Evaluating Creative Short Story Generation in Humans and Large Language Models
作者: Mete Ismayilzada, Claire Stevenson, Lonneke van der Plas
分类: cs.CL, cs.AI
发布日期: 2024-11-04 (更新: 2025-05-10)
备注: Accepted to ICCC 2025
💡 一句话要点
系统分析人类与大型语言模型的短篇故事创作能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 创造力评估 短篇故事生成 大型语言模型 人类与AI比较 自动化评估
📋 核心要点
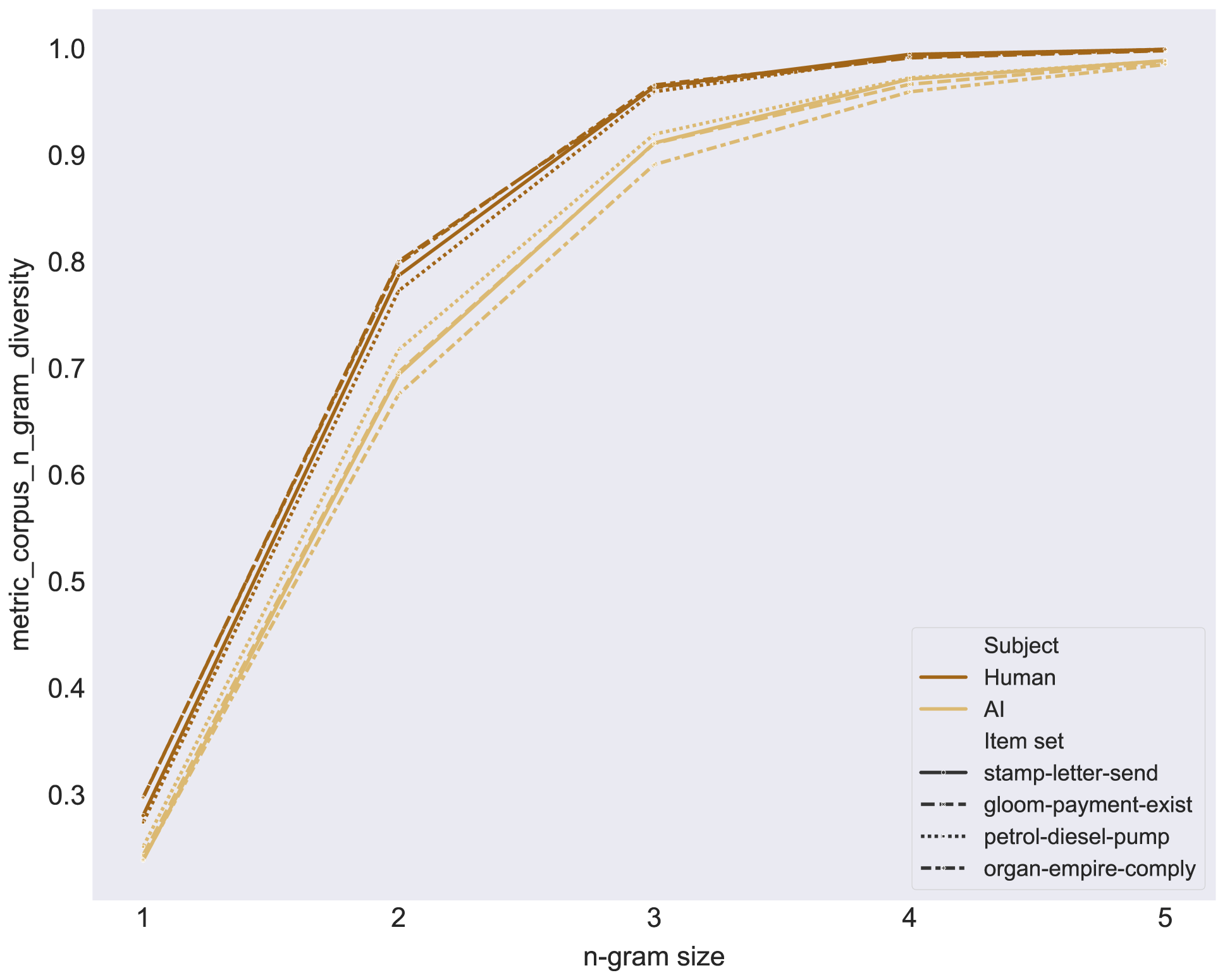
- 现有研究对大型语言模型的创造性故事创作能力探讨不足,尤其是在新颖性和多样性方面的表现较差。
- 本研究通过系统分析60个LLMs与60名人类的短篇故事创作,采用五句提示词任务和多维度评估指标。
- 实验结果表明,LLMs在风格复杂性上表现突出,但在创造性方面普遍低于人类作家,且专家与非专家的评分存在差异。
📝 摘要(中文)
故事创作是人类想象力的基本表现,依赖于创造力来生成新颖、有效且令人惊讶的叙事。尽管大型语言模型(LLMs)已展现出生成高质量故事的能力,但其创造性故事创作能力仍未得到充分探索。本研究对60个LLMs和60名人类在五句提示词基础上的短篇故事创作任务中进行系统分析。我们采用多维度的自动评估指标来评估模型和人类生成的故事,包括新颖性、惊讶性、多样性和语言复杂性。同时,我们收集了非专家和专家评审者以及LLMs的创造力评分和图灵测试分类。自动化指标显示,LLMs生成的故事在风格上复杂,但在新颖性、惊讶性和多样性方面普遍不及普通人类作家。专家评分与自动化指标大致一致,但LLMs和非专家认为LLMs的故事比人类生成的故事更具创造性。我们讨论了这些评分差异的原因及其对人类与人工创造力的影响。
🔬 方法详解
问题定义:本研究旨在评估大型语言模型在短篇故事创作中的创造力,尤其是与人类作家的比较。现有方法未能充分探讨LLMs在新颖性、惊讶性和多样性方面的表现。
核心思路:通过设计一个基于五句提示词的创作任务,系统分析人类与LLMs生成故事的创造力,采用自动化评估和人类评分相结合的方法。
技术框架:研究分为几个主要模块:首先是故事生成模块,分别由60个LLMs和60名人类作家参与;其次是自动化评估模块,使用多维度指标评估生成故事的质量;最后是人类评分模块,收集专家和非专家对故事的创造力评分。
关键创新:本研究的创新在于系统性地比较人类与LLMs在创造性故事创作中的表现,尤其是通过多维度的自动化评估与人类评分相结合,揭示了LLMs在创造力方面的不足。
关键设计:在评估过程中,采用了新颖性、惊讶性、多样性和语言复杂性等多个维度的自动化指标,同时结合专家和非专家的评分,以确保评估的全面性和准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,LLMs在风格复杂性上表现优异,但在新颖性、惊讶性和多样性方面普遍低于普通人类作家。专家评分与自动化指标一致,而LLMs和非专家则认为LLMs生成的故事更具创造性,这表明对创造力的评估存在主观差异。
🎯 应用场景
该研究的潜在应用领域包括教育、娱乐和创意产业,尤其是在自动化内容生成和人机协作创作方面。通过深入理解人类与LLMs的创造力差异,可以为未来的创作工具设计提供指导,促进人类与人工智能的协同创新。
📄 摘要(原文)
Story-writing is a fundamental aspect of human imagination, relying heavily on creativity to produce narratives that are novel, effective, and surprising. While large language models (LLMs) have demonstrated the ability to generate high-quality stories, their creative story-writing capabilities remain under-explored. In this work, we conduct a systematic analysis of creativity in short story generation across 60 LLMs and 60 people using a five-sentence cue-word-based creative story-writing task. We use measures to automatically evaluate model- and human-generated stories across several dimensions of creativity, including novelty, surprise, diversity, and linguistic complexity. We also collect creativity ratings and Turing Test classifications from non-expert and expert human raters and LLMs. Automated metrics show that LLMs generate stylistically complex stories, but tend to fall short in terms of novelty, surprise and diversity when compared to average human writers. Expert ratings generally coincide with automated metrics. However, LLMs and non-experts rate LLM stories to be more creative than human-generated stories. We discuss why and how these differences in ratings occur, and their implications for both human and artificial creativity.