Enhancing LLM Evaluations: The Garbling Trick
作者: William F. Bradley
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-03 (更新: 2025-05-18)
备注: 15 pages, 4 figures
💡 一句话要点
提出Garbling Trick,增强LLM评估难度,区分模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 推理能力 Garbling Trick 模型性能比较 多项选择题 难度增强 基准测试 模型选择
📋 核心要点
- 传统LLM评估指标饱和,难以区分模型性能,尤其是在推理能力方面。
- 提出Garbling Trick,通过转换现有评估为更难任务,突出模型推理差异。
- 创建新的多项选择测试集,并评估多个LLM,揭示模型间的性能差异。
📝 摘要(中文)
随着大型语言模型(LLM)变得越来越强大,传统的评估指标趋于饱和,使得区分模型之间的性能变得具有挑战性。我们提出了一种通用方法,将现有的LLM评估转化为一系列难度逐渐增加的任务。这些增强的评估强调推理能力,并且可以揭示在原始评估中不明显的相对性能差异。为了证明我们方法的有效性,我们创建了一个新的多项选择测试语料库,将其扩展为一个评估系列,并评估了一系列LLM。我们的结果提供了对这些模型相对能力的见解,特别突出了基础LLM和更新的“推理”模型之间的差异。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)评估中存在的区分度不足的问题。随着LLM能力的提升,传统评估指标逐渐饱和,难以有效区分不同模型,尤其是在考察深层推理能力时。现有评估方法的痛点在于无法充分挖掘模型的潜在能力,导致评估结果趋同,无法准确反映模型间的真实差距。
核心思路:论文的核心思路是通过一种名为“Garbling Trick”的通用方法,将现有的LLM评估转化为一系列难度递增的任务。这种方法的核心在于对原始评估任务进行某种形式的扰动或混淆,从而迫使模型进行更深入的推理才能正确完成任务。通过增加任务的难度,可以更有效地暴露模型在推理能力上的差异,从而更准确地评估模型的性能。
技术框架:该方法主要包含以下几个阶段:1)选择或构建一个基础的LLM评估任务(例如,多项选择题)。2)应用Garbling Trick对原始任务进行转换,生成一系列难度递增的新任务。Garbling Trick的具体实现方式可以根据任务类型进行调整,例如,可以引入干扰信息、改变问题的表达方式、增加问题的复杂性等。3)使用原始任务和转换后的任务对LLM进行评估。4)分析评估结果,比较不同模型在不同难度任务上的表现,从而更全面地了解模型的推理能力。
关键创新:该论文最重要的技术创新点在于提出了Garbling Trick这一通用方法,用于增强LLM评估的难度。与传统的评估方法相比,Garbling Trick能够更有效地挖掘模型的推理能力,从而更准确地评估模型的性能。此外,该方法具有通用性,可以应用于各种类型的LLM评估任务。
关键设计:论文中,Garbling Trick的具体实现方式取决于评估任务的类型。例如,在多项选择题中,可以通过以下方式应用Garbling Trick:1)引入与正确答案相似的干扰选项。2)改变问题的表达方式,使其更加模糊或复杂。3)增加问题的背景信息,使其更具迷惑性。此外,论文还可能涉及到一些参数设置,例如,控制Garbling Trick的强度,以生成不同难度的任务。损失函数和网络结构等细节取决于所评估的LLM本身,而非Garbling Trick方法。
🖼️ 关键图片

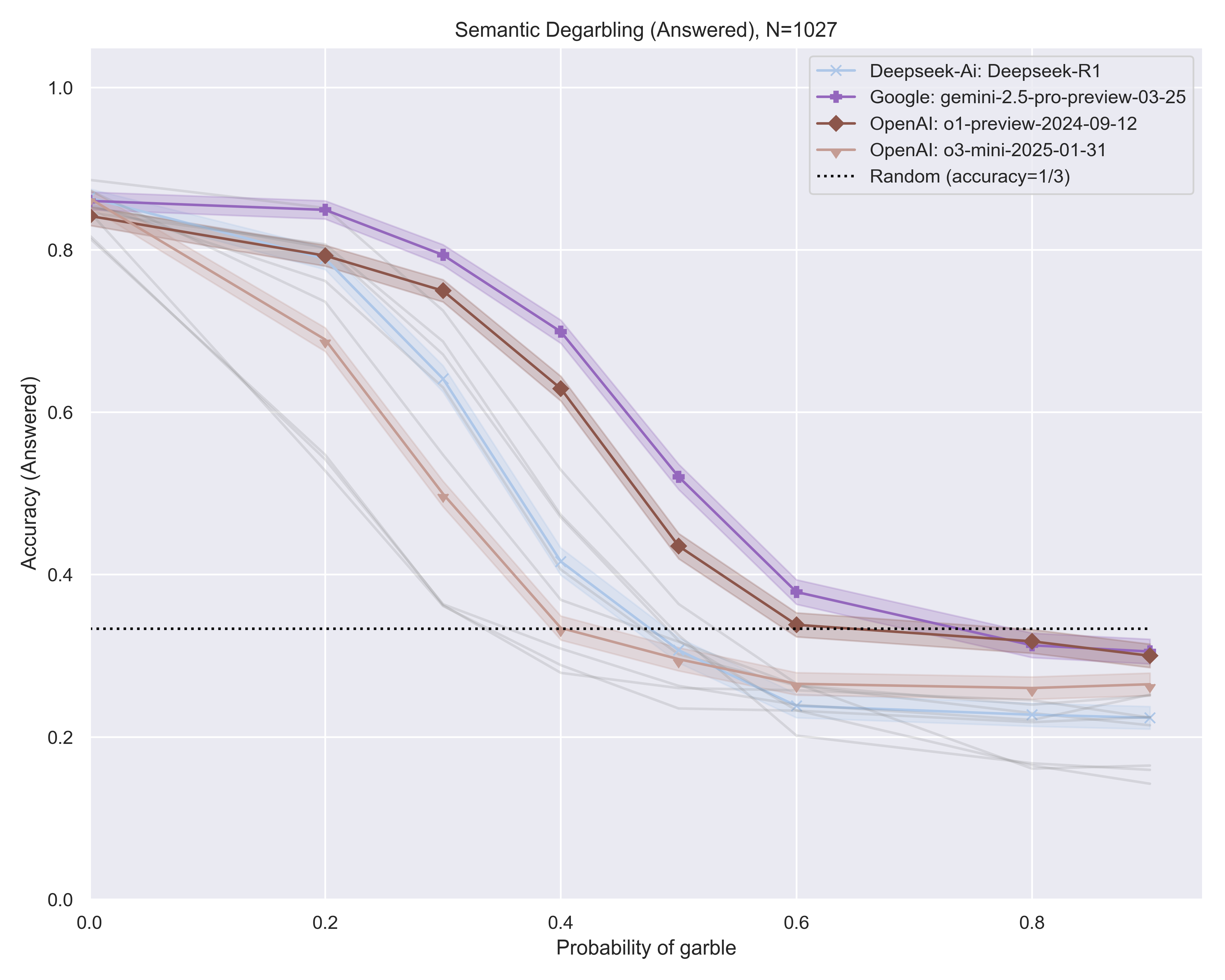

📊 实验亮点
论文通过实验验证了Garbling Trick的有效性,结果表明,使用Garbling Trick增强后的评估能够更有效地区分不同LLM的性能,尤其是在推理能力方面。实验结果还揭示了基础LLM和更先进的“推理”模型之间的差异,为模型选择和优化提供了有价值的参考。
🎯 应用场景
该研究成果可广泛应用于LLM的性能评估和模型选择。通过增强评估的难度,可以更准确地了解LLM的推理能力,从而为模型优化和应用部署提供更可靠的依据。此外,该方法还可以用于开发更具挑战性的LLM基准测试,推动LLM技术的发展。未来,该方法有望应用于教育、医疗、金融等领域,帮助人们更好地利用LLM解决实际问题。
📄 摘要(原文)
As large language models (LLMs) become increasingly powerful, traditional evaluation metrics tend to saturate, making it challenging to distinguish between models. We propose a general method to transform existing LLM evaluations into a series of progressively more difficult tasks. These enhanced evaluations emphasize reasoning capabilities and can reveal relative performance differences that are not apparent in the original assessments. To demonstrate the effectiveness of our approach, we create a new multiple-choice test corpus, extend it into a family of evaluations, and assess a collection of LLMs. Our results offer insights into the comparative abilities of these models, particularly highlighting the differences between base LLMs and more recent "reasoning" models.