Scaling Up Membership Inference: When and How Attacks Succeed on Large Language Models
作者: Haritz Puerto, Martin Gubri, Sangdoo Yun, Seong Joon Oh
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-31 (更新: 2025-02-03)
备注: Findings of NAACL 2025. Our code is available at https://github.com/parameterlab/mia-scaling
💡 一句话要点
提出基于多文档聚合的成员推断攻击方法,成功攻破大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 大型语言模型 数据集推断 隐私风险 模型安全
📋 核心要点
- 现有成员推断攻击方法在大型语言模型上效果不佳,容易受到实验设置的影响,存在可利用的捷径。
- 通过聚合多个文档的成员推断特征,提升攻击的有效性,从而实现对大型语言模型的成功攻击。
- 构建了新的基准测试,用于评估MIA在不同数据规模下的性能,并验证了所提出方法的有效性。
📝 摘要(中文)
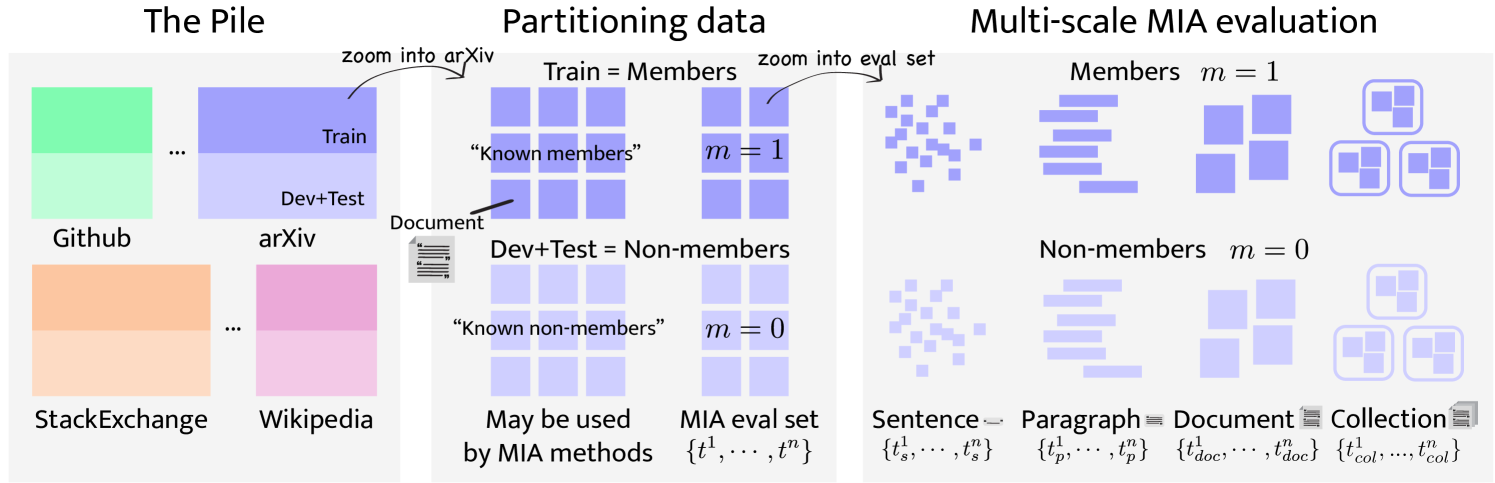
成员推断攻击(MIA)旨在验证给定数据样本是否属于模型的训练集。随着大型语言模型(LLM)的快速发展,MIA变得越来越重要。许多人关注LLM训练中是否使用了受版权保护的材料,并呼吁开发检测此类使用的方法。然而,最近的研究表明,当前的MIA方法在LLM上效果不佳,即使有效,也往往是由于实验设置不合理,存在允许“作弊”的捷径特征。本文提出,MIA在LLM上仍然有效,但前提是提供多个文档进行测试。我们构建了新的基准,用于衡量MIA在连续数据样本尺度上的性能,从句子(n-gram)到文档集合(多个token块)。为了验证当前MIA方法在更大尺度上的有效性,我们改编了最近关于数据集推断(DI)的工作,将其用于二元成员检测任务,该方法聚合段落级别的MIA特征,以实现文档和文档集合级别的MIA。该基线首次成功地对预训练和微调的LLM进行了MIA攻击。
🔬 方法详解
问题定义:论文旨在解决现有成员推断攻击(MIA)方法在大型语言模型(LLM)上失效的问题。现有方法要么依赖于不合理的实验设置,利用了“作弊”的捷径特征,要么无法有效聚合多个数据样本的信息,导致攻击效果不佳。因此,如何设计一种有效的MIA方法,能够在真实场景下成功攻击LLM,是本文要解决的核心问题。
核心思路:论文的核心思路是,通过聚合多个文档的MIA特征来提升攻击的有效性。单个句子或段落可能不足以暴露LLM的训练数据信息,但多个文档的组合可以提供更强的信号。因此,论文借鉴数据集推断(DI)的思想,将段落级别的MIA特征聚合到文档和文档集合级别,从而实现更有效的MIA攻击。
技术框架:整体框架包含以下几个主要步骤:1) 准备训练集和测试集,包括成员数据(来自LLM训练集)和非成员数据(未出现在训练集中)。2) 对每个数据样本(句子、段落或文档)提取MIA特征。3) 将段落级别的MIA特征聚合到文档和文档集合级别。4) 使用聚合后的特征训练一个二元分类器,用于区分成员数据和非成员数据。5) 评估分类器的性能,包括准确率、精确率、召回率等指标。
关键创新:论文最重要的技术创新点在于,将数据集推断(DI)的思想应用于成员推断攻击(MIA),通过聚合多个文档的MIA特征来提升攻击的有效性。与现有方法相比,该方法能够更好地利用LLM的训练数据信息,从而实现更成功的攻击。此外,论文还构建了新的基准测试,用于评估MIA在不同数据规模下的性能。
关键设计:论文的关键设计包括:1) 如何选择合适的MIA特征,例如困惑度、损失值等。2) 如何设计有效的聚合方法,将段落级别的MIA特征聚合到文档和文档集合级别。3) 如何选择合适的二元分类器,例如逻辑回归、支持向量机等。4) 如何设置合适的超参数,例如学习率、正则化系数等。具体参数设置未知,需要参考论文具体实现。
🖼️ 关键图片


📊 实验亮点
该研究首次成功地对预训练和微调的LLM进行了MIA攻击,证明了在合适的条件下,MIA仍然可以有效威胁LLM的隐私。通过聚合多个文档的MIA特征,攻击的准确率得到了显著提升,具体提升幅度未知,需要参考论文中的实验数据。该研究结果表明,LLM的隐私保护仍然面临挑战,需要进一步的研究和改进。
🎯 应用场景
该研究成果可应用于评估大型语言模型的隐私风险,检测模型训练中是否使用了受版权保护的材料。通过模拟攻击,可以发现模型的潜在漏洞,并采取相应的防御措施,例如差分隐私训练、对抗训练等。此外,该研究还可以促进对LLM训练数据来源的追溯,从而更好地保护数据所有者的权益。
📄 摘要(原文)
Membership inference attacks (MIA) attempt to verify the membership of a given data sample in the training set for a model. MIA has become relevant in recent years, following the rapid development of large language models (LLM). Many are concerned about the usage of copyrighted materials for training them and call for methods for detecting such usage. However, recent research has largely concluded that current MIA methods do not work on LLMs. Even when they seem to work, it is usually because of the ill-designed experimental setup where other shortcut features enable "cheating." In this work, we argue that MIA still works on LLMs, but only when multiple documents are presented for testing. We construct new benchmarks that measure the MIA performances at a continuous scale of data samples, from sentences (n-grams) to a collection of documents (multiple chunks of tokens). To validate the efficacy of current MIA approaches at greater scales, we adapt a recent work on Dataset Inference (DI) for the task of binary membership detection that aggregates paragraph-level MIA features to enable MIA at document and collection of documents level. This baseline achieves the first successful MIA on pre-trained and fine-tuned LLMs.