The Root Shapes the Fruit: On the Persistence of Gender-Exclusive Harms in Aligned Language Models
作者: Anaelia Ovalle, Krunoslav Lehman Pavasovic, Louis Martin, Luke Zettlemoyer, Eric Michael Smith, Kai-Wei Chang, Adina Williams, Levent Sagun
分类: cs.CL
发布日期: 2024-11-06 (更新: 2025-05-12)
备注: Accepted to 2025 ACM FAccT
💡 一句话要点
揭示对齐语言模型中性别歧视的持续性:关注性别多样性群体的偏见放大问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型对齐 性别偏见 性别多样性 直接偏好优化 偏见评估 社会偏见 自然语言处理
📋 核心要点
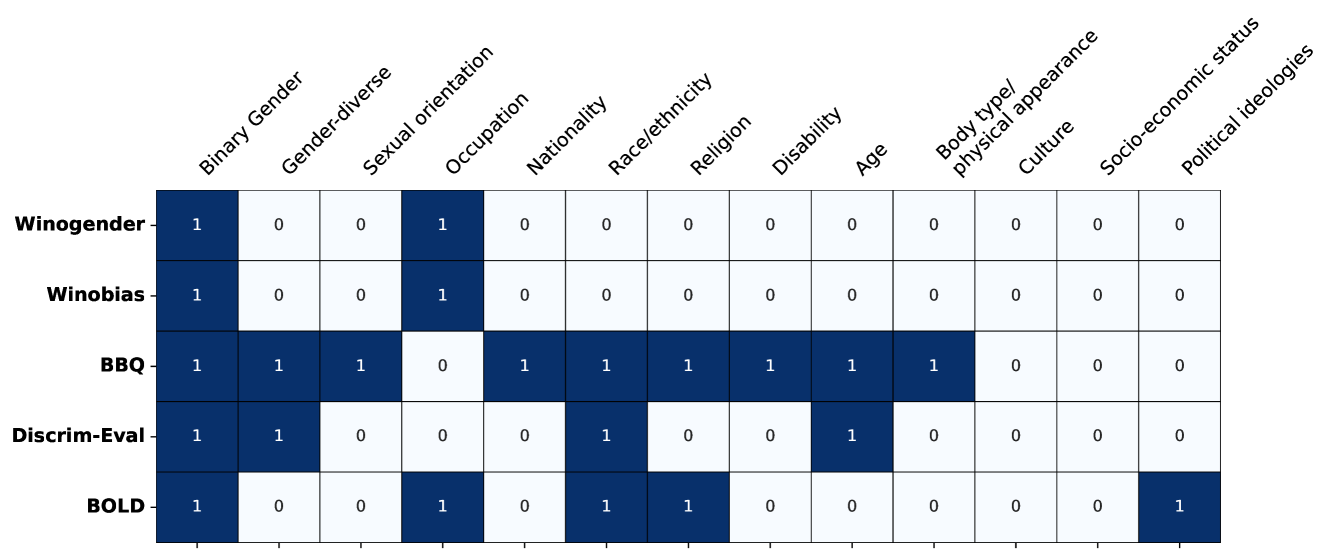
- 现有对齐方法在减轻语言模型偏见方面存在不足,尤其是在性别多样性群体方面,主流基准测试未能充分覆盖这些群体的偏见。
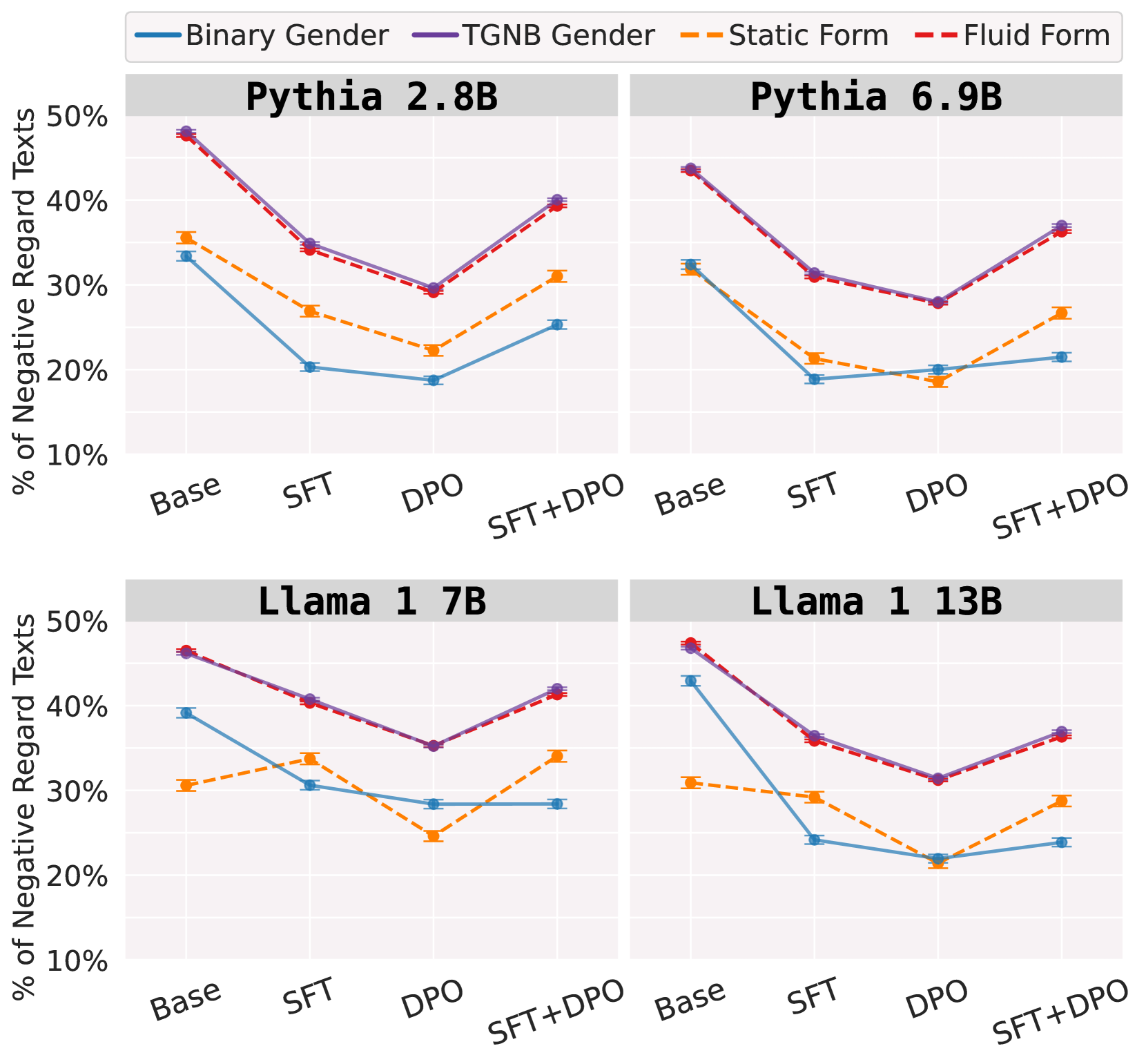
- 论文核心思想是系统评估DPO对齐模型中性别多样性偏见,并揭示其对SFT的敏感性,从而放大基础模型中固有的污名化和性别否定语言。
- 通过对16个DPO模型的评估,论文发现现有偏见基准未能检测到对性别多样性群体的危害,并提出了更有效的社区知情偏见评估框架。
📝 摘要(中文)
自然语言助手旨在提供有用的响应并避免有害的输出,这主要通过与人类偏好对齐来实现。然而,人们对对齐技术是否会无意中延续甚至放大从预对齐的基础模型中继承的有害偏见知之甚少。此外,流行的偏好微调模型中的偏见评估基准主要关注二元性别等主要社会类别,从而限制了对影响弱势群体偏见的洞察。为了解决这一差距,我们以跨性别者、非二元性别者和其他性别多样性身份为中心,来研究对齐程序如何与LLM中预先存在的性别多样性偏见相互作用。我们的主要贡献包括:1) 对领先的偏好微调LLM中的偏见评估方式进行了全面调查,突出了性别多样性代表性方面的关键差距;2) 对跨越直接偏好优化 (DPO) 阶段的 16 个模型进行了性别多样性偏见的系统评估,揭示了流行的偏见基准未能检测到的危害;3) 一个灵活的框架,用于衡量隐式奖励信号中的有害偏见,适用于其他社会背景。我们的研究结果表明,DPO 对齐模型对监督微调 (SFT) 特别敏感,并且可以放大来自其基础模型的两种现实世界中的性别多样性危害:污名化和性别非肯定语言。最后,我们提出了针对 DPO 和更广泛的对齐实践的建议,倡导采用社区知情的偏见评估框架,以更有效地识别和解决 LLM 中代表性不足的危害。
🔬 方法详解
问题定义:论文旨在解决现有语言模型对齐方法在处理性别多样性群体时存在的偏见问题。现有方法主要关注二元性别等主流社会类别,忽略了跨性别者、非二元性别者等群体面临的污名化和性别否定语言等问题。流行的偏见评估基准也未能充分检测到这些危害,导致对齐后的模型可能无意中延续甚至放大这些偏见。
核心思路:论文的核心思路是以性别多样性群体为中心,系统评估DPO对齐模型中存在的偏见。通过构建更全面的评估框架,揭示现有基准未能检测到的危害,并分析DPO对齐过程如何与基础模型中预先存在的偏见相互作用。论文特别关注DPO对齐模型对SFT的敏感性,以及由此可能导致的偏见放大效应。
技术框架:论文的技术框架主要包括三个部分:1) 对现有偏见评估方式进行全面调查,识别性别多样性代表性方面的差距;2) 对16个DPO模型进行系统评估,使用新的评估指标检测性别多样性偏见;3) 提出一个灵活的框架,用于衡量隐式奖励信号中的有害偏见。该框架可以应用于其他社会背景,以评估不同类型的偏见。
关键创新:论文最重要的技术创新点在于其对DPO对齐模型中性别多样性偏见的系统评估和分析。与现有研究主要关注二元性别偏见不同,论文将重点放在了跨性别者、非二元性别者等群体,并揭示了DPO对齐过程可能放大这些群体面临的污名化和性别否定语言等问题。此外,论文提出的灵活框架为衡量隐式奖励信号中的有害偏见提供了一种新的方法。
关键设计:论文的关键设计包括:1) 选择具有代表性的DPO模型进行评估;2) 构建能够有效检测性别多样性偏见的评估指标;3) 设计实验来分析DPO对齐过程对偏见的影响;4) 提出针对DPO和更广泛的对齐实践的建议,包括采用社区知情的偏见评估框架。
🖼️ 关键图片

📊 实验亮点
论文通过对16个DPO模型的评估,发现现有偏见基准未能检测到对性别多样性群体的危害。研究表明,DPO对齐模型对SFT特别敏感,可能放大基础模型中固有的污名化和性别否定语言。这些发现强调了采用更全面的偏见评估框架的重要性,以确保AI系统对所有用户都是公平和包容的。
🎯 应用场景
该研究成果可应用于改进自然语言助手和聊天机器人的设计,使其在处理性别多样性相关话题时更加敏感和包容。通过采用社区知情的偏见评估框架,可以更有效地识别和解决LLM中代表性不足的危害,从而减少对弱势群体的歧视和伤害。该研究还有助于提高公众对AI偏见的认识,促进负责任的AI开发和部署。
📄 摘要(原文)
Natural-language assistants are designed to provide users with helpful responses while avoiding harmful outputs, largely achieved through alignment to human preferences. Yet there is limited understanding of whether alignment techniques may inadvertently perpetuate or even amplify harmful biases inherited from their pre-aligned base models. This issue is compounded by the choice of bias evaluation benchmarks in popular preference-finetuned models, which predominantly focus on dominant social categories, such as binary gender, thereby limiting insights into biases affecting underrepresented groups. Towards addressing this gap, we center transgender, nonbinary, and other gender-diverse identities to investigate how alignment procedures interact with pre-existing gender-diverse bias in LLMs. Our key contributions include: 1) a comprehensive survey of bias evaluation modalities across leading preference-finetuned LLMs, highlighting critical gaps in gender-diverse representation, 2) systematic evaluation of gender-diverse biases across 16 models spanning Direct Preference Optimization (DPO) stages, uncovering harms popular bias benchmarks fail to detect, and 3) a flexible framework for measuring harmful biases in implicit reward signals applicable to other social contexts. Our findings reveal that DPO-aligned models are particularly sensitive to supervised finetuning (SFT), and can amplify two forms of real-world gender-diverse harms from their base models: stigmatization and gender non-affirmative language. We conclude with recommendations tailored to DPO and broader alignment practices, advocating for the adoption of community-informed bias evaluation frameworks to more effectively identify and address underrepresented harms in LLMs.