TokenSelect: Efficient Long-Context Inference and Length Extrapolation for LLMs via Dynamic Token-Level KV Cache Selection
作者: Wei Wu, Zhuoshi Pan, Chao Wang, Liyi Chen, Yunchu Bai, Tianfu Wang, Kun Fu, Zheng Wang, Hui Xiong
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-05 (更新: 2025-10-09)
备注: Accepted by EMNLP2025
💡 一句话要点
TokenSelect:通过动态Token级KV缓存选择实现LLM的高效长上下文推理和长度外推
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文推理 KV缓存选择 注意力机制 大型语言模型 推理加速
📋 核心要点
- 现有LLM在长上下文推理中面临性能下降和推理时间过长的问题,主要原因是注意力机制的二次复杂度。
- TokenSelect通过动态选择关键的KV缓存token参与注意力计算,减少计算量,同时保持准确性。
- 实验表明,TokenSelect在注意力计算速度和端到端延迟方面均有显著提升,且性能优于现有方法。
📝 摘要(中文)
大型语言模型(LLM)的快速发展推动了对处理扩展上下文序列的需求。然而,这一进展面临两个挑战:由于序列长度超出分布范围导致的性能下降,以及由注意力机制的二次计算复杂度引起的过长推理时间。这些问题限制了LLM在长上下文场景中的应用。本文提出了一种动态Token级KV缓存选择(TokenSelect)方法,这是一种无需训练的方法,用于高效且准确的长上下文推理。TokenSelect建立在非连续注意力稀疏性的观察之上,使用QK点积来衡量每个head的KV缓存token的重要性。通过每个head的软投票机制,TokenSelect选择性地将少量关键KV缓存token纳入注意力计算,而不会牺牲准确性。为了进一步加速TokenSelect,我们基于连续Query相似性的观察设计了Selection Cache,并实现了高效的分页点积内核,显著降低了选择开销。对TokenSelect的全面评估表明,注意力计算速度提高了高达23.84倍,端到端延迟加速了高达2.28倍,同时提供了优于最先进的长上下文推理方法的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长上下文推理中面临的效率瓶颈问题。现有方法由于注意力机制的二次复杂度,导致推理时间过长,并且在处理超出训练分布的序列长度时性能下降。因此,如何在保证模型性能的前提下,加速长上下文推理是本文要解决的核心问题。
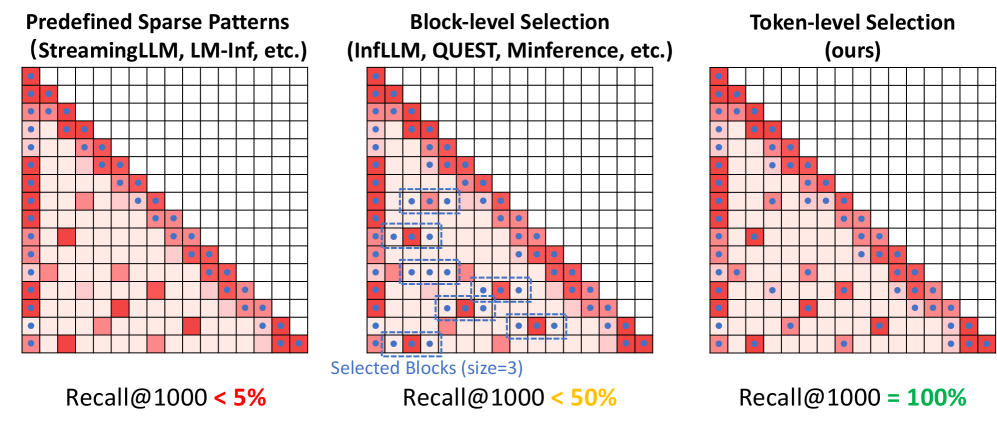
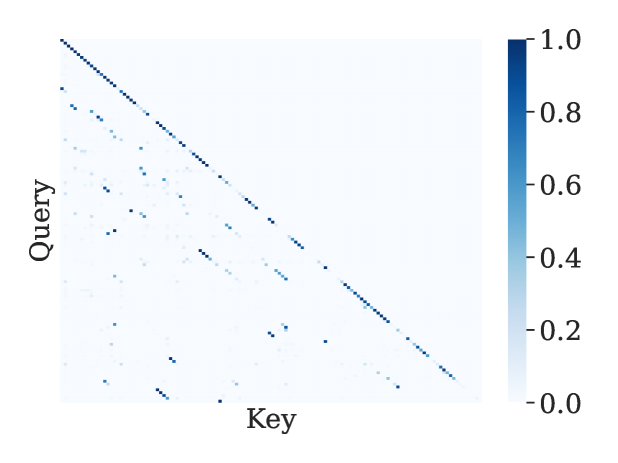
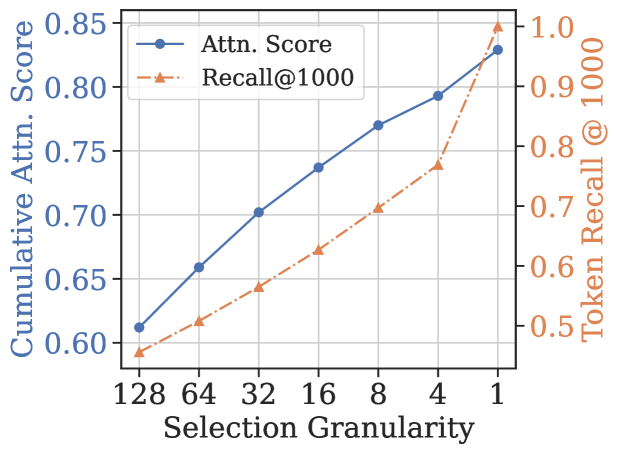
核心思路:TokenSelect的核心思路是动态地选择对当前推理至关重要的KV缓存token,而不是使用全部的KV缓存。通过减少参与注意力计算的token数量,从而降低计算复杂度,加速推理过程。这种选择是基于token级别的,并且是动态的,能够适应不同的输入序列。
技术框架:TokenSelect主要包含以下几个阶段:1) 使用QK点积计算每个token的KV缓存重要性;2) 通过每个head的软投票机制,选择关键的KV缓存token;3) 使用选择后的KV缓存进行注意力计算;4) 为了加速选择过程,引入Selection Cache,利用连续Query的相似性,缓存选择结果;5) 使用高效的分页点积内核,优化点积计算。
关键创新:TokenSelect的关键创新在于动态token级别的KV缓存选择机制。与现有方法不同,TokenSelect不是静态地选择或压缩KV缓存,而是根据每个token的重要性动态地进行选择。此外,Selection Cache和分页点积内核的设计进一步加速了选择和计算过程。
关键设计:TokenSelect的关键设计包括:1) 使用QK点积作为衡量KV缓存重要性的指标;2) 软投票机制,允许每个head对token的重要性进行投票,从而实现更精细的选择;3) Selection Cache,利用连续Query的相似性,缓存选择结果,避免重复计算;4) 分页点积内核,优化点积计算,提高计算效率。具体的参数设置和损失函数在论文中未明确提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
TokenSelect在长上下文推理任务中表现出色,实验结果表明,在注意力计算方面,TokenSelect实现了高达23.84倍的加速;在端到端延迟方面,实现了高达2.28倍的加速。同时,TokenSelect在性能上优于现有的长上下文推理方法,证明了其有效性和优越性。这些结果表明,TokenSelect是一种高效且准确的长上下文推理方法。
🎯 应用场景
TokenSelect具有广泛的应用前景,可以应用于需要处理长文本的各种场景,例如:长篇文档摘要、机器翻译、代码生成、对话系统等。通过加速长上下文推理,TokenSelect可以降低计算成本,提高用户体验,并推动LLM在更多实际应用中的部署。该研究的未来影响在于,它为解决LLM长上下文推理的效率问题提供了一种新的思路,并可能促进相关技术的进一步发展。
📄 摘要(原文)
Rapid advances in Large Language Models (LLMs) have spurred demand for processing extended context sequences in contemporary applications. However, this progress faces two challenges: performance degradation due to sequence lengths out-of-distribution, and excessively long inference times caused by the quadratic computational complexity of attention. These issues limit LLMs in long-context scenarios. In this paper, we propose Dynamic Token-Level KV Cache Selection (TokenSelect), a training-free method for efficient and accurate long-context inference. TokenSelect builds upon the observation of non-contiguous attention sparsity, using QK dot products to measure per-head KV Cache criticality at token-level. By per-head soft voting mechanism, TokenSelect selectively involves a few critical KV cache tokens in attention calculation without sacrificing accuracy. To further accelerate TokenSelect, we design the Selection Cache based on observations of consecutive Query similarity and implemented the efficient Paged Dot Product Kernel, significantly reducing the selection overhead. A comprehensive evaluation of TokenSelect demonstrates up to $23.84\times$ speedup in attention computation and up to $2.28\times$ acceleration in end-to-end latency, while providing superior performance compared to state-of-the-art long-context inference methods.