LLM-Ref: Enhancing Reference Handling in Technical Writing with Large Language Models
作者: Kazi Ahmed Asif Fuad, Lizhong Chen
分类: cs.CL
发布日期: 2024-11-01 (更新: 2024-11-04)
备注: 20 pages, 7 figures
💡 一句话要点
LLM-Ref:利用大语言模型增强技术写作中的参考文献处理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 检索增强生成 技术写作 参考文献处理 迭代生成
📋 核心要点
- 现有RAG系统在检索和生成阶段的优化不足,影响了技术写作辅助工具的输出质量。
- LLM-Ref直接从文本段落检索和生成内容,并采用迭代响应生成来管理长上下文。
- 实验表明,LLM-Ref在Ragas评分上提升了3.25倍到6.26倍,显著增强了准确性和上下文相关性。
📝 摘要(中文)
大型语言模型(LLM)擅长数据综合,但在特定领域任务中可能不够准确。检索增强生成(RAG)系统通过利用用户提供的数据来解决这个问题。然而,RAG需要在检索和生成阶段进行优化,这会影响输出质量。本文提出LLM-Ref,一个写作辅助工具,旨在帮助研究人员利用多个源文档撰写文章,并增强参考文献的综合和处理能力。与使用分块和索引的传统RAG系统不同,我们的工具直接从文本段落中检索和生成内容。这种方法有助于从生成的输出中直接提取参考文献,这是我们工具独有的特性。此外,我们的工具采用迭代响应生成,有效地管理语言模型约束内的长上下文。与基于基线RAG的系统相比,我们的方法在Ragas评分上实现了3.25倍到6.26倍的提升,Ragas评分是一个综合指标,可以全面了解RAG系统生成准确、相关和上下文适当的响应的能力。这一改进表明我们的方法增强了写作辅助工具的准确性和上下文相关性。
🔬 方法详解
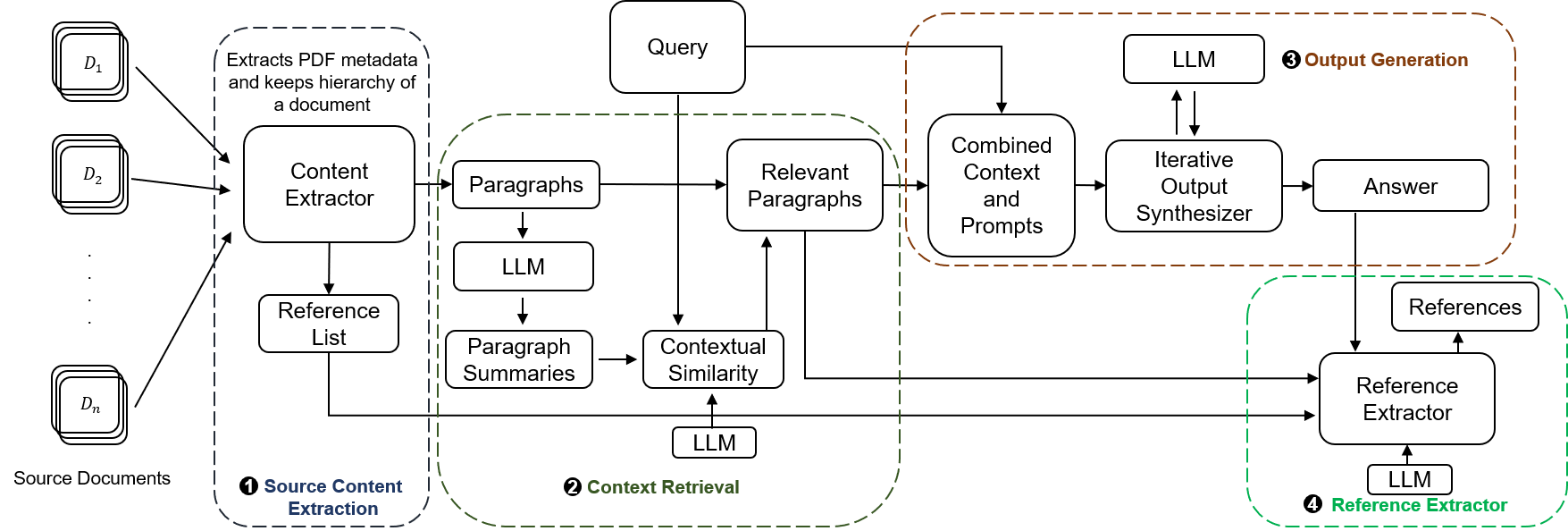
问题定义:现有技术写作辅助工具,特别是基于RAG的系统,在处理参考文献时存在不足。传统RAG方法依赖于文本分块和索引,导致检索到的信息可能不完整或与上下文脱节,影响最终生成文本的质量和参考文献的准确性。此外,长文本处理能力受限于语言模型的上下文窗口大小,难以有效整合多篇文献的信息。
核心思路:LLM-Ref的核心思路是绕过传统RAG的分块和索引步骤,直接从原始文本段落中检索和生成内容。通过直接操作文本段落,可以更精确地提取相关信息,并保留上下文的完整性。此外,采用迭代响应生成策略,将长文本分解为多个阶段进行处理,从而有效管理语言模型的上下文长度限制。
技术框架:LLM-Ref主要包含两个核心模块:段落检索模块和迭代响应生成模块。段落检索模块负责从多个源文档中检索与写作主题相关的文本段落。迭代响应生成模块则利用大语言模型,基于检索到的段落逐步生成文章内容,并在每一轮生成后更新上下文信息。整个流程循环进行,直到完成文章的撰写。
关键创新:LLM-Ref的关键创新在于其直接从文本段落进行检索和生成,以及采用迭代响应生成策略。这种方法避免了传统RAG系统中的信息损失和上下文断裂问题,从而提高了生成文本的质量和参考文献的准确性。此外,直接从生成文本中提取参考文献,简化了参考文献管理流程。
关键设计:LLM-Ref的关键设计包括:1) 使用语义相似度算法进行段落检索,确保检索到的段落与写作主题相关;2) 采用迭代响应生成策略,将长文本分解为多个阶段进行处理,并使用上下文信息指导后续生成;3) 设计了专门的参考文献提取模块,从生成文本中自动提取参考文献信息。
🖼️ 关键图片
📊 实验亮点
LLM-Ref在实验中表现出色,相较于基线RAG系统,在Ragas评分上实现了3.25倍到6.26倍的显著提升。Ragas评分综合评估了RAG系统的准确性、相关性和上下文适当性,表明LLM-Ref在生成高质量技术文档方面具有显著优势。这一结果验证了LLM-Ref方法的有效性,并展示了其在技术写作辅助领域的巨大潜力。
🎯 应用场景
LLM-Ref可应用于学术论文写作、技术报告撰写、专利申请文件生成等多种场景。它能够帮助研究人员更高效地整合多篇文献的信息,生成高质量的技术文档,并自动管理参考文献,从而节省时间和精力。未来,该工具可以进一步扩展到其他领域,例如法律文件撰写、新闻报道生成等。
📄 摘要(原文)
Large Language Models (LLMs) excel in data synthesis but can be inaccurate in domain-specific tasks, which retrieval-augmented generation (RAG) systems address by leveraging user-provided data. However, RAGs require optimization in both retrieval and generation stages, which can affect output quality. In this paper, we present LLM-Ref, a writing assistant tool that aids researchers in writing articles from multiple source documents with enhanced reference synthesis and handling capabilities. Unlike traditional RAG systems that use chunking and indexing, our tool retrieves and generates content directly from text paragraphs. This method facilitates direct reference extraction from the generated outputs, a feature unique to our tool. Additionally, our tool employs iterative response generation, effectively managing lengthy contexts within the language model's constraints. Compared to baseline RAG-based systems, our approach achieves a $3.25\times$ to $6.26\times$ increase in Ragas score, a comprehensive metric that provides a holistic view of a RAG system's ability to produce accurate, relevant, and contextually appropriate responses. This improvement shows our method enhances the accuracy and contextual relevance of writing assistance tools.