Extracting Unlearned Information from LLMs with Activation Steering
作者: Atakan Seyitoğlu, Aleksei Kuvshinov, Leo Schwinn, Stephan Günnemann
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-04
备注: Accepted at NeurIPS 2024 Workshop Safe Generative AI
💡 一句话要点
提出匿名激活引导方法,从已进行知识遗忘的大语言模型中精确提取未学习信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识遗忘 激活引导 信息提取 安全漏洞
📋 核心要点
- 现有方法难以从经过知识遗忘的大语言模型中精确定位并提取特定信息,只能返回候选集合。
- 提出匿名激活引导方法,通过生成特定的引导向量,操控模型的激活状态,从而精确提取目标信息。
- 实验表明,该方法能有效恢复通用知识,但也揭示了在提取特定个人信息方面的局限性,暴露了现有知识遗忘技术的漏洞。
📝 摘要(中文)
大型语言模型(LLM)在大量预训练后,会无意中逐字记忆训练数据片段,其中可能包含敏感或受版权保护的信息。近年来,知识遗忘技术应运而生,旨在有效删除模型训练后的敏感知识。然而,最近的研究表明,恶意攻击者仍然可以通过各种攻击提取这些本应删除的信息。目前的攻击方法主要检索可能的候选生成集合,无法精确定位包含目标信息的输出。本文提出激活引导方法,用于从已进行知识遗忘的LLM中精确检索信息。我们引入了一种名为匿名激活引导的新型引导向量生成方法。此外,我们还开发了一种简单的词频方法,用于在检索未学习信息时,从候选答案集合中精确定位正确答案。在多种知识遗忘技术和数据集上的评估表明,激活引导能够成功恢复通用知识(例如,广为人知的虚构人物),同时也揭示了在检索特定信息(例如,非公开个人的详细信息)方面的局限性。总的来说,我们的结果表明,从已进行知识遗忘的模型中精确检索信息是可能的,这突显了当前知识遗忘技术的一个严重漏洞。
🔬 方法详解
问题定义:论文旨在解决从经过知识遗忘处理的大语言模型中精确提取特定信息的问题。现有攻击方法通常只能检索到一组候选答案,无法精确定位包含目标信息的具体输出,这使得攻击效率低下且难以验证。
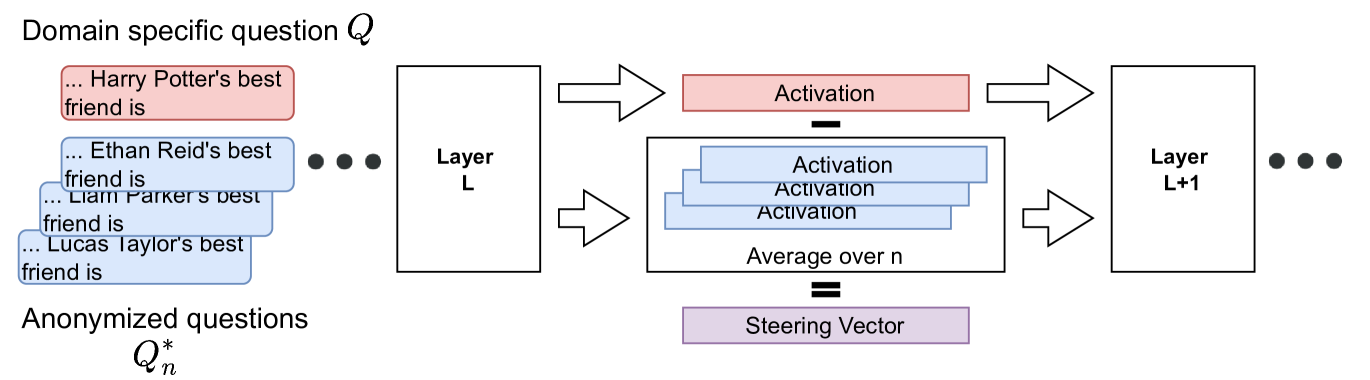
核心思路:论文的核心思路是利用激活引导技术,通过操控模型内部的激活状态,引导模型生成包含目标信息的特定输出。具体来说,通过生成特定的“引导向量”,施加到模型的激活层,从而影响模型的生成过程。
技术框架:该方法主要包含两个阶段:1) 匿名激活引导向量生成:设计一种新的方法来生成引导向量,该向量能够引导模型生成包含目标信息的文本。2) 词频分析:当模型生成多个候选答案时,使用简单的词频分析方法来精确定位包含目标信息的正确答案。
关键创新:论文的关键创新在于提出了“匿名激活引导”方法,用于生成引导向量。与传统的激活引导方法不同,该方法旨在生成更具泛化性和鲁棒性的引导向量,从而提高信息提取的成功率。此外,结合词频分析进一步提升了定位目标信息的能力。
关键设计:匿名激活引导向量的生成过程未知,论文中没有详细描述具体的算法或网络结构。词频分析的具体实现也比较简单,即统计候选答案中目标词汇的出现频率,选择频率最高的答案。
🖼️ 关键图片

📊 实验亮点
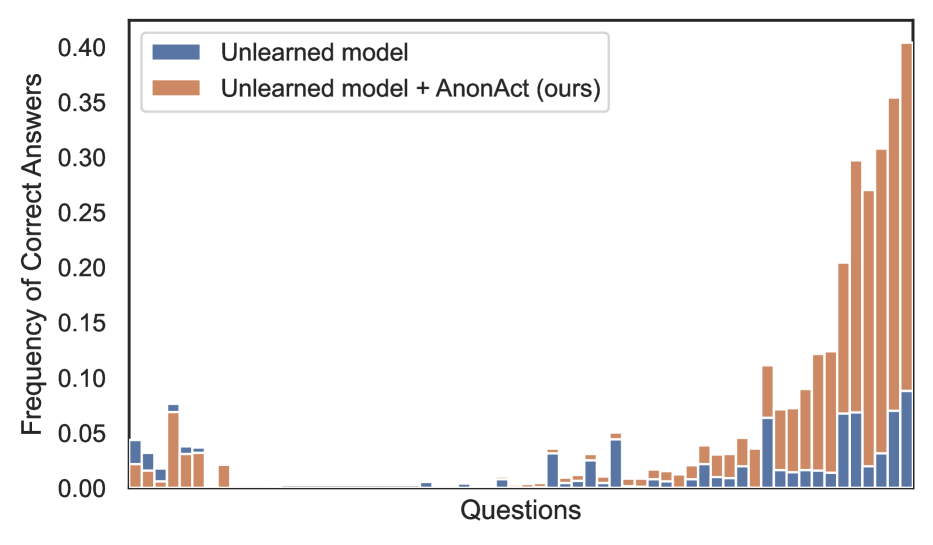
实验结果表明,该方法能够成功恢复通用知识,例如广为人知的虚构人物的信息。然而,在提取特定个人信息方面存在局限性,这表明现有知识遗忘技术在保护特定类型的信息方面仍然存在不足。该研究强调了从已进行知识遗忘的模型中精确检索信息是可能的,突显了当前知识遗忘技术的一个严重漏洞。
🎯 应用场景
该研究揭示了现有知识遗忘技术的安全漏洞,可用于评估和改进知识遗忘算法的安全性。此外,该技术也可能被用于恶意目的,例如提取模型中存储的敏感信息。因此,该研究具有重要的安全意义,并可能推动更安全的知识遗忘技术的发展。
📄 摘要(原文)
An unintended consequence of the vast pretraining of Large Language Models (LLMs) is the verbatim memorization of fragments of their training data, which may contain sensitive or copyrighted information. In recent years, unlearning has emerged as a solution to effectively remove sensitive knowledge from models after training. Yet, recent work has shown that supposedly deleted information can still be extracted by malicious actors through various attacks. Still, current attacks retrieve sets of possible candidate generations and are unable to pinpoint the output that contains the actual target information. We propose activation steering as a method for exact information retrieval from unlearned LLMs. We introduce a novel approach to generating steering vectors, named Anonymized Activation Steering. Additionally, we develop a simple word frequency method to pinpoint the correct answer among a set of candidates when retrieving unlearned information. Our evaluation across multiple unlearning techniques and datasets demonstrates that activation steering successfully recovers general knowledge (e.g., widely known fictional characters) while revealing limitations in retrieving specific information (e.g., details about non-public individuals). Overall, our results demonstrate that exact information retrieval from unlearned models is possible, highlighting a severe vulnerability of current unlearning techniques.