Teaching Models to Improve on Tape
作者: Liat Bezalel, Eyal Orgad, Amir Globerson
分类: cs.CL
发布日期: 2024-11-03 (更新: 2024-11-06)
💡 一句话要点
提出CORGI:通过强化学习和对话反馈提升LLM在约束条件下的内容生成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 对话反馈 受控生成 元学习
📋 核心要点
- 现有LLM在约束条件下生成内容时面临挑战,难以保证生成结果满足所有约束。
- CORGI通过强化学习框架,模拟人机交互,利用对话反馈信号训练LLM,提升其约束满足能力。
- 实验表明,CORGI优于传统强化学习方法,并具备元学习能力,可泛化至新任务。
📝 摘要(中文)
大型语言模型(LLM)在特定约束条件下生成内容时常常表现不佳。然而,在这些情况下,通常很容易检查这些约束是否得到满足或违反。最近的研究表明,LLM可以从这种“纠正性反馈”中受益。本文提出,可以通过训练来显著增强LLM的这种能力。我们引入了一个强化学习框架,通过模拟交互会话并根据模型满足约束的能力来奖励模型,从而教导模型使用这种奖励。我们将我们的方法称为CORGI(用于引导交互的强化学习控制生成),并在各种使用未标记训练数据的受控生成任务上对其进行评估。我们发现,CORGI始终优于未结合对话反馈的基线强化学习方法。此外,CORGI的交互式框架支持元学习,使LLM能够更好地推广到新任务中的引导交互。我们的结果清楚地表明,对话优化与强化学习相结合,显著提高了LLM在受控生成环境中的有效性。
🔬 方法详解
问题定义:大型语言模型在受控生成任务中,例如生成满足特定长度、关键词或风格的内容时,常常难以满足所有约束条件。现有的方法,如直接提示或微调,往往无法有效地利用约束信息,导致生成质量下降。强化学习方法虽然可以优化生成过程,但缺乏有效的反馈机制来指导模型学习,训练效率较低。
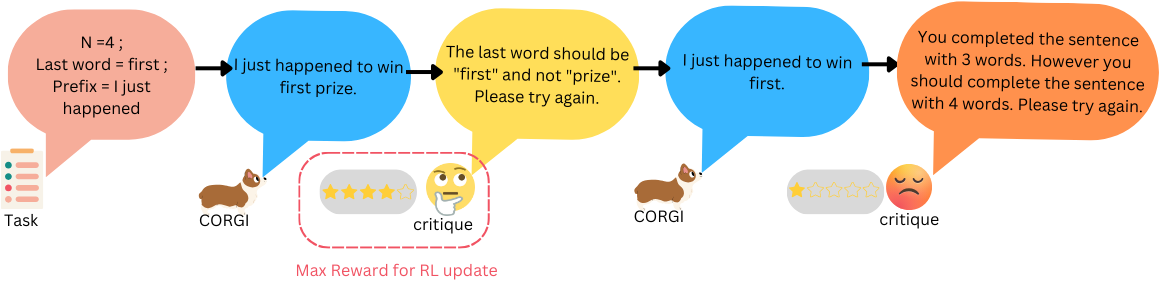
核心思路:CORGI的核心思路是利用对话反馈来指导LLM的训练。通过模拟人机交互过程,模型生成内容后,会得到一个反馈信号,指示其是否满足约束条件。这个反馈信号被用作强化学习的奖励,引导模型学习如何更好地满足约束。这种交互式的学习方式可以更有效地利用约束信息,提高生成质量。
技术框架:CORGI的整体框架包含以下几个主要模块:1) LLM生成器:负责根据输入提示生成内容。2) 约束检查器:负责检查生成的内容是否满足预定义的约束条件。3) 奖励函数:根据约束检查器的结果,为生成器提供奖励信号。4) 强化学习算法:利用奖励信号更新生成器的参数,使其能够更好地满足约束。训练过程模拟多轮对话,每一轮中,LLM生成内容,约束检查器给出反馈,强化学习算法更新模型。
关键创新:CORGI的关键创新在于将对话反馈融入到强化学习框架中。传统的强化学习方法通常依赖于稀疏的奖励信号,难以有效地指导模型学习。CORGI通过引入约束检查器,可以提供更丰富、更密集的反馈信号,从而加速模型的学习过程。此外,CORGI的交互式框架还支持元学习,使模型能够更好地泛化到新的任务中。
关键设计:CORGI使用策略梯度算法(如PPO)来更新LLM生成器的参数。奖励函数的设计至关重要,需要根据具体的约束条件进行调整。例如,对于长度约束,可以使用生成内容长度与目标长度之间的差异作为奖励信号。对于关键词约束,可以使用生成内容中关键词的出现次数作为奖励信号。此外,CORGI还使用了经验回放技术,以提高训练的稳定性。
🖼️ 关键图片

📊 实验亮点
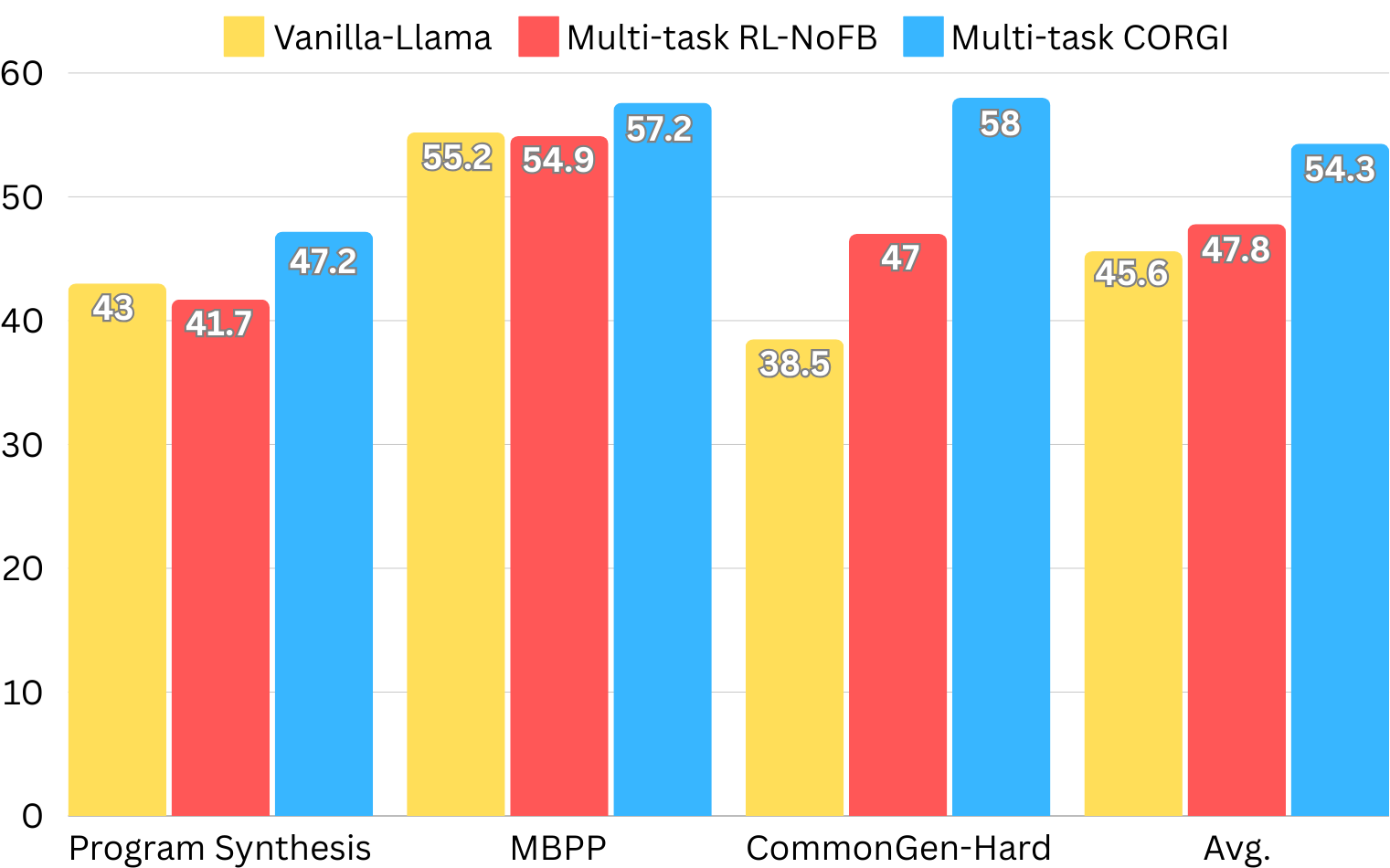
实验结果表明,在多个受控生成任务上,CORGI consistently outperforms the baseline reinforcement learning method that does not incorporate conversational feedback。CORGI的交互式框架还支持元学习,使LLM能够更好地推广到新任务中的引导交互。具体性能提升数据未知,需参考论文原文。
🎯 应用场景
CORGI可应用于各种需要受控内容生成的场景,例如:自动生成摘要、生成符合特定风格的文章、生成满足特定长度限制的文本、生成包含特定关键词的广告文案等。该研究成果有助于提高LLM在实际应用中的可靠性和可控性,具有广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) often struggle when prompted to generate content under specific constraints. However, in such cases it is often easy to check whether these constraints are satisfied or violated. Recent works have shown that LLMs can benefit from such "corrective feedback". Here we claim that this skill of LLMs can be significantly enhanced via training. We introduce an RL framework for teaching models to use such rewards, by simulating interaction sessions, and rewarding the model according to its ability to satisfy the constraints. We refer to our method as CORGI (Controlled Generation with RL for Guided Interaction), and evaluate it on a variety of controlled generation tasks using unlabeled training data. We find that CORGI consistently outperforms the baseline reinforcement learning method that does not incorporate conversational feedback. Furthermore, CORGI's interactive framework enables meta-learning, allowing the LLM to generalize better to guided interaction in new tasks. Our results clearly show that conversational optimization, when combined with reinforcement learning, significantly improves the effectiveness of LLMs in controlled generation contexts.