下降。在本研究中,我们设计了一种新的数据收集策略,以收集人工和LLM释义集合(HLPC),这是一个首创的数据集,它结合了人工撰写的文本和释义,以及LLM生成的文本和释义。为了理解人工释义对最先进的LLM生成文本检测器OpenAI RoBERTa和水印检测器性能的影响,我们进行了分类实验,其中包含了人工撰写的释义、来自GPT和OPT的带水印和不带水印的LLM生成文档,以及来自DIPPER和BART的LLM生成的释义。结果表明,包含人工撰写的释义对LLM生成检测器的性能有显著影响,提高了TPR@1%FPR,但可能会牺牲AUROC和准确性。
🔬 方法详解
问题定义:论文旨在解决LLM生成文本检测器在面对人工释义文本时性能下降的问题。现有的检测器在区分原始LLM生成文本和人工撰写文本方面表现良好,但人工释义能够有效迷惑检测器,降低其准确性。因此,如何提高检测器在面对人工释义文本时的鲁棒性是本研究的核心问题。
核心思路:论文的核心思路是通过构建包含人工释义和LLM释义的大规模数据集HLPC,来评估和分析人工释义对现有LLM生成文本检测器性能的影响。通过实验,揭示人工释义对检测器性能的影响模式,为后续研究提供数据基础和实验依据。
技术框架:论文的技术框架主要包括以下几个步骤:1)构建HLPC数据集,该数据集包含人工撰写的文本和释义,以及LLM生成的文本和释义。2)选择OpenAI RoBERTa和水印检测器作为基线模型。3)进行分类实验,评估在包含人工释义、LLM生成文本和释义的不同组合下,基线模型的性能表现。4)分析实验结果,探讨人工释义对检测器性能的影响。
关键创新:论文的关键创新在于构建了首个包含人工和LLM释义的HLPC数据集。该数据集的构建为研究人工释义对LLM生成文本检测的影响提供了必要的数据基础。此外,论文还系统地评估了人工释义对现有检测器性能的影响,揭示了人工释义对检测器性能的复杂影响。
关键设计:HLPC数据集的关键设计在于同时包含人工撰写的文本和释义,以及LLM生成的文本和释义,从而能够全面评估人工释义对检测器性能的影响。实验中,使用了TPR@1%FPR、AUROC和准确率等指标来评估检测器的性能。使用了GPT、OPT、DIPPER和BART等多种LLM模型来生成文本和释义,以保证实验结果的泛化性。
🖼️ 关键图片


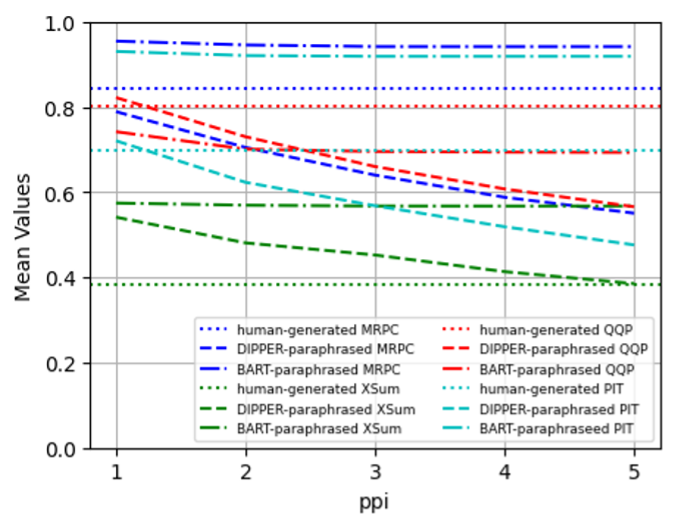
📊 实验亮点
实验结果表明,包含人工释义显著影响了LLM生成文本检测器的性能。具体而言,人工释义的加入提高了TPR@1%FPR,但可能会牺牲AUROC和准确性。这表明人工释义能够有效迷惑现有检测器,使其难以区分LLM生成文本和人工撰写文本。该研究结果为后续研究提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于内容审核、学术诚信检测、新闻真实性验证等领域。通过提高LLM生成文本检测器在面对人工释义文本时的鲁棒性,可以有效防止恶意用户利用LLM生成虚假信息或进行欺诈活动。未来,该研究可以进一步扩展到其他语言和领域,为构建更加安全可靠的网络环境做出贡献。
📄 摘要(原文)
Natural Language Generation has been rapidly developing with the advent of large language models (LLMs). While their usage has sparked significant attention from the general public, it is important for readers to be aware when a piece of text is LLM-generated. This has brought about the need for building models that enable automated LLM-generated text detection, with the aim of mitigating potential negative outcomes of such content. Existing LLM-generated detectors show competitive performances in telling apart LLM-generated and human-written text, but this performance is likely to deteriorate when paraphrased texts are considered. In this study, we devise a new data collection strategy to collect Human & LLM Paraphrase Collection (HLPC), a first-of-its-kind dataset that incorporates human-written texts and paraphrases, as well as LLM-generated texts and paraphrases. With the aim of understanding the effects of human-written paraphrases on the performance of state-of-the-art LLM-generated text detectors OpenAI RoBERTa and watermark detectors, we perform classification experiments that incorporate human-written paraphrases, watermarked and non-watermarked LLM-generated documents from GPT and OPT, and LLM-generated paraphrases from DIPPER and BART. The results show that the inclusion of human-written paraphrases has a significant impact of LLM-generated detector performance, promoting TPR@1%FPR with a possible trade-off of AUROC and accuracy.