Usefulness of LLMs as an Author Checklist Assistant for Scientific Papers: NeurIPS'24 Experiment
作者: Alexander Goldberg, Ihsan Ullah, Thanh Gia Hieu Khuong, Benedictus Kent Rachmat, Zhen Xu, Isabelle Guyon, Nihar B. Shah
分类: cs.CL, cs.DL, cs.HC
发布日期: 2024-11-05 (更新: 2024-11-08)
💡 一句话要点
利用LLM作为作者自检助手提升科研论文质量:NeurIPS'24实验分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科研论文 自动检查 NeurIPS 作者自检
📋 核心要点
- 现有科研论文审核流程依赖人工,效率低且易受主观因素影响,缺乏自动化工具辅助作者自检。
- 利用LLM构建论文检查清单助手,自动评估论文是否符合会议规范,为作者提供反馈以改进论文质量。
- NeurIPS'24实验表明,该助手对作者自检有帮助,但同时也暴露了LLM的不准确和易被操纵等问题。
📝 摘要(中文)
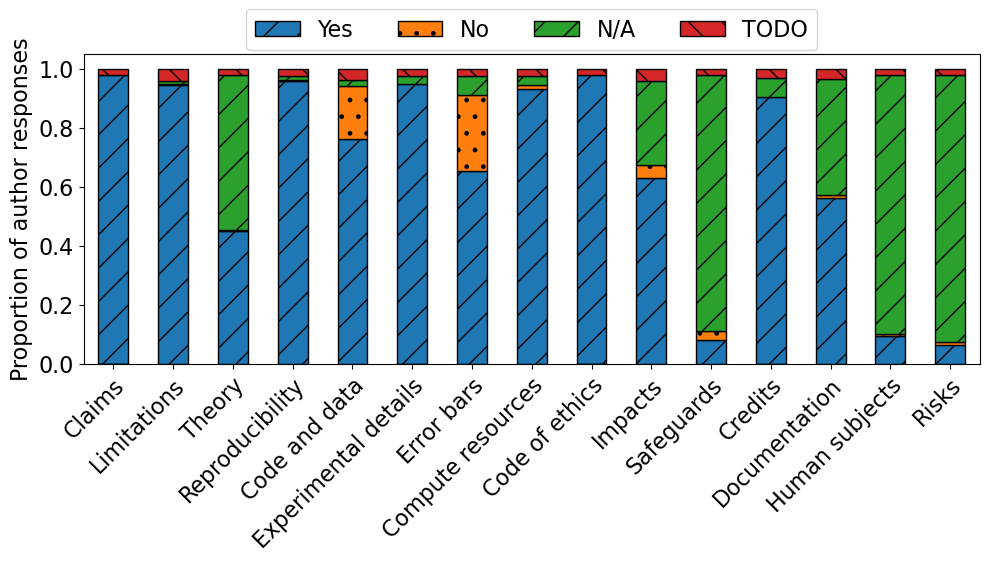
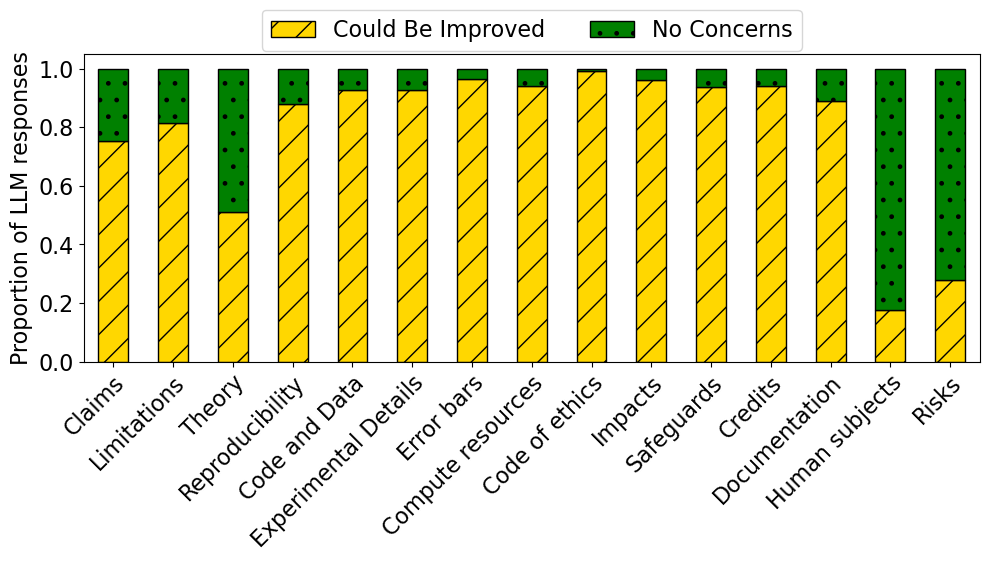
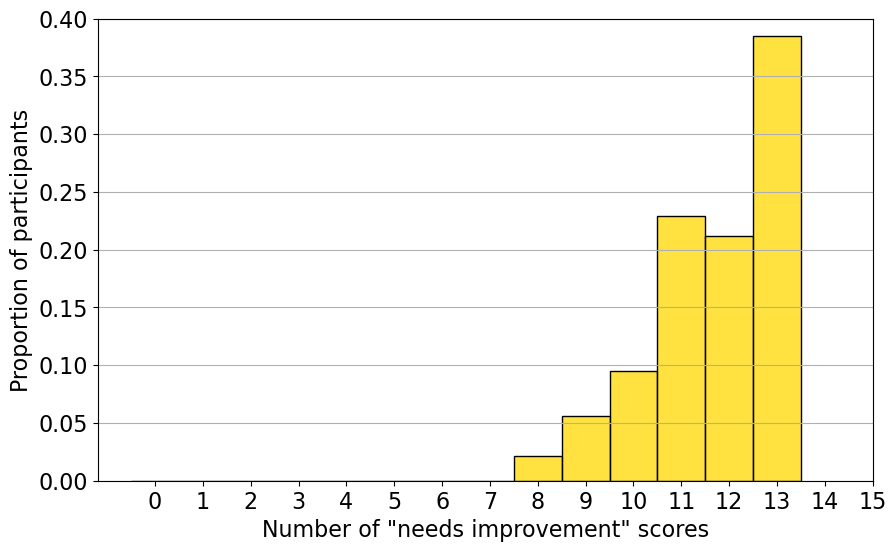
本研究评估了大型语言模型(LLM)在会议环境中作为论文提交标准检查工具的有效性。在2024年神经信息处理系统(NeurIPS)会议上,234篇论文自愿提交给“基于LLM的检查清单助手”。该助手验证论文是否符合NeurIPS使用的作者检查清单,包括确保符合研究和稿件准备标准的问题。NeurIPS论文作者对助手的评估表明,该助手在验证清单完成情况方面通常很有帮助。在使用后的调查中,超过70%的作者认为该助手有用,70%的作者表示他们会根据其反馈修改论文或检查清单回复。虽然无法明确地将因果关系归因于该助手,但定性证据表明,LLM有助于改进一些提交的论文。调查回复和重新提交的分析表明,作者根据LLM的具体反馈对提交的论文进行了实质性修改。该实验还强调了LLM的常见问题:不准确(20/52)和过度严格(14/52)是作者标记的最常见问题。我们还进行了实验,以了解潜在的系统博弈行为,结果表明,可以通过捏造理由来操纵助手以提高分数,突出了自动审查工具的潜在漏洞。
🔬 方法详解
问题定义:论文旨在解决科研论文撰写过程中,作者难以全面自检并确保符合会议或期刊投稿规范的问题。现有方法主要依赖作者自身经验或同事互审,效率低且容易遗漏关键信息,导致论文被拒稿的风险增高。因此,需要一种自动化的工具来辅助作者进行自检,提高论文的投稿成功率。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,构建一个自动化的论文检查清单助手。该助手能够根据会议或期刊的投稿规范,对论文进行自动评估,并向作者提供详细的反馈,帮助作者发现并纠正论文中存在的问题。
技术框架:该研究的技术框架主要包括以下几个模块:1) 数据收集与准备:收集NeurIPS会议的作者检查清单,并将其转化为LLM可以理解的格式。2) LLM模型构建:使用预训练的LLM,并针对论文检查任务进行微调。3) 论文评估:将作者提交的论文输入到LLM模型中,模型根据检查清单对论文进行评估,并生成评估报告。4) 结果反馈:将评估报告反馈给作者,作者根据报告修改论文。
关键创新:该研究的关键创新在于将LLM应用于科研论文的自动检查任务,并构建了一个实用的论文检查清单助手。与传统的人工检查方法相比,该助手具有效率高、成本低、可扩展性强等优点。此外,该研究还对LLM在论文检查任务中的潜在问题进行了深入分析,例如LLM的不准确性和易被操纵性。
关键设计:在LLM模型构建方面,研究者使用了预训练的LLM,并针对NeurIPS的作者检查清单进行了微调。具体来说,研究者将检查清单中的每个问题都转化为一个分类任务,并使用交叉熵损失函数对LLM进行训练。此外,研究者还设计了一些对抗性样本,用于评估LLM的鲁棒性。
🖼️ 关键图片
📊 实验亮点
NeurIPS'24实验结果表明,超过70%的作者认为LLM助手有用,并表示会根据反馈修改论文。作者的重新提交分析显示,他们根据LLM的反馈进行了实质性修改。然而,实验也揭示了LLM的局限性,如20/52的案例中存在不准确,14/52的案例中存在过度严格的问题。此外,研究还发现该系统存在被操纵的风险。
🎯 应用场景
该研究成果可应用于科研论文写作辅助、投稿前自检、学术规范审核等领域。通过自动化检查清单,能显著提高论文质量和投稿成功率,节省审稿人时间,并有助于规范学术行为。未来可扩展到其他学术领域,甚至应用于专利申请等场景。
📄 摘要(原文)
Large language models (LLMs) represent a promising, but controversial, tool in aiding scientific peer review. This study evaluates the usefulness of LLMs in a conference setting as a tool for vetting paper submissions against submission standards. We conduct an experiment at the 2024 Neural Information Processing Systems (NeurIPS) conference, where 234 papers were voluntarily submitted to an "LLM-based Checklist Assistant." This assistant validates whether papers adhere to the author checklist used by NeurIPS, which includes questions to ensure compliance with research and manuscript preparation standards. Evaluation of the assistant by NeurIPS paper authors suggests that the LLM-based assistant was generally helpful in verifying checklist completion. In post-usage surveys, over 70% of authors found the assistant useful, and 70% indicate that they would revise their papers or checklist responses based on its feedback. While causal attribution to the assistant is not definitive, qualitative evidence suggests that the LLM contributed to improving some submissions. Survey responses and analysis of re-submissions indicate that authors made substantive revisions to their submissions in response to specific feedback from the LLM. The experiment also highlights common issues with LLMs: inaccuracy (20/52) and excessive strictness (14/52) were the most frequent issues flagged by authors. We also conduct experiments to understand potential gaming of the system, which reveal that the assistant could be manipulated to enhance scores through fabricated justifications, highlighting potential vulnerabilities of automated review tools.