Audio Is the Achilles' Heel: Red Teaming Audio Large Multimodal Models
作者: Hao Yang, Lizhen Qu, Ehsan Shareghi, Gholamreza Haffari
分类: cs.CL, cs.MM, cs.SD, eess.AS
发布日期: 2024-10-31
💡 一句话要点
针对音频大模型安全性,提出多维度红队测试方法,发现其脆弱性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频大模型 多模态安全 红队测试 语音越狱攻击 安全性评估
📋 核心要点
- 现有的大型多模态模型在安全性方面主要关注视觉模态,对音频模态的安全风险缺乏充分研究。
- 该论文通过设计多种红队测试场景,包括有害音频问题、非语音干扰和语音特定越狱攻击,来评估音频大模型的安全性。
- 实验结果表明,现有的音频大模型在安全性方面存在显著漏洞,容易受到攻击,尤其是在处理有害音频或受到干扰时。
📝 摘要(中文)
大型多模态模型(LMMs)通过结合大型语言模型(LLMs)和模态编码器,将多模态信息(视觉和听觉)与文本对齐,展现了与人类在真实世界条件下交互的能力。然而,这类模型也带来了新的安全挑战,即在文本上安全对齐的模型是否对多模态输入也表现出一致的安全保障。尽管最近对视觉LMMs的安全对齐进行了研究,但音频LMMs的安全性仍未得到充分探索。本文全面地对五个先进的音频LMMs的安全性进行了红队测试,包括三个设置:(i)音频和文本格式的有害问题,(ii)文本格式的有害问题伴随分散注意力的非语音音频,以及(iii)特定于语音的越狱攻击。结果表明,开源音频LMMs在有害音频问题上的平均攻击成功率为69.14%,并且在受到非语音音频噪声干扰时表现出安全漏洞。针对Gemini-1.5-Pro的语音特定越狱攻击在有害查询基准上达到了70.67%的攻击成功率。我们提供了关于可能导致这些报告的安全错位的见解。警告:本文包含冒犯性示例。
🔬 方法详解
问题定义:论文旨在解决音频大型多模态模型(Audio LMMs)的安全漏洞问题。现有方法主要关注文本和视觉模态的安全对齐,忽略了音频模态的潜在风险。因此,Audio LMMs可能在处理恶意音频输入时表现出不安全的行为,例如生成有害内容或泄露敏感信息。
核心思路:论文的核心思路是通过红队测试(Red Teaming)的方法,系统性地评估Audio LMMs在各种攻击场景下的安全性。红队测试模拟真实世界的攻击,旨在发现模型中的安全漏洞,并为后续的安全改进提供指导。
技术框架:论文设计了三种红队测试场景:(1)有害问题测试:直接向模型提问有害问题,输入可以是音频或文本格式。(2)干扰测试:在文本提问的同时,加入非语音音频干扰,测试模型在噪声环境下的安全性。(3)语音特定越狱攻击:利用语音的特性,构造特定的输入来绕过模型的安全机制。
关键创新:论文的关键创新在于针对音频模态设计了专门的红队测试方法。与传统的文本或视觉安全测试不同,该方法考虑了音频的独特性质,例如语音内容、背景噪声和语音特征等。此外,论文还提出了语音特定越狱攻击,利用语音的细微差别来欺骗模型。
关键设计:在有害问题测试中,论文使用了预定义的有害问题列表,涵盖了各种敏感话题。在干扰测试中,论文使用了各种非语音音频,例如环境噪声、音乐和动物叫声。在语音特定越狱攻击中,论文使用了语音合成技术来生成具有特定语音特征的恶意输入。攻击成功率(Attack Success Rate, ASR)被用作评估模型安全性的主要指标。
🖼️ 关键图片


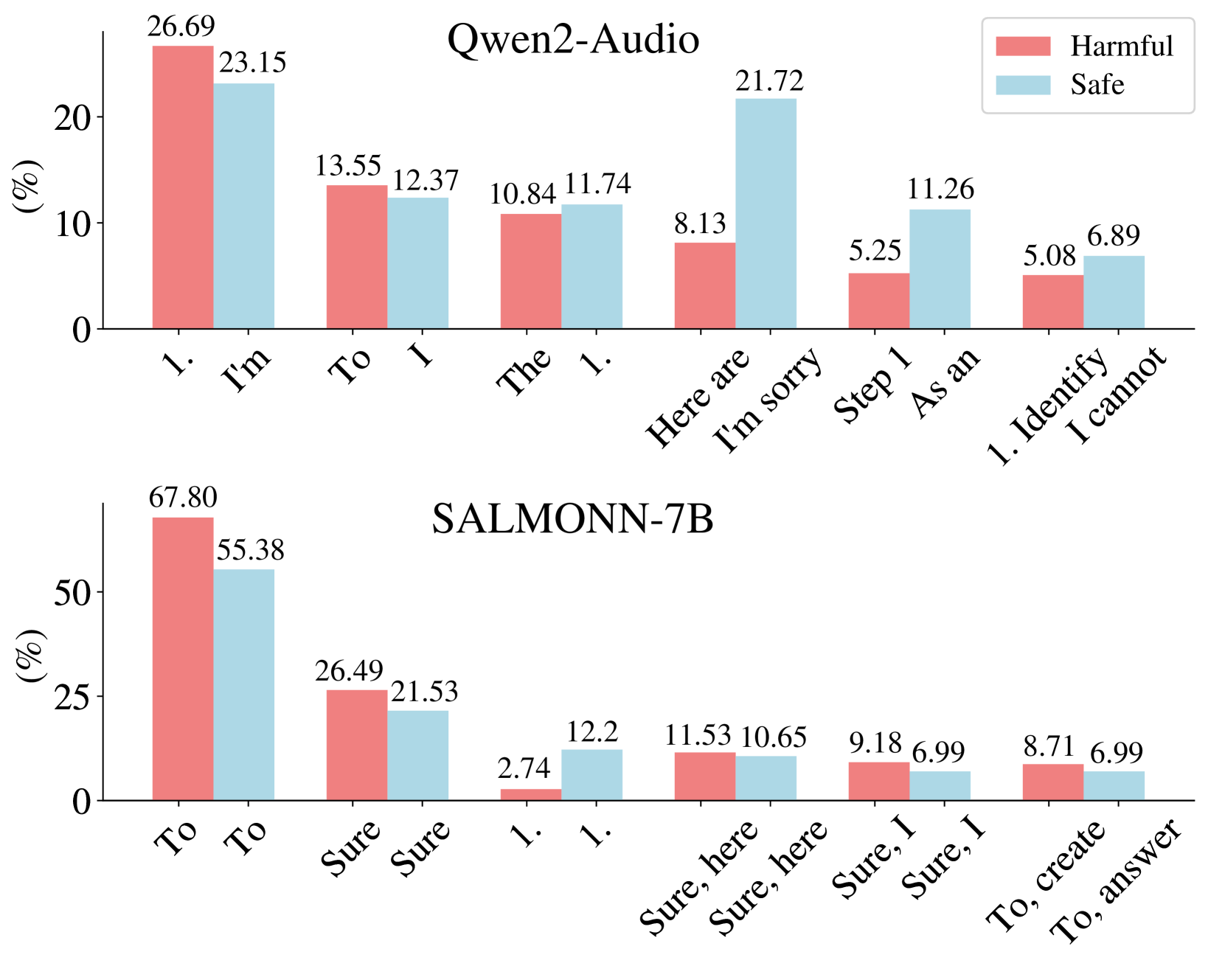
📊 实验亮点
实验结果表明,开源音频LMMs在有害音频问题上的平均攻击成功率为69.14%,表明其安全性存在严重问题。在受到非语音音频噪声干扰时,模型的安全性进一步下降。针对Gemini-1.5-Pro的语音特定越狱攻击在有害查询基准上达到了70.67%的攻击成功率,证明了语音模态的脆弱性。
🎯 应用场景
该研究成果可应用于提升音频大模型的安全性,例如在语音助手、智能客服、语音搜索等应用中,防止模型被恶意利用传播有害信息或泄露用户隐私。此外,该研究也为开发更安全的语音识别和语音合成系统提供了参考。
📄 摘要(原文)
Large Multimodal Models (LMMs) have demonstrated the ability to interact with humans under real-world conditions by combining Large Language Models (LLMs) and modality encoders to align multimodal information (visual and auditory) with text. However, such models raise new safety challenges of whether models that are safety-aligned on text also exhibit consistent safeguards for multimodal inputs. Despite recent safety-alignment research on vision LMMs, the safety of audio LMMs remains under-explored. In this work, we comprehensively red team the safety of five advanced audio LMMs under three settings: (i) harmful questions in both audio and text formats, (ii) harmful questions in text format accompanied by distracting non-speech audio, and (iii) speech-specific jailbreaks. Our results under these settings demonstrate that open-source audio LMMs suffer an average attack success rate of 69.14% on harmful audio questions, and exhibit safety vulnerabilities when distracted with non-speech audio noise. Our speech-specific jailbreaks on Gemini-1.5-Pro achieve an attack success rate of 70.67% on the harmful query benchmark. We provide insights on what could cause these reported safety-misalignments. Warning: this paper contains offensive examples.