CmdCaliper: A Semantic-Aware Command-Line Embedding Model and Dataset for Security Research
作者: Sian-Yao Huang, Cheng-Lin Yang, Che-Yu Lin, Chun-Ying Huang
分类: cs.CL
发布日期: 2024-11-02
💡 一句话要点
提出CmdCaliper:一个用于安全研究的语义感知命令行嵌入模型与数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命令行嵌入 网络安全 大型语言模型 数据集生成 恶意代码检测
📋 核心要点
- 网络安全领域缺乏全面的命令行数据集,阻碍了命令行嵌入技术的发展,主要原因是隐私和法规的限制。
- CmdCaliper通过大型语言模型生成大规模相似命令行对数据集CyPHER,并训练一个轻量级的语义感知命令行嵌入模型。
- 实验结果表明,CmdCaliper在恶意命令行检测和相似命令行检索等任务中,性能优于参数量更大的现有句子嵌入模型。
📝 摘要(中文)
本研究致力于解决网络安全中命令行嵌入的问题,该领域因隐私和法规限制而缺乏全面的数据集。我们提出了首个相似命令行数据集CyPHER,用于训练和公正评估。训练集由大型语言模型(LLM)生成,包含28,520个相似命令行对。测试数据集包含2,807个来自真实命令行数据的相似命令行对。此外,我们提出了一个名为CmdCaliper的命令行嵌入模型,能够计算命令行之间的语义相似性。性能评估表明,最小版本的CmdCaliper(3000万参数)在各种任务(例如,恶意命令行检测和相似命令行检索)中优于参数多十倍的最新(SOTA)句子嵌入模型。我们的研究探索了在网络安全领域使用LLM生成数据的可行性。此外,我们公开发布了我们提出的命令行数据集、嵌入模型的权重和所有程序代码。这一进展为未来研究人员更有效地进行命令行嵌入铺平了道路。
🔬 方法详解
问题定义:现有网络安全研究中,命令行分析至关重要,但缺乏大规模、高质量的命令行数据集,这限制了相关机器学习模型,特别是嵌入模型的训练和评估。现有的句子嵌入模型虽然可以用于命令行,但并非针对命令行场景优化,效果可能不佳。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成合成的相似命令行对,构建一个大规模的训练数据集。同时,设计一个轻量级的命令行嵌入模型CmdCaliper,专门用于学习命令行的语义表示。通过在合成数据集上训练,CmdCaliper能够更好地捕捉命令行的语义信息,从而在各种安全任务中表现出色。
技术框架:CmdCaliper的整体框架包含两个主要部分:1) 数据集生成:使用LLM生成大规模的相似命令行对数据集CyPHER,包括训练集和测试集。训练集用于训练CmdCaliper模型,测试集用于评估模型性能。2) 模型训练:设计并训练CmdCaliper命令行嵌入模型,该模型将命令行作为输入,输出其语义嵌入向量。
关键创新:论文的关键创新在于:1) 提出了一个利用LLM生成大规模相似命令行对数据集的方法,解决了网络安全领域数据稀缺的问题。2) 设计了一个轻量级的命令行嵌入模型CmdCaliper,该模型针对命令行场景进行了优化,能够有效地学习命令行的语义表示。
关键设计:CmdCaliper模型是一个基于Transformer的编码器结构,采用了对比学习的训练方式。具体来说,模型将一对相似的命令行作为输入,通过编码器得到它们的嵌入向量。然后,使用对比损失函数(例如InfoNCE)来最大化相似命令行对的嵌入向量之间的相似度,同时最小化不同命令行对的嵌入向量之间的相似度。模型的参数量相对较小(3000万),易于训练和部署。
🖼️ 关键图片
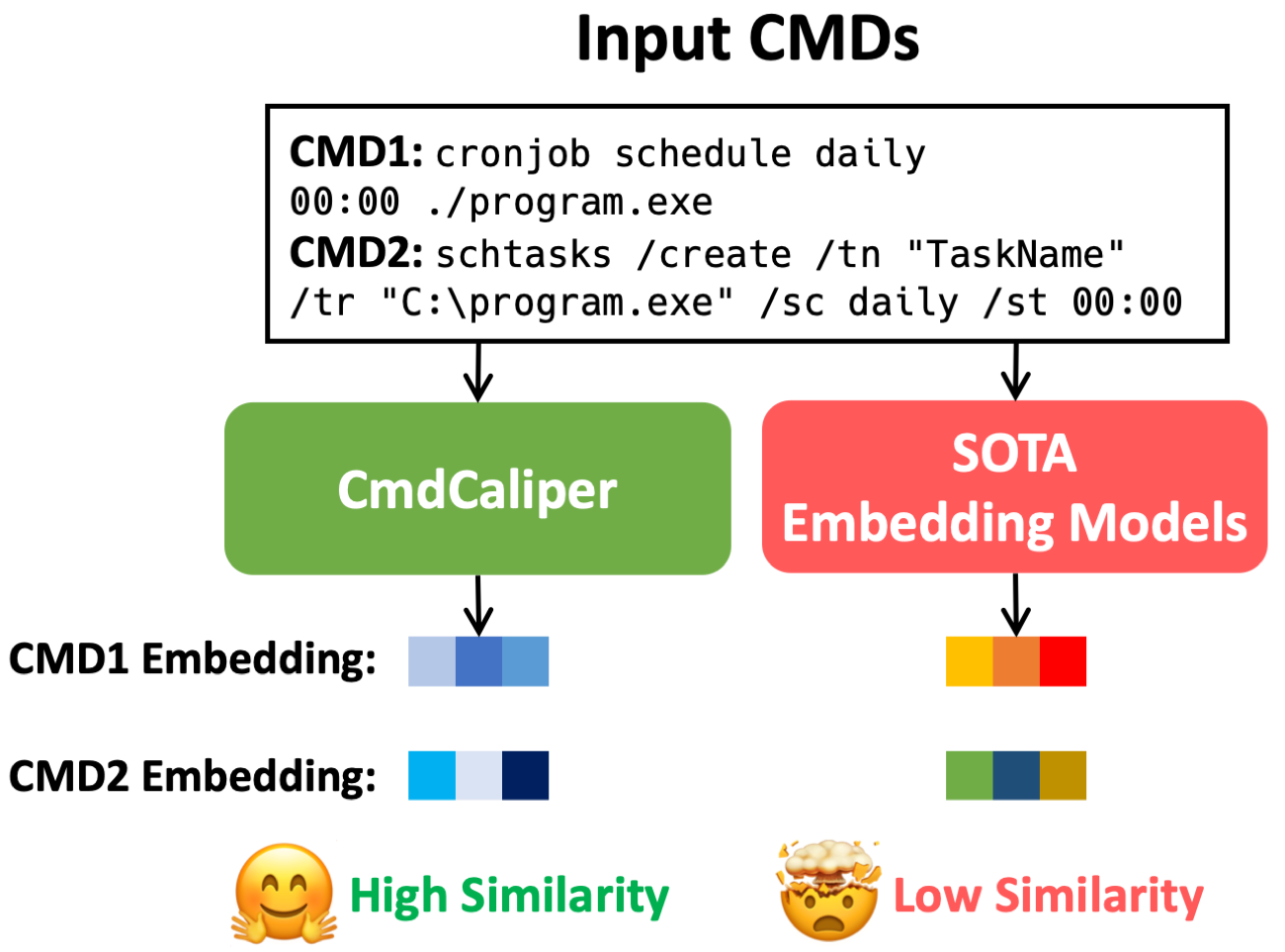
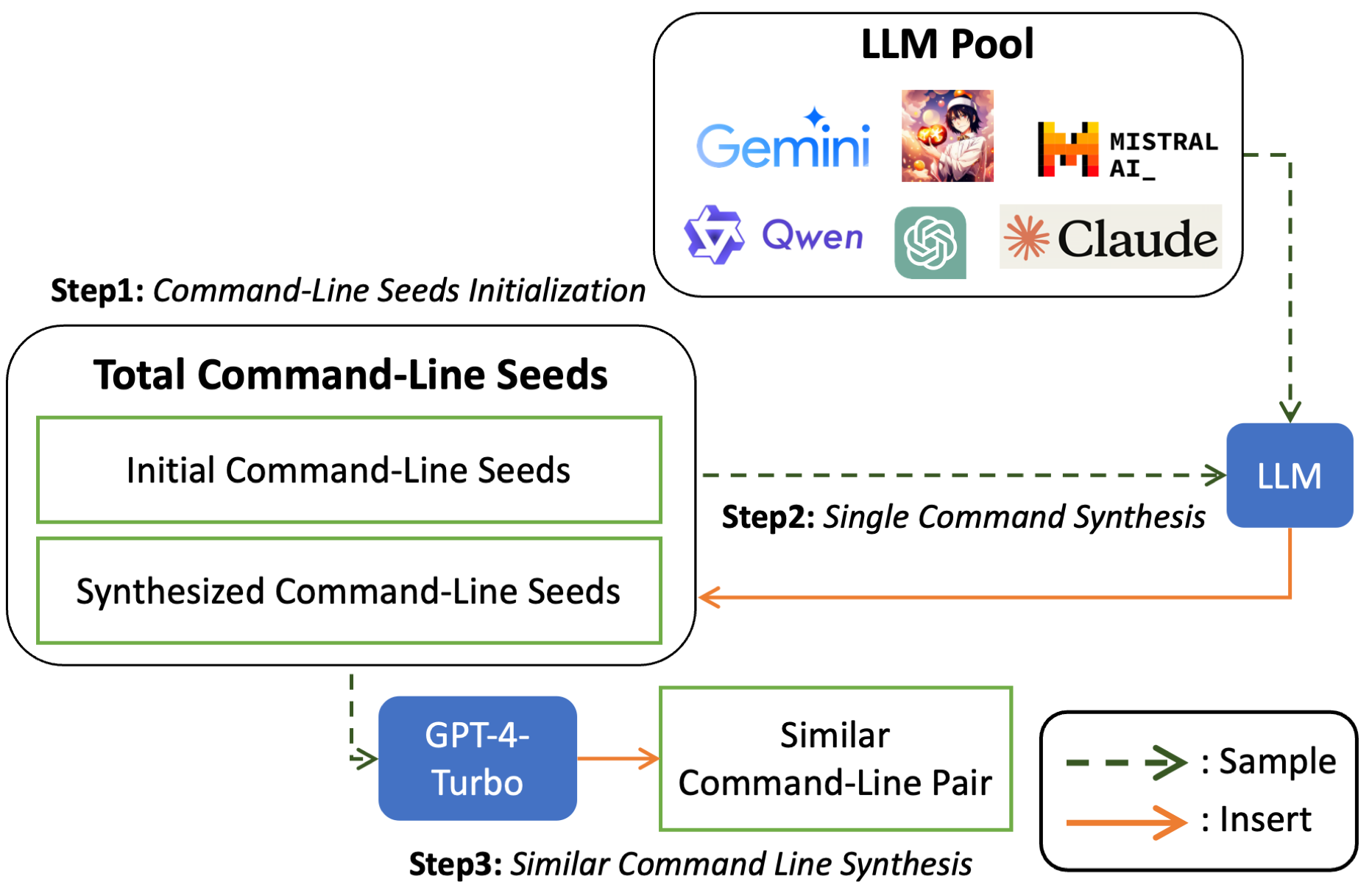
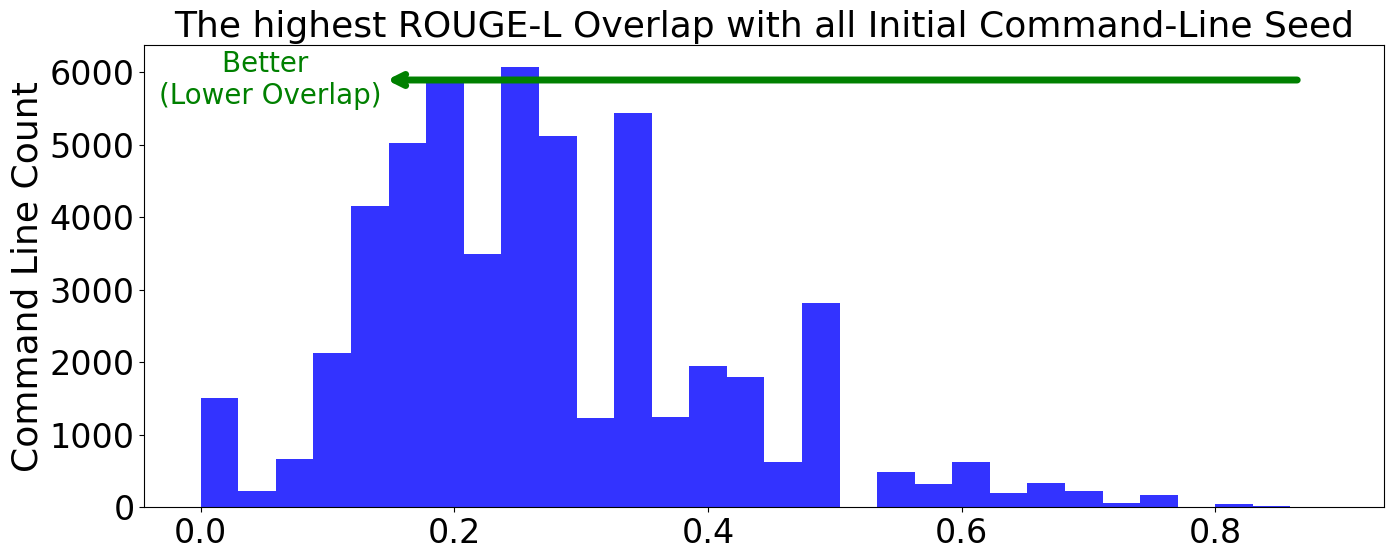
📊 实验亮点
CmdCaliper在恶意命令行检测和相似命令行检索等任务中取得了显著的性能提升。例如,实验结果表明,参数量仅为3000万的CmdCaliper模型,在这些任务中优于参数量高达3亿的现有句子嵌入模型。这表明CmdCaliper能够更有效地学习命令行的语义表示,并且具有更高的效率。
🎯 应用场景
CmdCaliper及其数据集CyPHER在网络安全领域具有广泛的应用前景,例如恶意命令行检测、入侵检测、威胁情报分析、漏洞挖掘等。它可以帮助安全分析师更有效地理解和分析命令行数据,从而提高安全事件的检测和响应能力。此外,该研究也为利用LLM生成安全领域数据提供了一个有益的参考。
📄 摘要(原文)
This research addresses command-line embedding in cybersecurity, a field obstructed by the lack of comprehensive datasets due to privacy and regulation concerns. We propose the first dataset of similar command lines, named CyPHER, for training and unbiased evaluation. The training set is generated using a set of large language models (LLMs) comprising 28,520 similar command-line pairs. Our testing dataset consists of 2,807 similar command-line pairs sourced from authentic command-line data. In addition, we propose a command-line embedding model named CmdCaliper, enabling the computation of semantic similarity with command lines. Performance evaluations demonstrate that the smallest version of CmdCaliper (30 million parameters) suppresses state-of-the-art (SOTA) sentence embedding models with ten times more parameters across various tasks (e.g., malicious command-line detection and similar command-line retrieval). Our study explores the feasibility of data generation using LLMs in the cybersecurity domain. Furthermore, we release our proposed command-line dataset, embedding models' weights and all program codes to the public. This advancement paves the way for more effective command-line embedding for future researchers.