Transfer Learning for Finetuning Large Language Models
作者: Tobias Strangmann, Lennart Purucker, Jörg K. H. Franke, Ivo Rapant, Fabio Ferreira, Frank Hutter
分类: cs.CL, cs.LG
发布日期: 2024-11-02
备注: Accepted at NeurIPS 2024 Workshop on Adaptive Foundation Models
💡 一句话要点
提出基于迁移学习的大语言模型微调方法,提升微调效率与效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 迁移学习 大语言模型 微调 元学习 超参数优化
📋 核心要点
- 现有大语言模型微调方法面临参数选择复杂、效率低下的挑战,难以快速适应新任务。
- 论文提出基于迁移学习的微调方法,通过元学习将相关任务的配置知识迁移到新任务,避免了特定任务的贝叶斯优化。
- 实验结果表明,该方法在合成问答数据集和包含Microsoft Phi-3的元数据集上,优于零样本、默认微调和元优化基线。
📝 摘要(中文)
随着大型语言模型的发展,针对特定任务进行高效微调变得至关重要。同时,参数高效微调方法也在迅速发展。因此,从业者在寻找大型语言模型的最佳微调流程时面临着许多复杂选择。为了降低从业者的复杂性,我们研究了大型语言模型微调的迁移学习,旨在将相关微调任务的配置知识迁移到新任务。在这项工作中,我们通过元学习性能和成本代理模型来迁移微调,以进行来自新元数据集的灰盒元优化。与直觉相反,我们建议仅依赖于新数据集的迁移学习。因此,我们不使用特定于任务的贝叶斯优化,而是优先考虑从相关任务转移的知识,而不是特定于任务的反馈。我们在八个合成问答数据集和一个包含 Microsoft Phi-3 的 1,800 次微调运行的元数据集上评估了我们的方法。我们的迁移学习优于零样本、默认微调和元优化基线。我们的结果证明了微调的可迁移性,可以更有效地调整大型语言模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)微调过程中,针对新任务如何高效选择最优超参数配置的问题。现有方法,如贝叶斯优化,虽然可以找到较好的配置,但需要大量的任务特定反馈,计算成本高昂,且难以泛化到新的数据集上。因此,如何利用已有的微调经验,快速适应新的微调任务,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用迁移学习,将从相关微调任务中学习到的知识(包括性能和成本代理模型)迁移到新的微调任务上。通过这种方式,可以避免在新任务上从头开始进行昂贵的超参数搜索,从而提高微调效率。论文反直觉地提出,对于新数据集,仅依赖迁移学习,而不使用任务特定的贝叶斯优化,从而更加强调知识的迁移性。
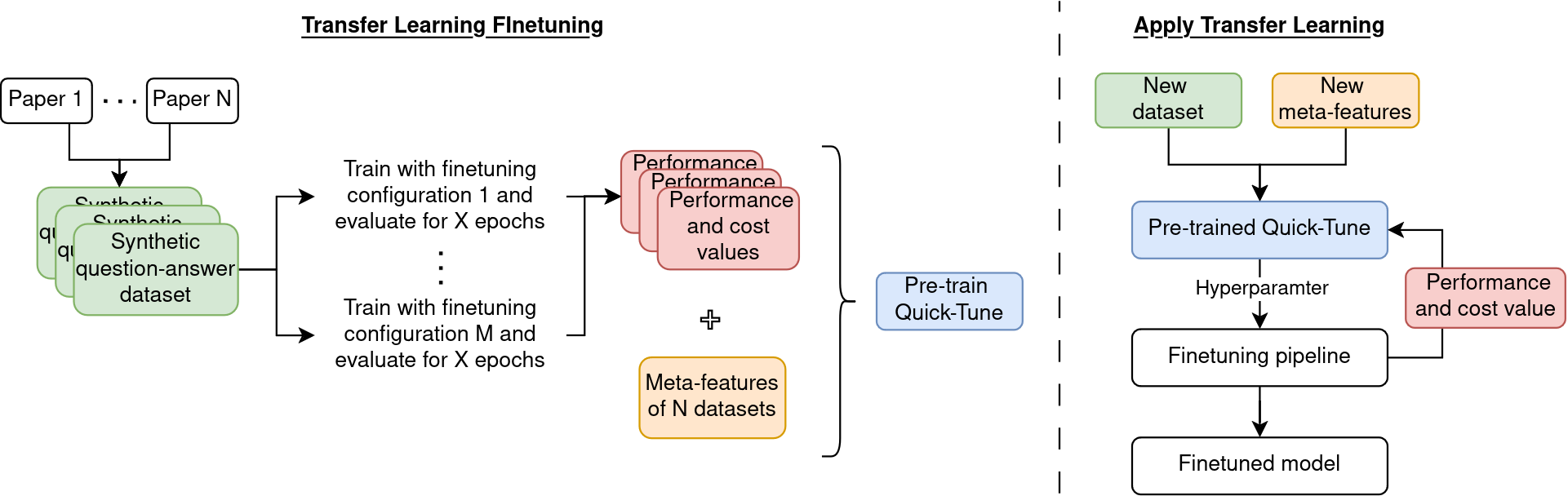
技术框架:整体框架包含以下几个主要阶段:1) 构建元数据集:收集多个相关微调任务的微调运行数据,包括超参数配置、性能指标和计算成本。2) 训练代理模型:基于元数据集,训练性能和成本的代理模型,用于预测不同超参数配置在不同任务上的性能和成本。3) 迁移学习:将训练好的代理模型迁移到新的微调任务上,利用代理模型预测不同超参数配置的性能,并选择最优配置进行微调。4) 评估:在新任务上评估微调后的模型性能。
关键创新:论文的关键创新在于:1) 提出了一种基于迁移学习的LLM微调方法,能够有效利用已有的微调经验,提高微调效率。2) 反直觉地提出仅依赖迁移学习,而不使用任务特定的贝叶斯优化,更加强调知识的迁移性。3) 构建了包含Microsoft Phi-3的微调元数据集,为后续研究提供了数据基础。
关键设计:论文的关键设计包括:1) 使用元学习来训练性能和成本代理模型,从而能够预测不同超参数配置在不同任务上的性能和成本。2) 设计了合适的迁移学习策略,将代理模型从相关任务迁移到新任务上。3) 选择了合适的超参数搜索空间,包括学习率、batch size等关键参数。
🖼️ 关键图片
📊 实验亮点
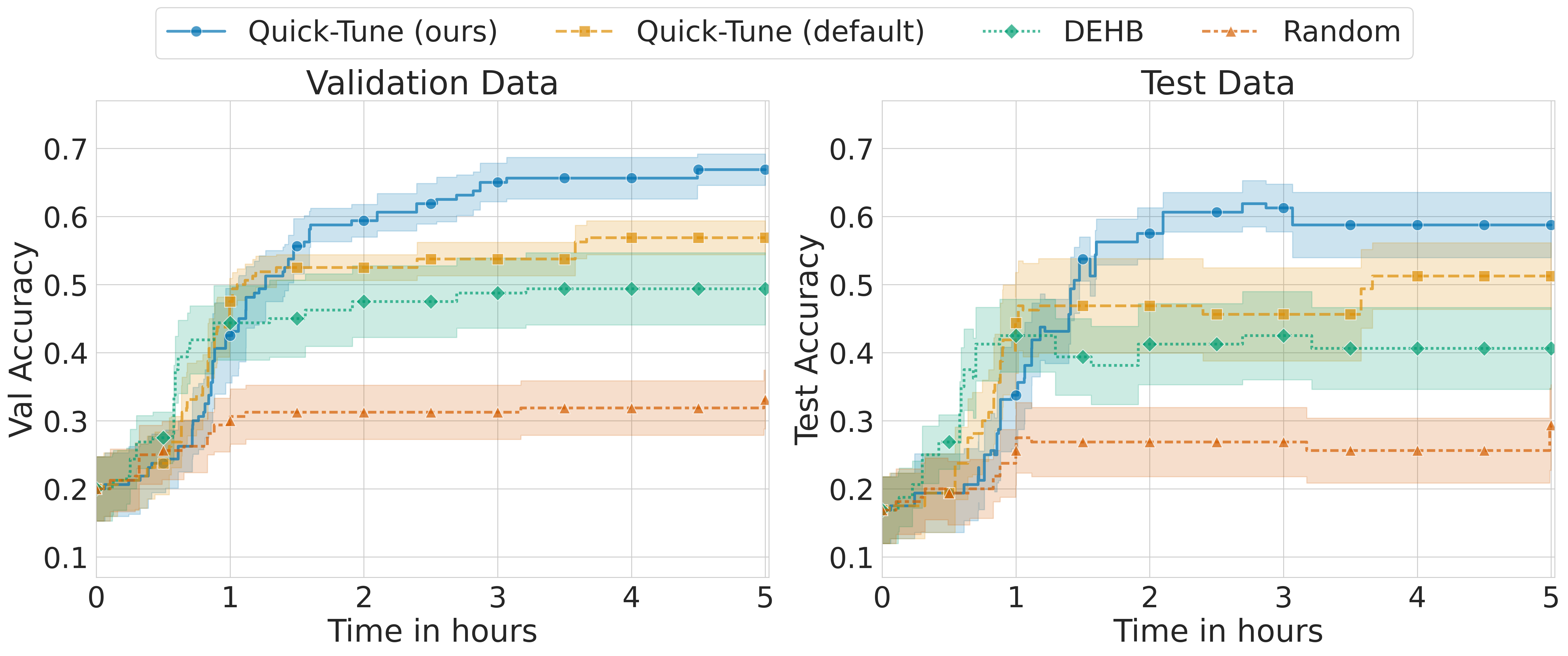
实验结果表明,该方法在八个合成问答数据集和一个包含 Microsoft Phi-3 的 1,800 次微调运行的元数据集上,优于零样本、默认微调和元优化基线。这证明了微调的可迁移性,可以更有效地调整大型语言模型。
🎯 应用场景
该研究成果可广泛应用于各种需要对大型语言模型进行微调的场景,例如:特定领域的问答系统、文本生成、机器翻译等。通过迁移学习,可以显著降低微调成本,提高模型在新任务上的适应性,加速LLM在各行业的落地应用。
📄 摘要(原文)
As the landscape of large language models expands, efficiently finetuning for specific tasks becomes increasingly crucial. At the same time, the landscape of parameter-efficient finetuning methods rapidly expands. Consequently, practitioners face a multitude of complex choices when searching for an optimal finetuning pipeline for large language models. To reduce the complexity for practitioners, we investigate transfer learning for finetuning large language models and aim to transfer knowledge about configurations from related finetuning tasks to a new task. In this work, we transfer learn finetuning by meta-learning performance and cost surrogate models for grey-box meta-optimization from a new meta-dataset. Counter-intuitively, we propose to rely only on transfer learning for new datasets. Thus, we do not use task-specific Bayesian optimization but prioritize knowledge transferred from related tasks over task-specific feedback. We evaluate our method on eight synthetic question-answer datasets and a meta-dataset consisting of 1,800 runs of finetuning Microsoft's Phi-3. Our transfer learning is superior to zero-shot, default finetuning, and meta-optimization baselines. Our results demonstrate the transferability of finetuning to adapt large language models more effectively.