Arena-Lite: Efficient and Reliable Large Language Model Evaluation via Tournament-Based Direct Comparisons
作者: Seonil Son, Ju-Min Oh, Heegon Jin, Cheolhun Jang, Jeongbeom Jeong, Kuntae Kim
分类: cs.CL, cs.AI
发布日期: 2024-11-02 (更新: 2025-10-28)
备注: 8 pages for main body, 19 pages in total
期刊: EMNLP 2025 Main
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
Arena-Lite:基于锦标赛直接比较的高效可靠大语言模型评测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评测 直接比较 锦标赛结构 模型选择 LLM评判器
📋 核心要点
- 现有LLM评测方法依赖于与基线比较,可靠性较低,且需要大量计算资源。
- Arena-Lite采用锦标赛结构和直接比较,无需基线,减少比较次数,提升评测可靠性。
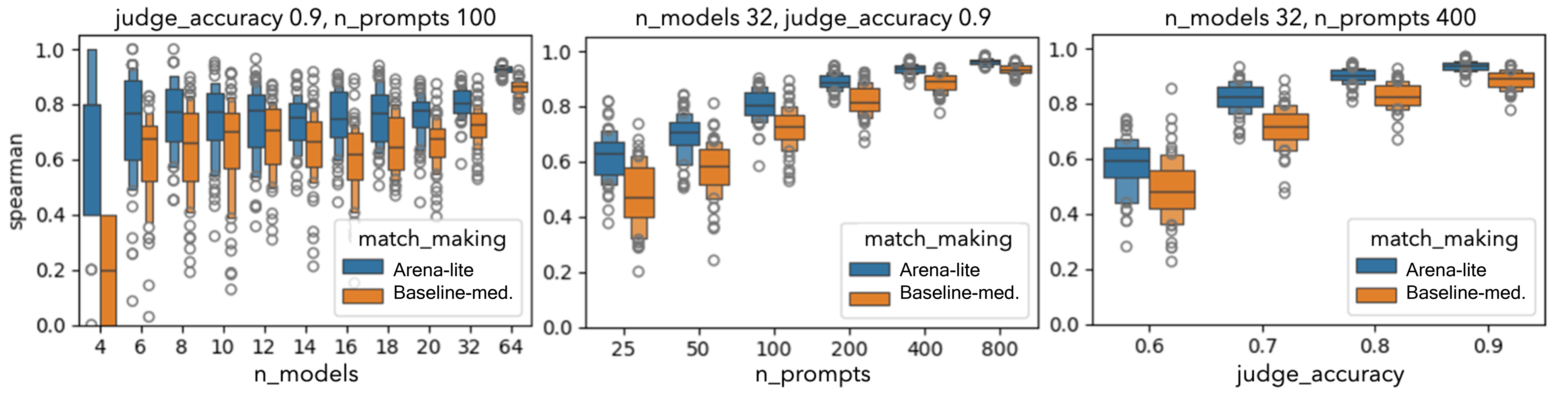
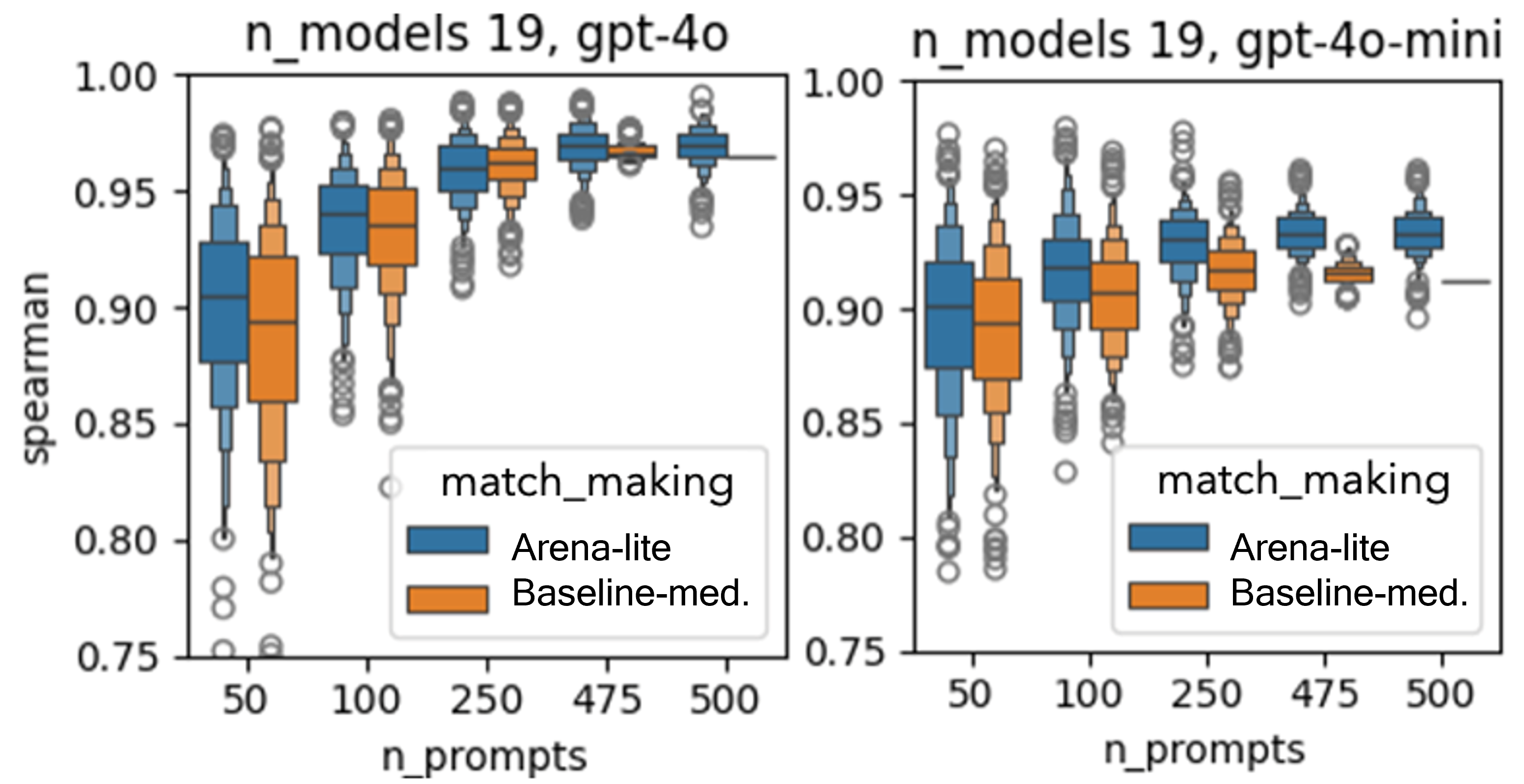
- 实验证明Arena-Lite在数据量较小或评判器较弱的情况下,仍能实现更高的可靠性。
📝 摘要(中文)
随着大语言模型(LLMs)在各个领域的扩展,LLM评判器已成为系统评估的关键。目前的基准测试通常将系统输出与基线进行比较。这种基于基线的方法虽然方便,但其可靠性低于系统间的直接比较。我们提出了Arena-Lite,它在两两比较的基础上集成了锦标赛结构。锦标赛结构和直接比较的应用消除了对基线输出的需求,减少了所需的比较次数,并提高了系统排名的可靠性。我们进行了两个实验:(1)受控随机建模;(2)使用真实LLM评判器的实证验证。这些实验共同表明,即使在较小的数据集或较弱的评判器下,Arena-Lite始终能够以更少的比较次数实现更高的可靠性。我们发布了一个易于使用的Web演示和代码,以促进Arena-Lite的采用,从而简化研究和工业界中的模型选择。
🔬 方法详解
问题定义:现有的大语言模型评测方法主要依赖于将模型的输出与预先设定的基线答案进行比较。这种方法的痛点在于,基线的选择会严重影响评测结果的客观性,并且难以覆盖所有可能的模型输出。此外,为了保证评测的准确性,需要大量的基线数据,导致评测成本高昂。
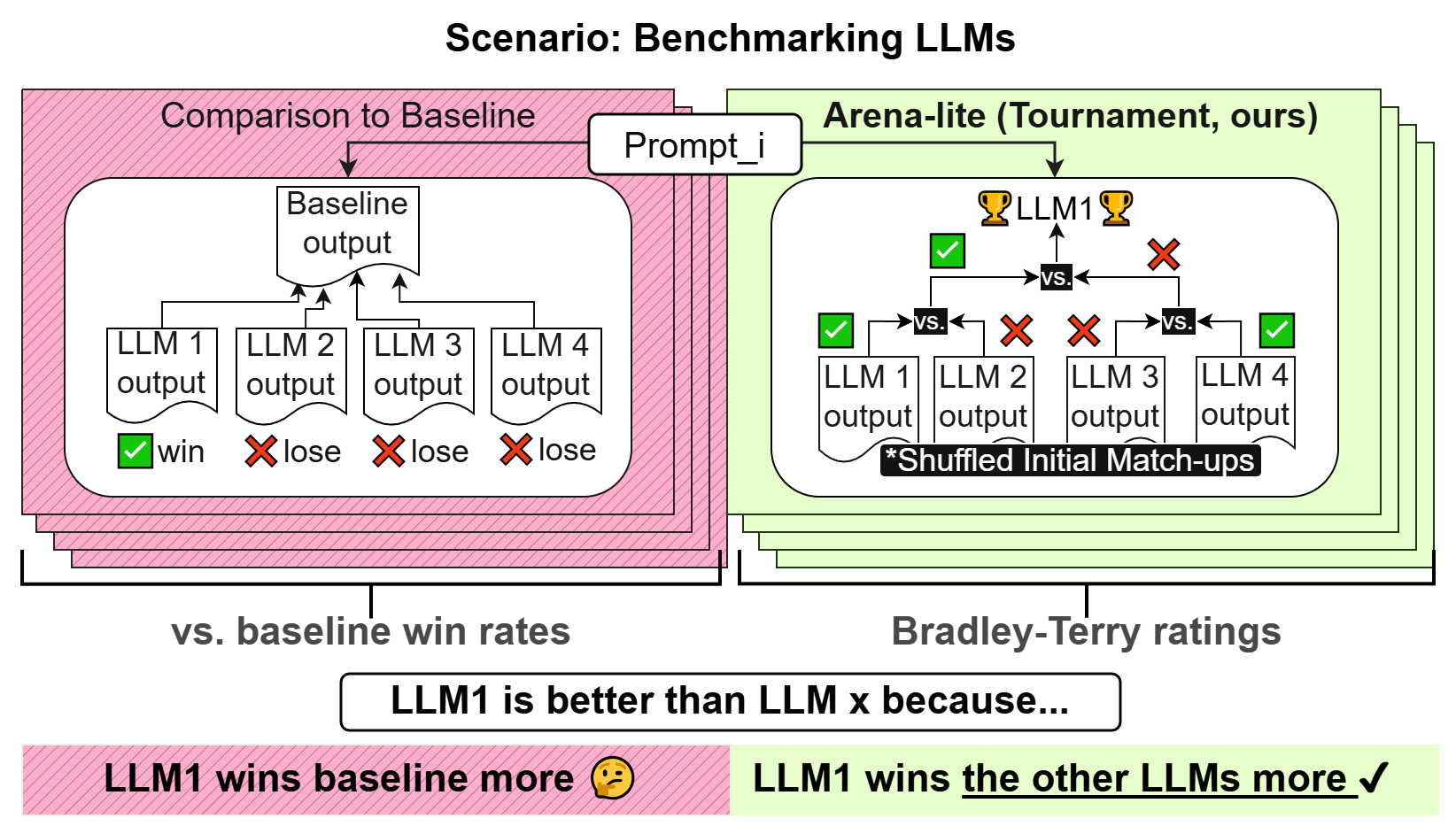
核心思路:Arena-Lite的核心思路是通过引入锦标赛的结构,将多个待评测的模型进行两两直接比较,而不是与基线进行比较。通过多轮的淘汰赛,最终选出性能最优的模型。这种直接比较的方式能够更客观地反映模型之间的相对性能差异,并且通过锦标赛的结构,可以有效地减少所需的比较次数。
技术框架:Arena-Lite的整体框架主要包括以下几个阶段:1. 模型配对:将所有待评测的模型进行随机配对。2. 两两比较:对于每一对模型,使用LLM评判器对它们的输出进行比较,判断哪个模型更优。3. 胜者晋级:根据比较结果,将每一轮的胜者晋级到下一轮比赛。4. 循环迭代:重复上述过程,直到只剩下一个模型,即为最终的冠军。
关键创新:Arena-Lite最重要的技术创新点在于将锦标赛结构引入到大语言模型的评测中。与传统的基于基线的评测方法相比,Arena-Lite无需预先设定基线,而是通过模型之间的直接比较来确定模型的优劣。这种方法更加客观、高效,并且能够更好地反映模型之间的相对性能差异。
关键设计:Arena-Lite的关键设计包括:1. 评判器的选择:选择合适的LLM评判器是保证评测结果准确性的关键。2. 比较策略:采用合适的比较策略,例如,可以根据不同的任务类型选择不同的比较指标。3. 淘汰机制:可以根据实际情况调整淘汰机制,例如,可以采用单败淘汰制或双败淘汰制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Arena-Lite在受控随机建模和真实LLM评判器实验中均表现出更高的可靠性,且所需的比较次数更少。即使在数据集较小或评判器较弱的情况下,Arena-Lite依然能够有效地进行模型评估和排序。例如,在某个实验中,Arena-Lite仅使用传统方法一半的比较次数,就达到了更高的排序准确率。
🎯 应用场景
Arena-Lite可广泛应用于大语言模型的选型、优化和持续监控。在研究领域,它可以帮助研究人员更高效地评估不同模型的性能,加速模型迭代。在工业界,它可以帮助企业选择最适合其业务需求的LLM,并持续监控模型的性能,确保其稳定可靠。此外,Arena-Lite还可以用于构建LLM排行榜,为用户提供参考。
📄 摘要(原文)
As Large Language Models (LLMs) expand across domains, LLM judges have become essential for systems evaluation. Current benchmarks typically compare system outputs against baselines. This baseline-mediated approach, though convenient, yields lower reliability than direct comparison between systems. We propose Arena-Lite which integrates tournament structure on top of head-to-head comparison. The application of a tournament structure and direct comparison eliminates the need for baseline outputs, reduces the number of required comparisons, and allows higher reliability in system rankings. We conducted two experiments: (1) controlled stochastic modeling and (2) empirical validation with a real LLM judge. Those experiments collectively demonstrate that Arena-Lite consistently achieves higher reliability with fewer comparisons, even with smaller datasets or weaker judges. We release an easy-to-use web demonstration and code to foster adoption of Arena-Lite, streamlining model selection across research and industry communities. Arena-Lite demo and code are available on \href{https://huggingface.co/spaces/NCSOFT/ArenaLite}{https://huggingface.co/spaces/NCSOFT/ArenaLite}