Dictionary Insertion Prompting for Multilingual Reasoning on Multilingual Large Language Models
作者: Hongyuan Lu, Zixuan Li, Wai Lam
分类: cs.CL
发布日期: 2024-11-02
💡 一句话要点
提出字典插入提示(DIP)方法,提升多语言大模型在非英语推理任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 大型语言模型 提示工程 字典插入 低资源语言
📋 核心要点
- 现有大型语言模型主要以英语数据训练,导致其在非英语推理任务中表现不佳,尤其是在低资源语言上。
- 论文提出字典插入提示(DIP)方法,通过在非英语提示中插入对应英语单词,辅助模型理解和推理。
- 实验表明,DIP方法在多种语言的数学和常识推理任务上,显著提升了开源和闭源LLM的性能。
📝 摘要(中文)
当前的大型语言模型(LLM)训练数据主要以英语语料为主,导致它们以英语为中心,在英语推理任务上表现出色,但在其他语言上的性能通常较低。全球约有7000种语言,其中许多语言在以英语为中心的LLM上属于低资源语言。为了主要使用这些语言的人们,迫切需要在这些语言中启用LLM。模型训练通常有效,但计算成本高昂,并且需要经验丰富的NLP从业者。本文提出了一种新颖、简单但有效的方法,称为字典插入提示(DIP)。当提供非英语提示时,DIP会查找单词字典,并将单词的英语对应词插入到LLM的提示中。这可以更好地翻译成英语,并改善英语模型思维步骤,从而带来明显更好的结果。我们使用FLORES-200中的约200种语言进行了实验。由于没有足够的数据集,我们使用NLLB翻译器从现有的4个英语推理基准(如GSM8K和AQuA)创建合成的多语言基准。尽管DIP方法简单且计算量轻,但我们惊讶地发现它在多个开源和闭源LLM上的数学和常识推理任务中非常有效。
🔬 方法详解
问题定义:论文旨在解决多语言大型语言模型(MLLM)在非英语推理任务中表现不佳的问题。现有方法,如直接使用非英语提示进行推理,往往由于模型对非英语的理解不足而导致性能下降。模型训练虽然有效,但计算成本高昂,且需要专业的NLP知识。
核心思路:论文的核心思路是利用英语作为MLLM的“枢纽”语言。通过将非英语提示中的关键单词翻译成英语,并将其插入到原始提示中,从而增强模型对提示的理解,并利用模型在英语推理方面的优势。这种方法无需重新训练模型,且计算成本较低。
技术框架:DIP方法的整体流程如下:1) 接收非英语提示;2) 使用词典查找提示中每个单词的英语对应词;3) 将英语对应词插入到原始非英语提示中,形成新的提示;4) 将新的提示输入到MLLM中进行推理;5) 输出推理结果。该方法的核心模块是词典查找和提示构建。
关键创新:DIP方法的关键创新在于其简单性和有效性。它没有引入复杂的模型结构或训练过程,而是通过一种巧妙的提示工程方法,显著提升了MLLM在非英语推理任务中的性能。与现有方法相比,DIP方法无需重新训练模型,且计算成本较低,更易于部署和应用。
关键设计:DIP方法的关键设计在于词典的选择和英语单词的插入方式。论文中使用了现成的词典资源,例如Google Translate API或开源词典。英语单词的插入方式可以采用多种策略,例如将英语单词添加到原始单词旁边,或者将英语单词作为独立的句子添加到提示的开头或结尾。具体选择哪种策略可能需要根据具体的任务和模型进行调整。
🖼️ 关键图片
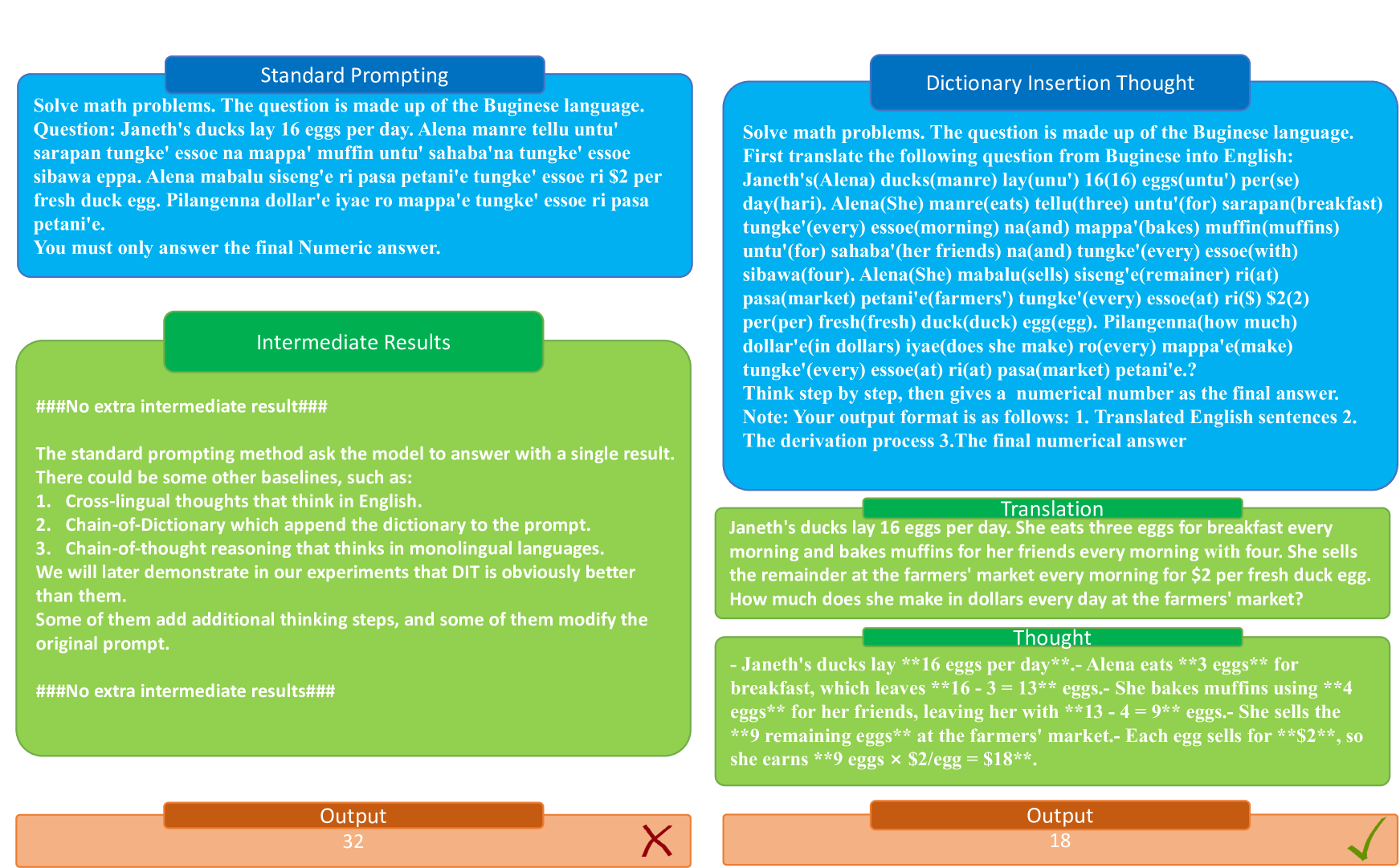
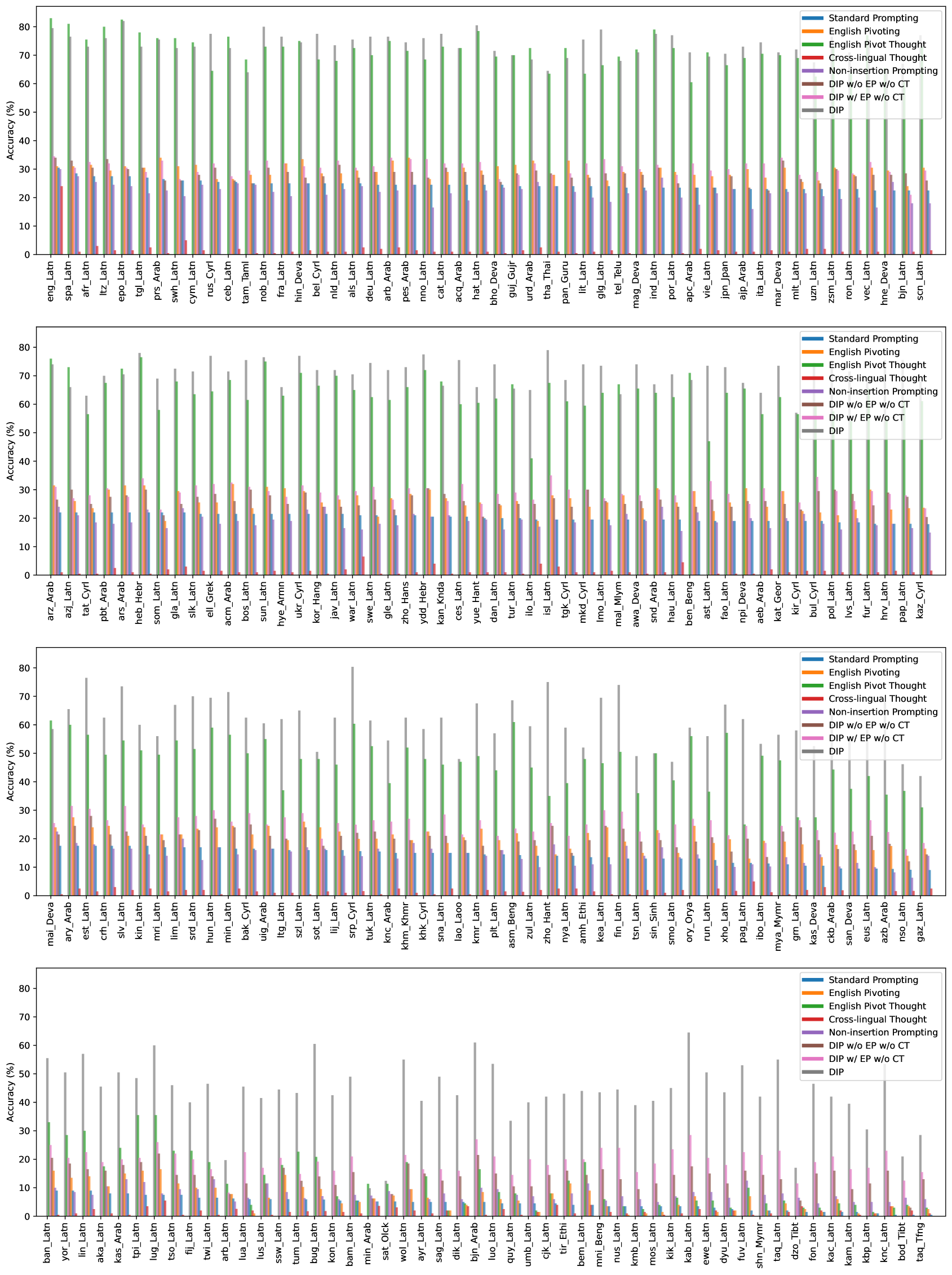
📊 实验亮点
实验结果表明,DIP方法在GSM8K和AQuA等基准数据集上,显著提升了MLLM在多种语言上的推理性能。例如,在某些语言上,DIP方法可以将模型的准确率提高10%以上。此外,DIP方法在开源和闭源LLM上均表现出良好的效果,表明其具有较强的通用性和适用性。
🎯 应用场景
该研究成果可广泛应用于多语言智能客服、跨语言信息检索、多语言教育等领域。通过提升LLM在非英语语言上的推理能力,可以更好地服务于全球用户,促进不同语言之间的交流和理解。未来,该方法可以进一步扩展到更多语言和任务,并与其他技术相结合,构建更加智能和高效的多语言应用。
📄 摘要(原文)
As current training data for Large Language Models (LLMs) are dominated by English corpus, they are English-centric and they present impressive performance on English reasoning tasks.\footnote{This paper primarily studies English-centric models, but our method could be universal by using the centric language in the dictionary for non-English-centric LLMs.} Yet, they usually suffer from lower performance in other languages. There are about 7,000 languages over the world, and many are low-resourced on English-centric LLMs. For the sake of people who primarily speak these languages, it is especially urgent to enable our LLMs in those languages. Model training is usually effective, but computationally expensive and requires experienced NLP practitioners. This paper presents a novel and simple yet effective method called \textbf{D}ictionary \textbf{I}nsertion \textbf{P}rompting (\textbf{DIP}). When providing a non-English prompt, DIP looks up a word dictionary and inserts words' English counterparts into the prompt for LLMs. It then enables better translation into English and better English model thinking steps which leads to obviously better results. We experiment with about 200 languages from FLORES-200. Since there are no adequate datasets, we use the NLLB translator to create synthetic multilingual benchmarks from the existing 4 English reasoning benchmarks such as GSM8K and AQuA. Despite the simplicity and computationally lightweight, we surprisingly found the effectiveness of DIP on math and commonsense reasoning tasks on multiple open-source and close-source LLMs.\footnote{Our dictionaries, code, and synthetic benchmarks will be open-sourced to facilitate future research.}