IdeaBench: Benchmarking Large Language Models for Research Idea Generation
作者: Sikun Guo, Amir Hassan Shariatmadari, Guangzhi Xiong, Albert Huang, Eric Xie, Stefan Bekiranov, Aidong Zhang
分类: cs.CL, cs.AI, cs.CE
发布日期: 2024-10-31
💡 一句话要点
IdeaBench:用于评估大语言模型生成科研想法能力的基准测试框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 科研想法生成 基准测试 科学发现 评估框架
📋 核心要点
- 现有方法缺乏对大语言模型(LLMs)在科研想法生成方面能力的全面评估框架,阻碍了对其生成能力的理解。
- IdeaBench通过构建包含数据集和评估框架的基准测试系统,标准化了LLMs生成科研想法的评估流程。
- 该框架使用GPT-4o对生成的想法进行排序,并基于“洞察力得分”量化质量指标,从而实现可扩展的个性化评估。
📝 摘要(中文)
大型语言模型(LLMs)已经改变了人与人工智能(AI)系统交互的方式,并在包括科学发现和假设生成在内的各种任务中取得了最先进的结果。然而,缺乏一个全面和系统的评估框架来评估LLMs生成科研想法的能力,这严重阻碍了我们理解和评估它们在科学发现中的生成能力。为了解决这个差距,我们提出了IdeaBench,一个基准测试系统,包括一个全面的数据集和一个评估框架,用于标准化使用LLMs生成科研想法的评估。我们的数据集包含来自各种有影响力的论文的标题和摘要,以及它们的参考文献。为了模拟人类产生科研想法的过程,我们将LLMs配置为特定领域的科研人员,并将它们置于与人类科研人员相同的背景下。这最大限度地利用了LLMs的参数知识来动态地产生新的科研想法。我们还引入了一个评估框架来评估生成的科研想法的质量。我们的评估框架是一个两阶段的过程:首先,使用GPT-4o根据用户指定的质量指标(如新颖性和可行性)对想法进行排序,从而实现可扩展的个性化;其次,基于“洞察力得分”计算相对排名,以量化所选的质量指标。所提出的基准测试系统将成为社区衡量和比较不同LLMs的宝贵资产,最终推动科学发现过程的自动化。
🔬 方法详解
问题定义:论文旨在解决缺乏系统性评估LLM生成科研想法能力的问题。现有方法无法有效衡量LLM在科学发现领域的生成能力,阻碍了该领域的进展。
核心思路:论文的核心思路是构建一个基准测试系统,包括数据集和评估框架,以标准化LLM生成科研想法的评估。通过模拟人类科研人员的思考过程,并结合领域知识,使LLM能够动态生成新的科研想法。
技术框架:IdeaBench包含以下主要模块:1) 数据集构建:收集来自不同领域有影响力的论文标题、摘要和参考文献;2) LLM配置:将LLM配置为特定领域的科研人员,并提供相应的背景知识;3) 科研想法生成:利用LLM生成新的科研想法;4) 评估框架:使用GPT-4o对生成的想法进行排序,并基于“洞察力得分”计算相对排名。
关键创新:论文的关键创新在于提出了一个完整的基准测试系统,用于评估LLM生成科研想法的能力。该系统不仅包含数据集,还包括一个两阶段的评估框架,能够根据用户指定的质量指标对想法进行排序和量化。此外,通过模拟人类科研人员的思考过程,提高了LLM生成想法的质量。
关键设计:评估框架的关键设计包括:1) 使用GPT-4o作为排序器,根据用户指定的质量指标(如新颖性和可行性)对想法进行排序;2) 定义“洞察力得分”作为量化质量指标的指标,用于计算相对排名;3) 通过提供论文标题、摘要和参考文献作为背景知识,引导LLM生成更具针对性的科研想法。
🖼️ 关键图片
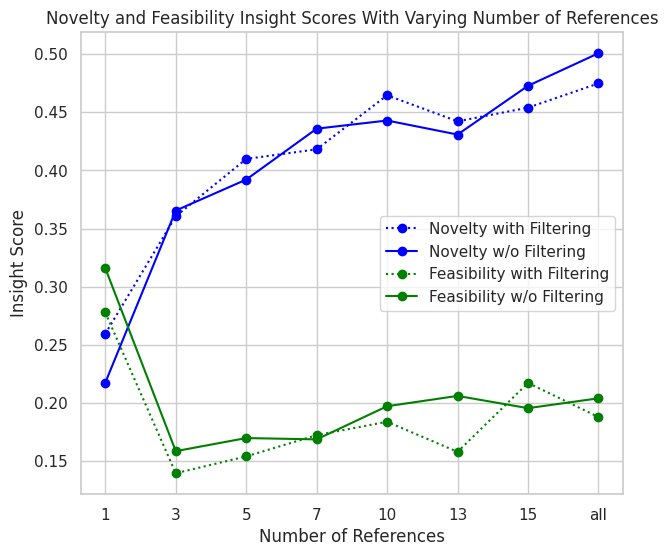
📊 实验亮点
论文提出了IdeaBench基准测试系统,并使用GPT-4o对生成的科研想法进行排序和评估。通过“洞察力得分”量化了想法的质量,并展示了该系统在评估LLM生成科研想法能力方面的有效性。具体的性能数据和对比基线将在后续实验中给出。
🎯 应用场景
IdeaBench可应用于自动化科学发现流程,辅助科研人员进行头脑风暴,加速科研创新。该基准测试系统能够帮助研究人员评估和比较不同LLM在科研想法生成方面的能力,从而推动LLM在科学领域的应用。未来,该系统可扩展到其他科学领域,并与其他AI工具集成,形成更强大的科学发现平台。
📄 摘要(原文)
Large Language Models (LLMs) have transformed how people interact with artificial intelligence (AI) systems, achieving state-of-the-art results in various tasks, including scientific discovery and hypothesis generation. However, the lack of a comprehensive and systematic evaluation framework for generating research ideas using LLMs poses a significant obstacle to understanding and assessing their generative capabilities in scientific discovery. To address this gap, we propose IdeaBench, a benchmark system that includes a comprehensive dataset and an evaluation framework for standardizing the assessment of research idea generation using LLMs. Our dataset comprises titles and abstracts from a diverse range of influential papers, along with their referenced works. To emulate the human process of generating research ideas, we profile LLMs as domain-specific researchers and ground them in the same context considered by human researchers. This maximizes the utilization of the LLMs' parametric knowledge to dynamically generate new research ideas. We also introduce an evaluation framework for assessing the quality of generated research ideas. Our evaluation framework is a two-stage process: first, using GPT-4o to rank ideas based on user-specified quality indicators such as novelty and feasibility, enabling scalable personalization; and second, calculating relative ranking based "Insight Score" to quantify the chosen quality indicator. The proposed benchmark system will be a valuable asset for the community to measure and compare different LLMs, ultimately advancing the automation of the scientific discovery process.