WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning
作者: Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, Yuxiao Dong
分类: cs.CL
发布日期: 2024-11-04 (更新: 2025-01-27)
备注: Published as a conference paper at ICLR 2025
💡 一句话要点
WebRL:通过自进化在线课程强化学习训练LLM Web代理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Web代理 强化学习 自进化课程学习 开源LLM 奖励模型 在线学习 自主代理
📋 核心要点
- 现有LLM Web代理依赖昂贵的专有API,开源LLM决策能力不足,限制了其广泛应用。
- WebRL提出自进化在线课程强化学习框架,通过自生成任务、鲁棒奖励模型和自适应学习策略,提升开源LLM的Web代理能力。
- 实验表明,WebRL显著提升Llama-3.1和GLM-4在WebArena-Lite上的成功率,超越GPT-4-Turbo和GPT-4o等专有模型。
📝 摘要(中文)
大型语言模型(LLM)在作为自主代理方面展现出卓越潜力,尤其是在基于Web的任务中。然而,现有的LLM Web代理严重依赖昂贵的专有LLM API,而开源LLM缺乏必要的决策能力。本文介绍了WebRL,一个自进化在线课程强化学习框架,旨在利用开源LLM训练高性能Web代理。WebRL解决了构建LLM Web代理的三个关键挑战,包括训练任务的稀缺性、稀疏的反馈信号以及在线学习中的策略分布漂移。具体来说,WebRL包含1)一个从不成功的尝试中生成新任务的自进化课程,2)一个鲁棒的结果监督奖励模型(ORM),以及3)自适应强化学习策略,以确保持续改进。我们应用WebRL将开源Llama-3.1和GLM-4模型转化为精通的Web代理。在WebArena-Lite上,WebRL将Llama-3.1-8B的成功率从4.8%提高到42.4%,将GLM-4-9B的成功率从6.1%提高到43%。这些开源模型显著超越了GPT-4-Turbo(17.6%)和GPT-4o(13.9%)的性能,并且优于先前在开源LLM上训练的最先进的Web代理(AutoWebGLM,18.2%)。我们的研究结果表明WebRL在弥合开源和专有LLM Web代理之间的差距方面的有效性,为更易于访问和更强大的自主Web交互系统铺平了道路。
🔬 方法详解
问题定义:现有LLM Web代理主要依赖于昂贵的闭源API,而开源LLM在Web任务中的决策能力不足。这限制了LLM Web代理的广泛应用和可访问性。现有方法在训练数据稀缺、反馈信号稀疏以及在线学习中的策略漂移等方面存在挑战。
核心思路:WebRL的核心思路是通过自进化在线课程强化学习,利用开源LLM自身的能力来生成更多样化的训练任务,并设计鲁棒的奖励模型来克服反馈稀疏的问题。同时,采用自适应强化学习策略来稳定训练过程,避免策略漂移。这样可以有效地提升开源LLM在Web任务中的决策能力。
技术框架:WebRL的整体框架包含三个主要模块:1) 自进化课程生成器:从失败的尝试中挖掘并生成新的训练任务,增加训练数据的多样性。2) 结果监督奖励模型(ORM):利用任务结果来训练奖励模型,提供更准确和鲁棒的反馈信号。3) 自适应强化学习:根据训练状态动态调整强化学习策略,以稳定训练过程并避免策略漂移。
关键创新:WebRL的关键创新在于其自进化课程生成器,它能够从模型自身的错误中学习,并生成更有挑战性的任务,从而实现持续的自我提升。此外,ORM的使用也显著提高了奖励信号的质量,使得模型能够更快地学习到有效的策略。
关键设计:自进化课程生成器通过分析失败轨迹,识别关键的错误步骤,并基于这些错误步骤生成新的任务。ORM使用监督学习方法,利用任务结果(例如成功或失败)来训练奖励模型。自适应强化学习则根据策略的熵和奖励的方差等指标,动态调整学习率和探索率等参数。
🖼️ 关键图片

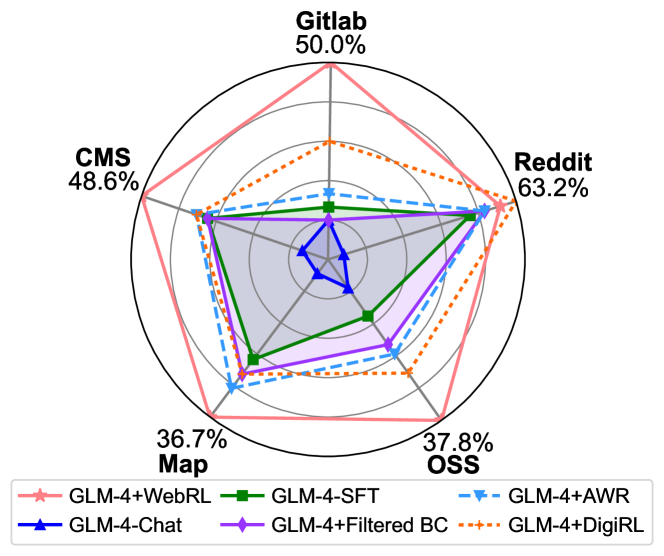
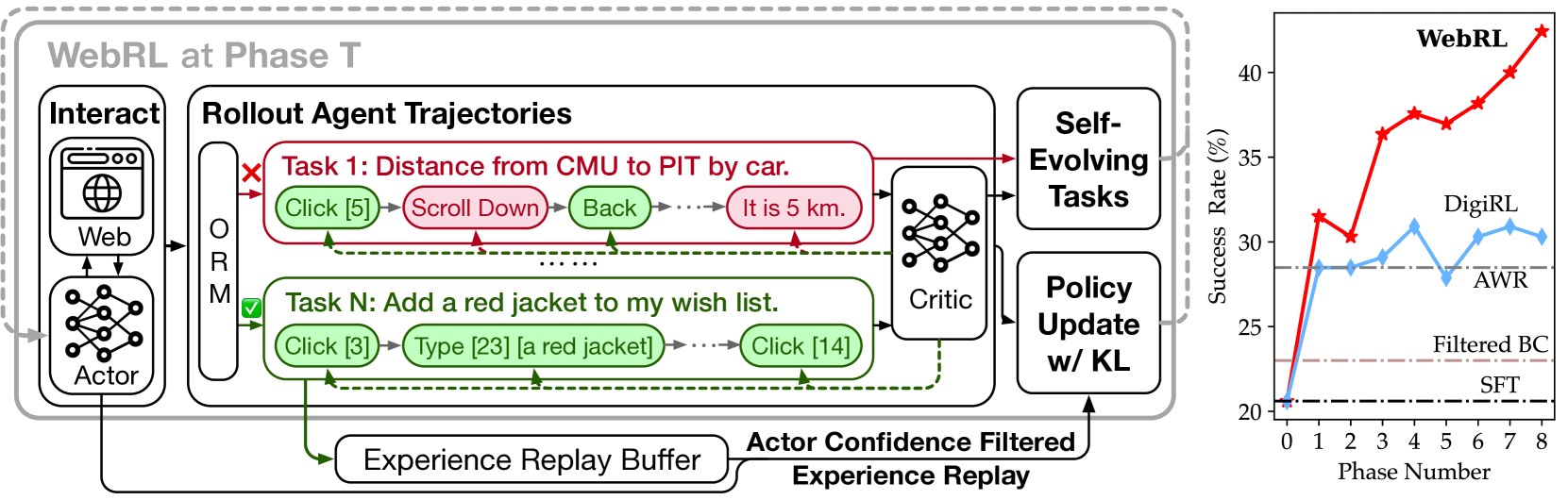
📊 实验亮点
WebRL显著提升了开源LLM在WebArena-Lite上的性能。Llama-3.1-8B的成功率从4.8%提高到42.4%,GLM-4-9B的成功率从6.1%提高到43%。这些开源模型超越了GPT-4-Turbo(17.6%)和GPT-4o(13.9%),并优于先前的SOTA开源Web代理AutoWebGLM(18.2%)。
🎯 应用场景
WebRL的研究成果可应用于开发更易于访问和更强大的自主Web交互系统,例如智能助手、自动化测试工具和信息检索系统。通过降低对昂贵专有API的依赖,WebRL有望推动开源LLM在Web应用领域的广泛应用,并促进相关技术的创新。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable potential as autonomous agents, particularly in web-based tasks. However, existing LLM web agents heavily rely on expensive proprietary LLM APIs, while open LLMs lack the necessary decision-making capabilities. This paper introduces WebRL, a self-evolving online curriculum reinforcement learning framework designed to train high-performance web agents using open LLMs. WebRL addresses three key challenges in building LLM web agents, including the scarcity of training tasks, sparse feedback signals, and policy distribution drift in online learning. Specifically, WebRL incorporates 1) a self-evolving curriculum that generates new tasks from unsuccessful attempts, 2) a robust outcome-supervised reward model (ORM), and 3) adaptive reinforcement learning strategies to ensure consistent improvements. We apply WebRL to transform open Llama-3.1 and GLM-4 models into proficient web agents. On WebArena-Lite, WebRL improves the success rate of Llama-3.1-8B from 4.8% to 42.4%, and from 6.1% to 43% for GLM-4-9B. These open models significantly surpass the performance of GPT-4-Turbo (17.6%) and GPT-4o (13.9%) and outperform previous state-of-the-art web agents trained on open LLMs (AutoWebGLM, 18.2%). Our findings demonstrate WebRL's effectiveness in bridging the gap between open and proprietary LLM-based web agents, paving the way for more accessible and powerful autonomous web interaction systems.