Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
作者: Chenyang An, Shima Imani, Feng Yao, Chengyu Dong, Ali Abbasi, Harsh Shrivastava, Samuel Buss, Jingbo Shang, Gayathri Mahalingam, Pramod Sharma, Maurice Diesendruck
分类: cs.CL, cs.AI
发布日期: 2024-10-30 (更新: 2025-07-03)
💡 一句话要点
针对LLM证明生成,论文提出直观序列数据排序以提升模型训练效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 证明生成 数据排序 直观序列顺序 定理证明
📋 核心要点
- 现有LLM在证明生成任务中表现不佳,部分原因是训练数据中证明步骤的排序并非最优。
- 论文提出“直观序列顺序”的概念,即中间监督信息位于对应证明步骤之前,以优化训练数据。
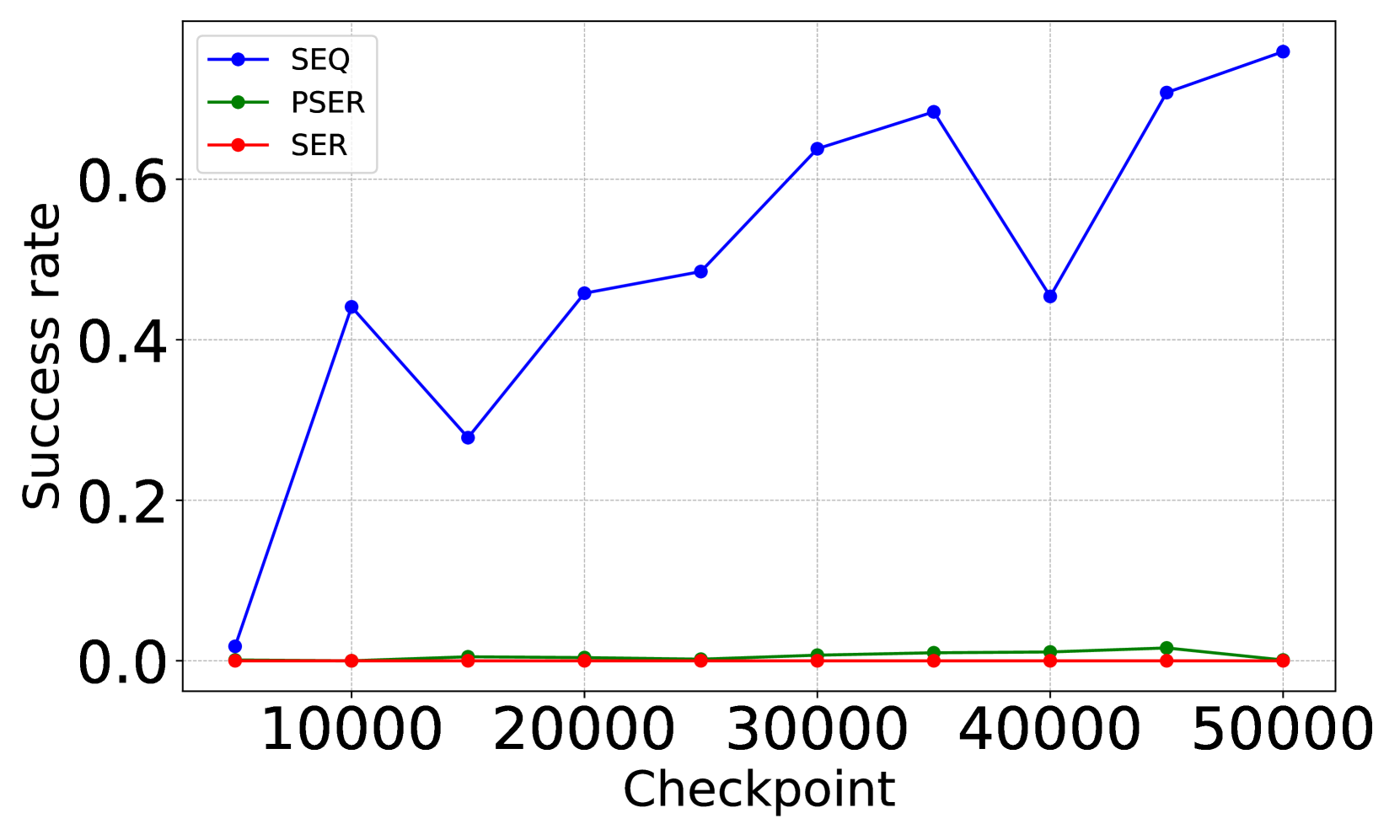
- 实验表明,使用直观序列顺序训练的模型在证明成功率上显著优于使用其他顺序训练的模型。
📝 摘要(中文)
在大语言模型(LLM)的证明生成领域,尽管在ArXiv等大型数据集上进行了广泛的训练,LLM在解决中等难度的证明任务时仍然表现平平。我们认为,这部分是由于训练中使用的每个证明数据内部存在次优排序。例如,已发表的证明通常遵循纯粹的逻辑顺序,其中每个步骤都基于演绎规则从先前的步骤逻辑地进行。这种顺序旨在方便验证证明的合理性,而不是帮助人们和模型学习证明的发现过程。在证明生成中,我们认为一个训练数据样本的最佳顺序是,证明中特定步骤的相关中间监督总是位于该步骤的左侧。我们将这种顺序称为直观序列顺序。我们使用直觉主义命题逻辑定理证明和数字乘法两个任务验证了我们的主张。我们的实验验证了顺序效应,并为我们的解释提供了支持。我们证明,当证明以直观序列顺序排列时,训练效果最佳。此外,顺序效应以及在不同数据顺序上训练的模型之间的性能差距可能很大——在命题逻辑定理证明任务中,在最佳顺序上训练的模型与最差顺序相比,证明成功率提高了11%。最后,我们定义了高等数学证明中一种常见的顺序问题,并发现一本广泛使用的研究生数学教科书的前两章中,有17.3%的具有非平凡证明的定理存在这个问题。附录中提供了这些证明的详细列表。
🔬 方法详解
问题定义:论文旨在解决大语言模型在证明生成任务中表现不佳的问题。现有方法通常使用逻辑顺序的证明数据进行训练,这种顺序更侧重于验证证明的正确性,而非帮助模型学习证明的发现过程。因此,模型难以有效地学习到生成证明所需的策略和直觉。
核心思路:论文的核心思路是,训练数据的排序方式对LLM的学习效果有显著影响。最佳的排序方式应该能够提供逐步的、直观的指导,帮助模型理解证明的构建过程。因此,论文提出了“直观序列顺序”的概念,即对于证明中的每个步骤,其相关的中间监督信息(例如,推导所需的中间结论或提示)应该位于该步骤之前。
技术框架:论文通过实验验证了数据排序对模型性能的影响。具体而言,论文使用了两个任务:直觉主义命题逻辑定理证明和数字乘法。对于每个任务,论文构建了不同排序方式的训练数据集,包括最佳的“直观序列顺序”和最差的排序方式。然后,论文使用这些数据集训练LLM,并比较它们在证明生成任务中的性能。
关键创新:论文的关键创新在于提出了“直观序列顺序”的概念,并证明了其在LLM证明生成任务中的有效性。与传统的逻辑顺序相比,直观序列顺序更符合人类解决问题的思维方式,能够帮助模型更好地学习到证明的构建过程。
关键设计:在实验设计方面,论文精心选择了两个具有代表性的证明生成任务,并构建了不同排序方式的训练数据集。论文还详细分析了高等数学教材中存在的排序问题,进一步验证了“直观序列顺序”的重要性。具体的模型架构和超参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用“直观序列顺序”训练的模型在命题逻辑定理证明任务中,证明成功率比使用最差顺序训练的模型提高了11%。这表明数据排序方式对LLM的性能有显著影响,优化数据排序可以带来显著的性能提升。
🎯 应用场景
该研究成果可应用于提升LLM在数学、逻辑推理等领域的性能,例如自动定理证明、代码生成、问题求解等。通过优化训练数据的排序方式,可以显著提高LLM的学习效率和生成质量,使其在更复杂的任务中发挥作用。此外,该研究也为其他领域的LLM训练提供了新的思路,即关注数据内部的结构和顺序,而非仅仅依赖于数据规模。
📄 摘要(原文)
In the field of large language model (LLM)-based proof generation, despite extensive training on large datasets such as ArXiv, LLMs still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the widespread presence of suboptimal ordering within the data for each proof used in training. For example, published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. This order is designed to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders can be substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order. Lastly, we define a common type of order issue in advanced math proofs and find that 17.3 percent of theorems with nontrivial proofs in the first two chapters of a widely used graduate-level mathematics textbook suffer from this issue. A detailed list of those proofs is provided in the appendix.