Teaching Embodied Reinforcement Learning Agents: Informativeness and Diversity of Language Use
作者: Jiajun Xi, Yinong He, Jianing Yang, Yinpei Dai, Joyce Chai
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.RO
发布日期: 2024-10-31
备注: EMNLP 2024 Main. Project website: https://github.com/sled-group/Teachable_RL
🔗 代码/项目: GITHUB
💡 一句话要点
研究语言信息性和多样性对具身强化学习Agent的影响,提升泛化性和适应性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 具身强化学习 自然语言交互 语言信息性 语言多样性 Agent学习
📋 核心要点
- 现有具身Agent通常采用简单的低级指令作为语言输入,无法反映自然的人类交流方式,限制了其学习能力。
- 本文研究语言信息性(反馈与指导)和多样性(表达变化)对Agent学习的影响,旨在提升Agent的泛化性和适应性。
- 实验结果表明,使用多样化和信息丰富的语言反馈训练的Agent,在多个RL基准测试中表现出更强的泛化能力和快速适应新任务的能力。
📝 摘要(中文)
本文研究了不同类型的语言输入如何促进具身强化学习(RL)Agent的学习。具体而言,我们考察了语言信息性(即对过去行为的反馈和未来指导)和多样性(即语言表达的变化)的不同水平如何影响Agent的学习和推理。基于四个RL基准的实验结果表明,使用多样化和信息丰富的语言反馈训练的Agent可以实现更强的泛化能力和对新任务的快速适应。这些发现突出了语言在开放世界中教授具身Agent新任务的关键作用。项目网站:https://github.com/sled-group/Teachable_RL
🔬 方法详解
问题定义:现有具身强化学习Agent主要依赖简单的低级指令进行学习,缺乏对自然人类交流方式的有效利用。这导致Agent难以获得丰富的知识,限制了其在复杂环境中的泛化能力和适应性。因此,如何利用更丰富、更自然的语言输入来指导Agent学习是一个关键问题。
核心思路:本文的核心思路是探索语言信息性和多样性对具身强化学习Agent学习的影响。通过提供包含对过去行为的反馈和未来指导的语言信息,以及使用多样化的语言表达方式,可以帮助Agent更好地理解任务目标和环境,从而提升学习效率和泛化能力。
技术框架:本文的技术框架主要包括以下几个部分:首先,定义了语言信息性和多样性的不同水平。然后,设计了相应的实验环境和任务,用于评估不同语言输入对Agent学习的影响。最后,使用强化学习算法训练Agent,并分析其在不同语言输入下的表现。整体流程是:定义语言属性 -> 构建实验环境 -> 强化学习训练 -> 结果分析。
关键创新:本文的关键创新在于系统性地研究了语言信息性和多样性对具身强化学习Agent的影响。以往的研究主要关注简单的指令输入,而本文则深入探讨了更丰富的语言表达方式,并提出了相应的评估指标。这种对语言在具身智能中的作用的深入理解,为未来的研究提供了新的方向。
关键设计:论文中,语言信息性通过提供对Agent行为的反馈(例如“你走对了”)和未来指导(例如“你应该左转”)来实现。语言多样性则通过使用不同的表达方式来描述相同的动作或状态来实现。具体的参数设置和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

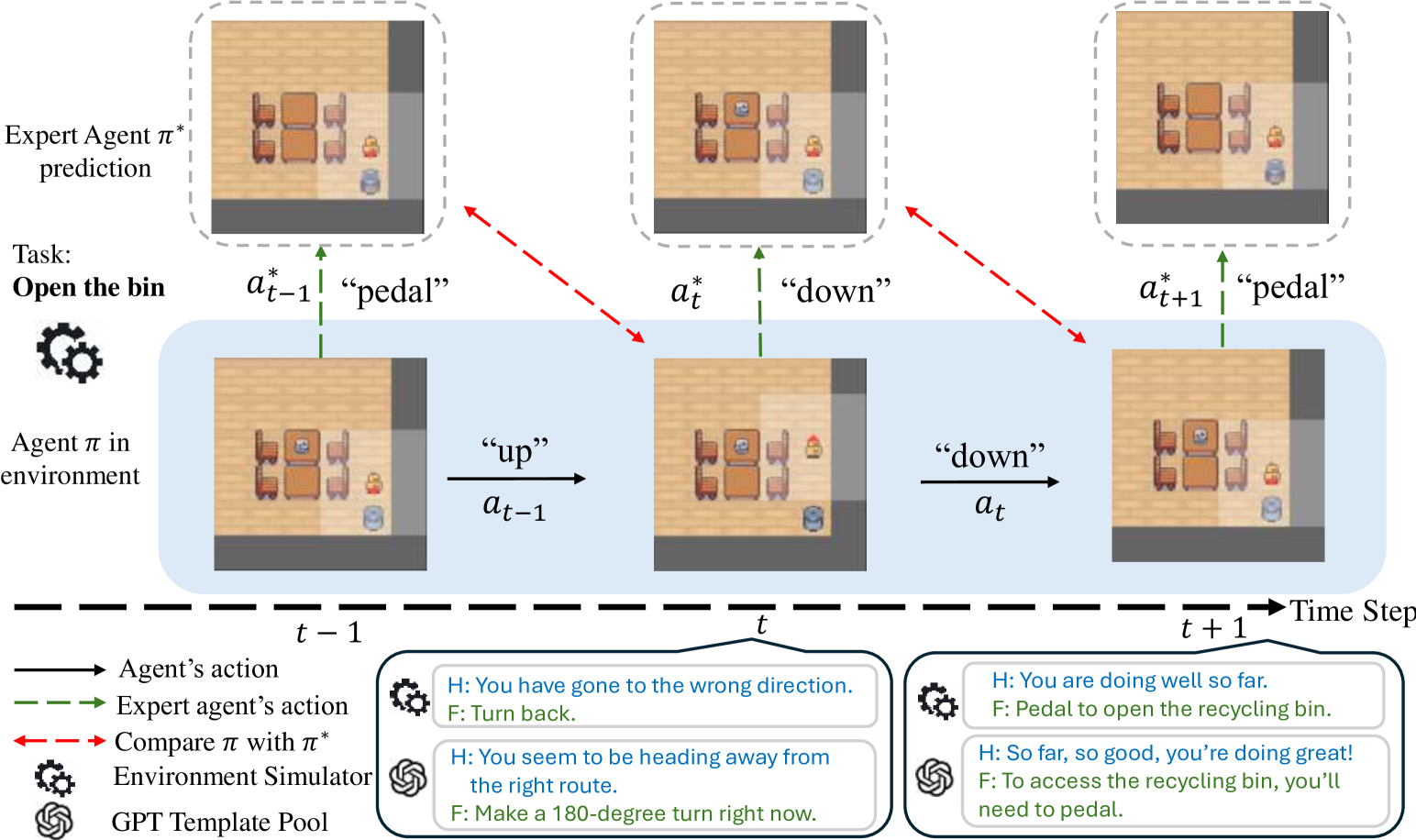
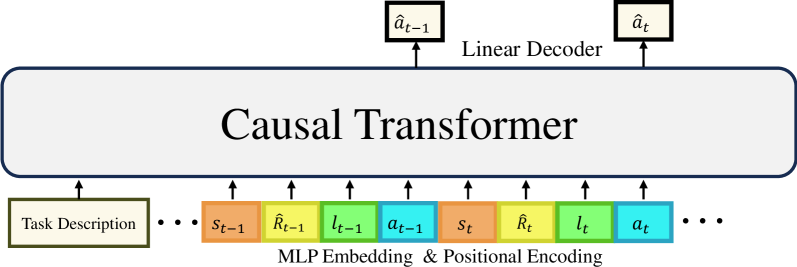
📊 实验亮点
实验结果表明,使用多样化和信息丰富的语言反馈训练的Agent,在四个RL基准测试中表现出更强的泛化能力和快速适应新任务的能力。具体性能提升数据和对比基线在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、人机协作等领域。通过利用自然语言进行更有效的任务指导,可以显著提升Agent在复杂环境中的自主性和适应性,实现更智能、更人性化的人机交互。
📄 摘要(原文)
In real-world scenarios, it is desirable for embodied agents to have the ability to leverage human language to gain explicit or implicit knowledge for learning tasks. Despite recent progress, most previous approaches adopt simple low-level instructions as language inputs, which may not reflect natural human communication. It's not clear how to incorporate rich language use to facilitate task learning. To address this question, this paper studies different types of language inputs in facilitating reinforcement learning (RL) embodied agents. More specifically, we examine how different levels of language informativeness (i.e., feedback on past behaviors and future guidance) and diversity (i.e., variation of language expressions) impact agent learning and inference. Our empirical results based on four RL benchmarks demonstrate that agents trained with diverse and informative language feedback can achieve enhanced generalization and fast adaptation to new tasks. These findings highlight the pivotal role of language use in teaching embodied agents new tasks in an open world. Project website: https://github.com/sled-group/Teachable_RL