Self-Consistency Falls Short! The Adverse Effects of Positional Bias on Long-Context Problems
作者: Adam Byerly, Daniel Khashabi
分类: cs.CL
发布日期: 2024-11-02 (更新: 2025-10-02)
备注: 25 pages, 7 figures, 3 tables
💡 一句话要点
自洽性在长文本问题中失效:位置偏差的负面影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 位置偏差 自洽性 大型语言模型 上下文学习
📋 核心要点
- 现有大型语言模型在长文本处理中存在位置偏差,导致无法有效利用所有上下文信息。
- 论文挑战了自洽性在长文本任务中的有效性,指出其会加剧位置偏差,降低模型性能。
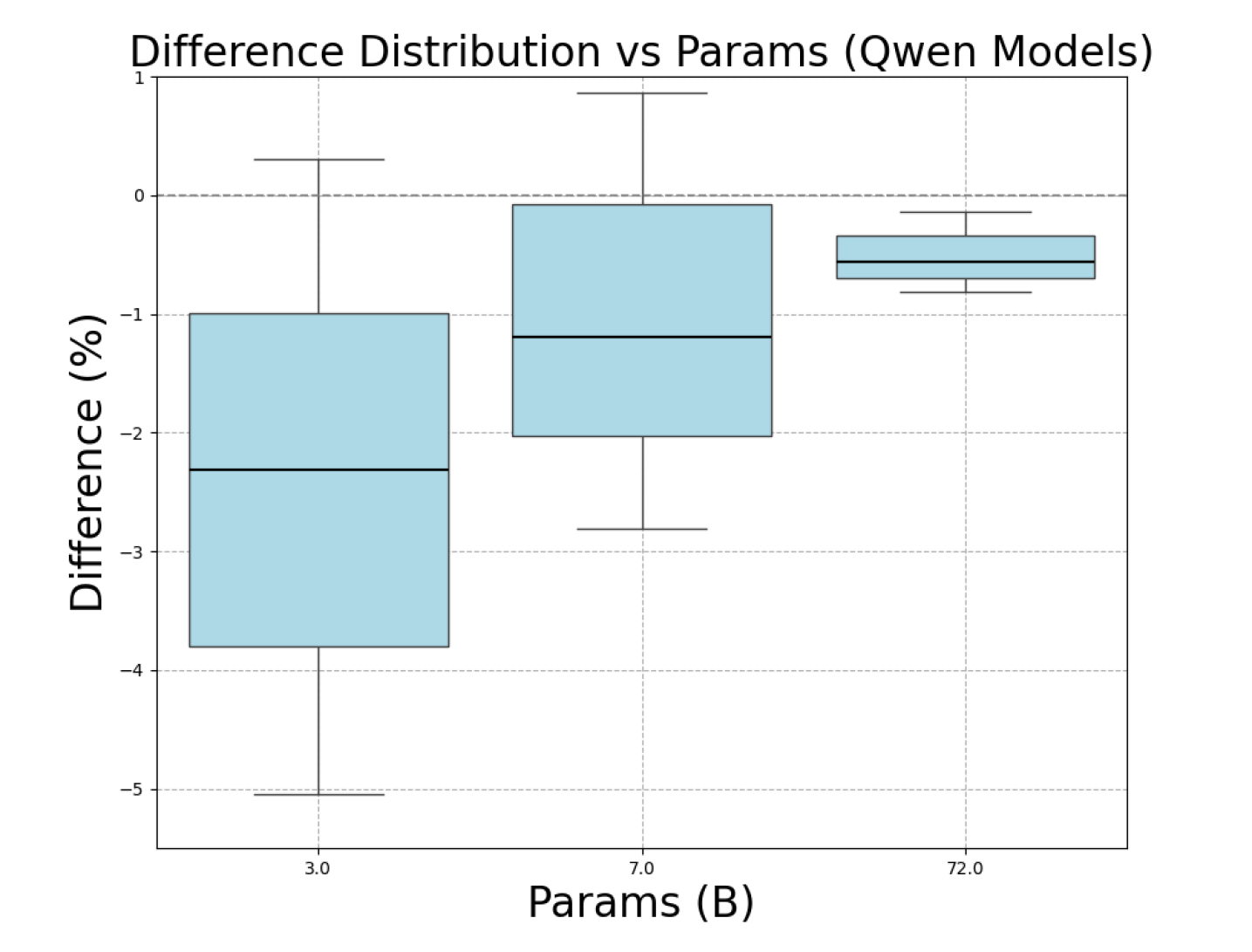
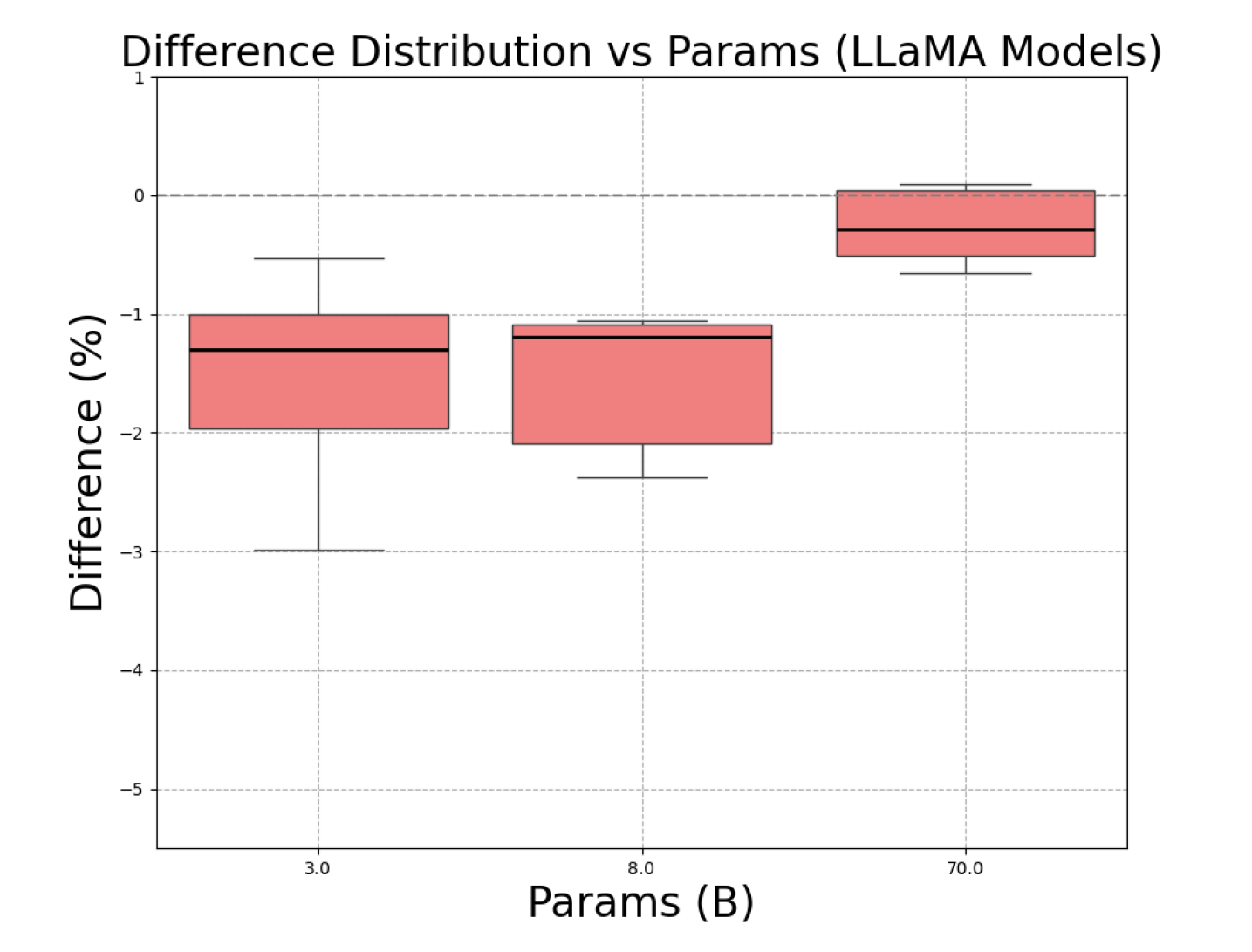
- 实验证明,自洽性在长文本任务中不仅不能提升性能,反而会使性能下降,尤其是在长文本和小型模型中。
📝 摘要(中文)
自洽性(SC)能够提升大型语言模型(LLM)在各种涉及短文本内容任务和领域中的性能。然而,这种优势是否能推广到长文本问题中呢?本文挑战了SC的有效性可以推广到长文本设置的假设,因为LLM在长文本中常常受到位置偏差的影响,即系统性地过度依赖特定的上下文区域,从而阻碍了它们有效地利用上下文中所有部分的信息。通过对各种最先进的模型、任务和SC公式进行全面的实验,我们发现SC不仅未能提高性能,反而积极地降低了长文本任务的性能。这种性能下降是由持续存在的位置偏差驱动的,位置偏差随着上下文长度的增加和模型尺寸的减小而恶化,但不受提示格式或任务类型的影响。与短文本任务中SC能够多样化推理路径不同,长文本SC放大了位置错误。这些全面的结果为当前LLM在长文本理解方面的局限性提供了有价值的见解,并强调了对更复杂方法的需求。
🔬 方法详解
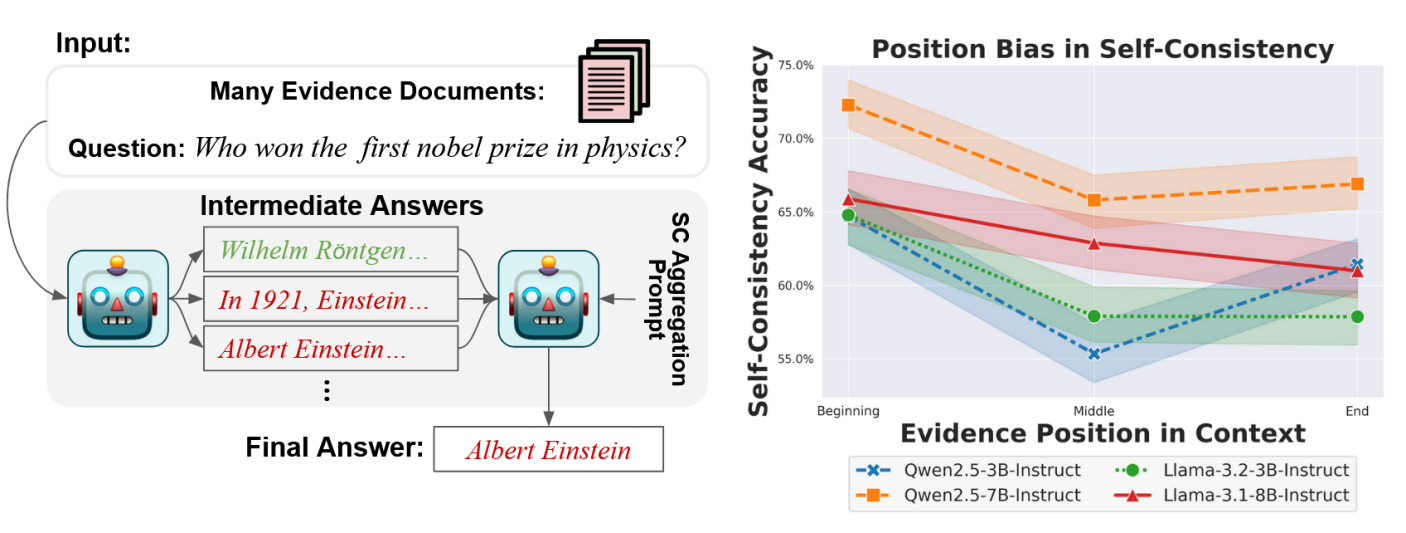
问题定义:论文旨在解决大型语言模型(LLM)在长文本理解任务中存在的“位置偏差”问题。现有方法,特别是自洽性(SC),在短文本任务中表现良好,但直接应用于长文本时,会加剧模型对特定位置信息的过度依赖,导致性能下降。这种位置偏差使得模型无法平等地利用上下文中的所有信息,从而影响最终的预测准确性。
核心思路:论文的核心思路是揭示自洽性(SC)在长文本任务中的负面影响,并将其归因于位置偏差的放大。作者认为,SC在短文本中通过生成多个不同的推理路径来提高鲁棒性,但在长文本中,由于模型已经存在严重的位置偏差,SC反而会强化这些偏差,导致最终结果的错误更加集中。因此,简单地应用SC并不能解决长文本理解问题,反而可能适得其反。
技术框架:论文通过一系列实验来验证SC在长文本任务中的负面影响。实验框架主要包括:1) 选择不同的LLM模型(包括不同尺寸的模型);2) 选择不同的长文本任务;3) 使用不同的SC公式;4) 评估模型在不同条件下的性能。通过对比使用SC和不使用SC的模型在长文本任务中的表现,以及分析位置偏差的程度,来验证论文的观点。
关键创新:论文最重要的技术创新在于揭示了自洽性(SC)在长文本任务中的负面作用,并将其与位置偏差联系起来。之前的研究主要关注SC在短文本任务中的优势,而忽略了其在长文本任务中可能存在的局限性。该研究表明,简单地将SC应用于长文本任务可能会适得其反,需要更复杂的策略来解决长文本理解问题。
关键设计:论文的关键设计在于实验设置的全面性,包括:1) 多种LLM模型:考虑了不同尺寸的模型,以评估模型大小对位置偏差的影响;2) 多种长文本任务:选择了不同类型的长文本任务,以验证结果的泛化性;3) 多种SC公式:使用了不同的SC实现方式,以排除特定SC公式的影响;4) 详细的性能评估:不仅评估了模型的整体性能,还分析了位置偏差的程度,以深入了解SC的负面影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在长文本任务中,自洽性(SC)不仅不能提高LLM的性能,反而会降低性能。性能下降与上下文长度和模型大小有关,更长的上下文和更小的模型会导致更严重的性能下降。例如,在特定长文本任务中,使用SC的模型性能比不使用SC的模型性能下降了5-10%。这些结果强调了在长文本任务中使用SC的局限性。
🎯 应用场景
该研究成果对长文本处理领域具有重要意义,可以指导未来LLM在处理长文本任务时的策略选择。避免盲目使用自洽性,转而探索更有效的缓解位置偏差的方法,例如位置编码优化、注意力机制改进等。潜在应用领域包括长文档摘要、长篇小说理解、法律文本分析等,有助于提升LLM在实际应用中的性能和可靠性。
📄 摘要(原文)
Self-consistency (SC) improves the performance of large language models (LLMs) across various tasks and domains that involve short content. However, does this support its effectiveness for long-context problems? We challenge the assumption that SC's benefits generalize to long-context settings, where LLMs often struggle with position bias, the systematic over-reliance on specific context regions-which hinders their ability to utilize information effectively from all parts of their context. Through comprehensive experimentation with varying state-of-the-art models, tasks, and SC formulations, we find that SC not only fails to improve but actively degrades performance on long-context tasks. This degradation is driven by persistent position bias, which worsens with longer context lengths and smaller model sizes but remains invariant to prompt format or task type. Unlike short-context tasks, where SC diversifies reasoning paths, long-context SC amplifies positional errors. These comprehensive results provide valuable insight into the limitations of current LLMs in long-context understanding and highlight the need for more sophisticated approaches.