What is Wrong with Perplexity for Long-context Language Modeling?
作者: Lizhe Fang, Yifei Wang, Zhaoyang Liu, Chenheng Zhang, Stefanie Jegelka, Jinyang Gao, Bolin Ding, Yisen Wang
分类: cs.CL, cs.LG
发布日期: 2024-10-31 (更新: 2025-07-27)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LongPPL指标与LongCE损失,解决长文本建模中困惑度指标失效问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 困惑度指标 关键Token识别 对比学习 语言模型评估
📋 核心要点
- 现有长文本语言模型依赖困惑度(PPL)评估,但PPL无法有效衡量模型在长文本理解中的关键信息捕获能力。
- 论文提出LongPPL指标,通过长短文本对比识别关键token,并以此为基础评估模型性能,更准确反映长文本理解能力。
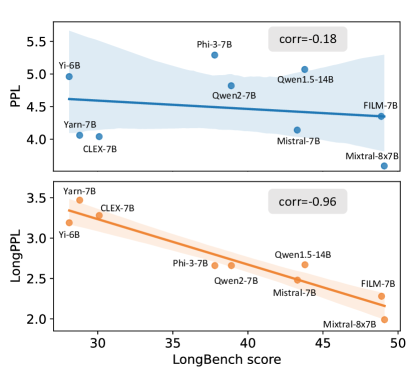
- 实验表明LongPPL与长文本任务性能高度相关,优于传统PPL。同时,提出的LongCE损失函数能有效提升模型性能。
📝 摘要(中文)
处理长上下文输入对于大型语言模型(LLMs)在诸如扩展对话、文档摘要和多样本上下文学习等任务中至关重要。尽管最近的方法已经扩展了LLMs的上下文窗口并采用困惑度(PPL)作为标准评估指标,但PPL已被证明在评估长上下文能力方面不可靠。这种局限性的根本原因尚不清楚。本文对此问题提供了全面的解释。我们发现PPL通过平均所有token而忽略了对于长上下文理解至关重要的关键token,从而掩盖了模型在长上下文场景中的真实性能。为了解决这个问题,我们提出了一种新的指标 extbf{LongPPL},它通过采用长短上下文对比方法来识别关键token,从而关注这些关键token。我们的实验表明,LongPPL与各种长上下文基准测试的性能密切相关(例如,Pearson相关系数为-0.96),在预测准确性方面明显优于传统的PPL。此外,我们还引入了 extbf{LongCE}(长上下文交叉熵)损失,这是一种用于微调的重加权策略,可优先考虑关键token,从而在各种基准测试中实现一致的改进。总而言之,这些贡献为PPL的局限性提供了更深入的见解,并为准确评估和增强LLMs的长上下文能力提供了有效的解决方案。
🔬 方法详解
问题定义:现有大型语言模型在处理长文本时,通常使用困惑度(PPL)作为评估指标。然而,PPL 对所有 token 一视同仁,无法区分关键 token 和非关键 token,导致其在长文本场景下无法准确反映模型的真实性能。尤其是在长文本理解任务中,一些关键 token 往往决定了模型的理解质量,PPL 的平均化处理会掩盖模型对这些关键信息的捕获能力。因此,如何设计一种更有效的指标来评估模型在长文本场景下的性能,是本文要解决的核心问题。
核心思路:论文的核心思路是,通过识别长文本中的关键 token,并更加关注这些 token 的预测准确性,从而更准确地评估模型在长文本场景下的性能。具体来说,论文提出了一种长短文本对比的方法来识别关键 token。其基本假设是,如果一个 token 在长文本上下文中比在短文本上下文中更重要,那么它就是一个关键 token。基于此,论文设计了一种新的指标 LongPPL,该指标通过对关键 token 赋予更高的权重,从而更准确地反映模型在长文本场景下的性能。
技术框架:LongPPL 的计算流程主要包括以下几个步骤:1. 关键 token 识别:使用长短文本对比的方法,计算每个 token 的重要性得分。具体来说,对于每个 token,计算其在长文本上下文和短文本上下文中的概率分布差异。差异越大,说明该 token 在长文本上下文中越重要。2. 权重分配:根据 token 的重要性得分,为其分配权重。重要性得分越高的 token,权重越高。3. LongPPL 计算:使用加权交叉熵损失函数,计算 LongPPL。具体来说,对于每个 token,将其交叉熵损失乘以其权重,然后将所有 token 的加权交叉熵损失求和,得到 LongPPL。此外,论文还提出了 LongCE 损失函数,用于微调模型。LongCE 损失函数与 LongPPL 的计算方式类似,也是通过对关键 token 赋予更高的权重来训练模型。
关键创新:论文最重要的技术创新点在于提出了长短文本对比的方法来识别关键 token。与传统的 PPL 指标相比,LongPPL 能够更加关注长文本中的关键信息,从而更准确地评估模型在长文本场景下的性能。此外,LongCE 损失函数也能够有效地提升模型在长文本任务上的性能。
关键设计:在关键 token 识别方面,论文使用了 KL 散度来衡量 token 在长短文本上下文中的概率分布差异。在权重分配方面,论文使用了 softmax 函数将 token 的重要性得分转换为权重。在 LongCE 损失函数方面,论文使用了与 LongPPL 相同的权重分配策略。这些设计细节都对 LongPPL 和 LongCE 的性能起到了关键作用。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LongPPL 与长文本基准测试的性能具有很强的相关性(Pearson 相关系数为 -0.96),显著优于传统的 PPL 指标。此外,使用 LongCE 损失函数进行微调后,模型在各种长文本任务上的性能都得到了显著提升。例如,在某些任务上,模型的准确率提升了 5% 以上。
🎯 应用场景
该研究成果可应用于各种需要处理长文本输入的场景,例如长篇文档摘要、多轮对话、代码生成等。通过使用 LongPPL 指标,可以更准确地评估模型在这些场景下的性能,从而更好地选择和优化模型。LongCE 损失函数则可以帮助提升模型在长文本任务上的性能,提高模型的实用价值。未来,该研究可以进一步扩展到其他模态,例如长视频理解、长音频处理等。
📄 摘要(原文)
Handling long-context inputs is crucial for large language models (LLMs) in tasks such as extended conversations, document summarization, and many-shot in-context learning. While recent approaches have extended the context windows of LLMs and employed perplexity (PPL) as a standard evaluation metric, PPL has proven unreliable for assessing long-context capabilities. The underlying cause of this limitation has remained unclear. In this work, we provide a comprehensive explanation for this issue. We find that PPL overlooks key tokens, which are essential for long-context understanding, by averaging across all tokens and thereby obscuring the true performance of models in long-context scenarios. To address this, we propose \textbf{LongPPL}, a novel metric that focuses on key tokens by employing a long-short context contrastive method to identify them. Our experiments demonstrate that LongPPL strongly correlates with performance on various long-context benchmarks (e.g., Pearson correlation of -0.96), significantly outperforming traditional PPL in predictive accuracy. Additionally, we introduce \textbf{LongCE} (Long-context Cross-Entropy) loss, a re-weighting strategy for fine-tuning that prioritizes key tokens, leading to consistent improvements across diverse benchmarks. In summary, these contributions offer deeper insights into the limitations of PPL and present effective solutions for accurately evaluating and enhancing the long-context capabilities of LLMs. Code is available at https://github.com/PKU-ML/LongPPL.