TODO: Enhancing LLM Alignment with Ternary Preferences
作者: Yuxiang Guo, Lu Yin, Bo Jiang, Jiaqi Zhang
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-11-02 (更新: 2025-03-29)
备注: Accepted to ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出TODO算法,利用三元偏好优化LLM对齐,提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM对齐 偏好学习 三元偏好 Bradley-Terry模型 TOBT模型 直接偏好优化 人工智能 语言模型
📋 核心要点
- 现有LLM对齐方法,如DPO,依赖二元BT模型,难以处理人类偏好中的噪声、不一致和平局情况。
- TODO算法基于TOBT模型,显式建模平局情况,利用三元排序系统提升LLM偏好对齐能力。
- 实验表明,TODO在多个数据集和模型上优于DPO,并在二元偏好对齐上表现出强大的性能。
📝 摘要(中文)
为了提升大型语言模型(LLM)与人类意图的对齐,本文提出了一种新的对齐算法——Tie-rank Oriented Direct Preference Optimization (TODO)。现有方法如Direct Preference Optimization (DPO) 通常依赖于二元的Bradley-Terry (BT)模型,难以捕捉人类偏好的复杂性,尤其是在存在噪声、不一致标签和频繁平局的情况下。为了解决这些局限性,本文引入了Tie-rank Oriented Bradley-Terry模型 (TOBT),它是BT模型的扩展,显式地考虑了平局,从而实现更细致的偏好表示。TODO算法利用TOBT的三元排序系统来改进偏好对齐。在Mistral-7B和Llama 3-8B模型上的评估表明,TODO在同分布和异分布数据集上始终优于DPO。使用MT Bench以及Piqa、ARC-c和MMLU等基准的额外评估进一步证明了TODO卓越的对齐性能。值得注意的是,TODO在二元偏好对齐方面也表现出强大的结果,突出了其多功能性和更广泛地集成到LLM对齐中的潜力。代码已开源。
🔬 方法详解
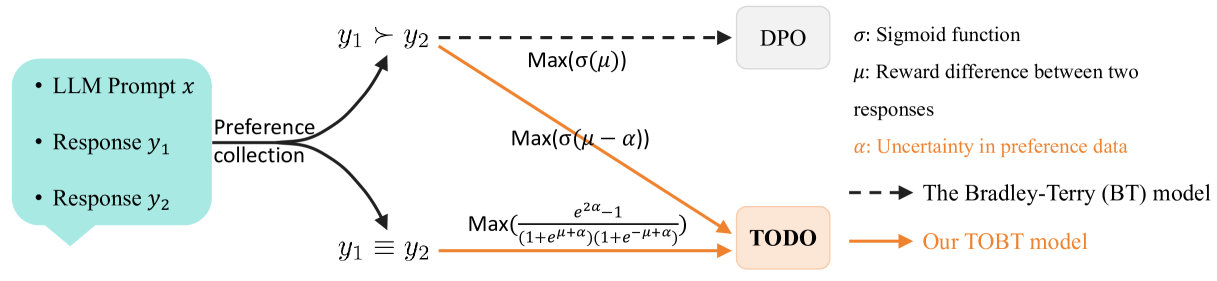
问题定义:现有的大型语言模型对齐方法,特别是基于直接偏好优化(DPO)的方法,通常使用二元的Bradley-Terry(BT)模型来建模人类的偏好。然而,这种二元模型无法充分捕捉人类偏好的复杂性,尤其是在数据集中存在噪声、不一致的标注以及频繁出现“平局”或无法区分优劣的情况时,会导致模型学习效率下降和泛化能力不足。因此,如何更准确地建模人类偏好,特别是处理“平局”情况,是需要解决的关键问题。
核心思路:本文的核心思路是通过扩展传统的Bradley-Terry模型,引入Tie-rank Oriented Bradley-Terry(TOBT)模型,显式地建模“平局”情况。TOBT模型将偏好关系扩展为三元关系:胜出、失败和平局。基于TOBT模型,本文提出了Tie-rank Oriented Direct Preference Optimization(TODO)算法,该算法能够利用三元偏好信息更有效地对齐LLM。这样设计的目的是为了更准确地反映人类的真实偏好,从而提升LLM的性能。
技术框架:TODO算法的整体框架与DPO类似,但关键区别在于偏好建模方式。首先,收集包含三元偏好信息的数据集,即对于每个prompt,标注多个response,并标注它们之间的胜出、失败或平局关系。然后,使用TOBT模型对这些偏好关系进行建模,得到一个偏好模型。最后,使用TODO算法,基于这个偏好模型来微调LLM,使其更好地与人类偏好对齐。TODO算法的目标是最大化模型生成符合人类偏好的response的概率,同时最小化生成不符合人类偏好的response的概率,并考虑平局情况。
关键创新:最重要的技术创新点在于TOBT模型的引入和TODO算法的设计。TOBT模型通过显式地建模“平局”情况,更准确地反映了人类的偏好。TODO算法则利用TOBT模型提供的三元偏好信息,更有效地对齐LLM。与DPO等现有方法相比,TODO能够更好地处理噪声数据和不一致的标注,并且能够更好地泛化到新的数据集上。
关键设计:TODO算法的关键设计在于损失函数的设计,该损失函数基于TOBT模型,考虑了胜出、失败和平局三种情况。具体来说,损失函数包含三个部分:一部分用于鼓励模型生成胜出的response,一部分用于惩罚模型生成失败的response,还有一部分用于鼓励模型生成与人类标注为平局的response相似的response。损失函数的具体形式未知,需要参考论文原文或开源代码。
🖼️ 关键图片
📊 实验亮点
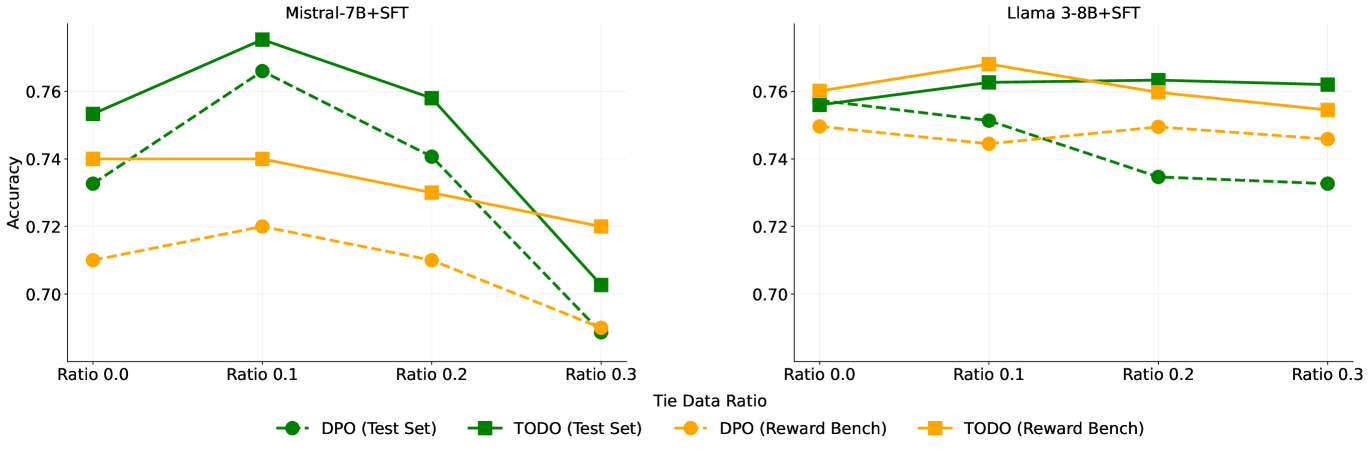
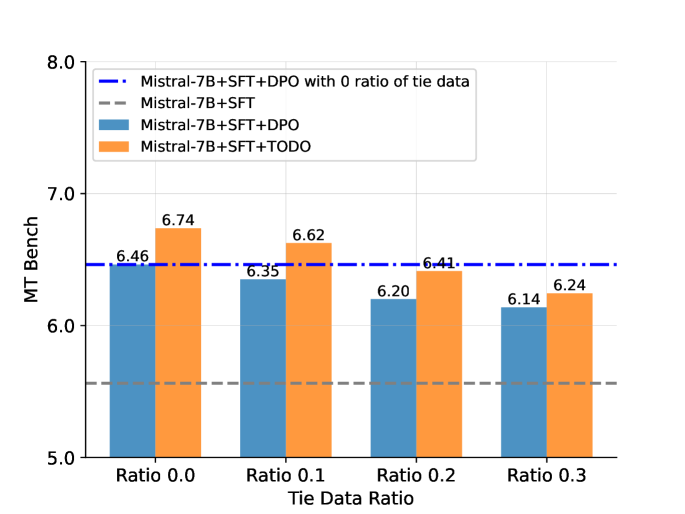
实验结果表明,TODO算法在Mistral-7B和Llama 3-8B模型上,相比DPO算法,在同分布和异分布数据集上均取得了显著的性能提升。在MT Bench以及Piqa、ARC-c和MMLU等基准测试中,TODO也表现出更优越的对齐性能。此外,TODO在二元偏好对齐方面也表现出强大的结果,证明了其通用性。
🎯 应用场景
TODO算法可广泛应用于各种需要LLM与人类意图对齐的场景,例如对话系统、文本生成、代码生成等。通过更准确地建模人类偏好,TODO可以提升LLM生成内容的质量、相关性和安全性,从而提高用户满意度和信任度。未来,TODO可以与其他对齐技术相结合,进一步提升LLM的性能和可靠性。
📄 摘要(原文)
Aligning large language models (LLMs) with human intent is critical for enhancing their performance across a variety of tasks. Standard alignment techniques, such as Direct Preference Optimization (DPO), often rely on the binary Bradley-Terry (BT) model, which can struggle to capture the complexities of human preferences -- particularly in the presence of noisy or inconsistent labels and frequent ties. To address these limitations, we introduce the Tie-rank Oriented Bradley-Terry model (TOBT), an extension of the BT model that explicitly incorporates ties, enabling more nuanced preference representation. Building on this, we propose Tie-rank Oriented Direct Preference Optimization (TODO), a novel alignment algorithm that leverages TOBT's ternary ranking system to improve preference alignment. In evaluations on Mistral-7B and Llama 3-8B models, TODO consistently outperforms DPO in modeling preferences across both in-distribution and out-of-distribution datasets. Additional assessments using MT Bench and benchmarks such as Piqa, ARC-c, and MMLU further demonstrate TODO's superior alignment performance. Notably, TODO also shows strong results in binary preference alignment, highlighting its versatility and potential for broader integration into LLM alignment. The implementation details can be found in https://github.com/XXares/TODO.