Generating Diverse Negations from Affirmative Sentences
作者: Darian Rodriguez Vasquez, Afroditi Papadaki
分类: cs.CL, cs.AI
发布日期: 2024-10-30
备注: Accepted at "Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning" workshop at NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出NegVerse方法,从肯定句生成多样化的否定句,提升语言模型在否定推理方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 否定生成 自然语言处理 语言模型 数据增强 否定推理
📋 核心要点
- 现有语言模型在否定推理方面存在不足,缺乏包含复杂否定形式的训练数据。
- NegVerse通过句法结构引导的掩码和提示调优,从肯定句生成多样化的否定句。
- 实验表明,NegVerse生成的否定句在词汇相似性、句法保留和否定多样性方面优于现有方法。
📝 摘要(中文)
尽管大型语言模型在各种任务中表现出色,但它们在否定语句下的推理方面常常表现不佳。否定在实际应用中很重要,因为它们在动词短语、从句或其他表达中编码了否定极性。然而,它们在当前的基准测试中代表性不足,这些基准测试主要包括基本的否定形式,而忽略了更复杂的形式,导致训练语言模型的数据不足。在这项工作中,我们提出了NegVerse,这是一种通过从肯定句生成各种否定类型(包括英语文本中常见的动词、非动词和词缀形式)来解决否定数据集缺乏的方法。我们基于句法结构,为掩盖句子中最可能出现否定的部分提供了新的规则,并使用冻结的基线LLM和提示调优来生成否定句。我们还提出了一种过滤机制来识别否定线索并删除退化的例子,从而产生各种有意义的扰动。我们的结果表明,NegVerse优于现有方法,并生成与原始句子具有更高词汇相似性、更好句法保留和否定多样性的否定。
🔬 方法详解
问题定义:论文旨在解决语言模型在处理否定语句时表现不佳的问题。现有的否定数据集主要包含简单的否定形式,缺乏多样性和复杂性,导致语言模型在否定推理方面的能力不足。因此,需要一种方法来生成更多样化的否定语句,以提升语言模型的性能。
核心思路:论文的核心思路是利用肯定句生成多样化的否定句,从而扩充否定数据集。通过分析肯定句的句法结构,确定最有可能出现否定的位置,并使用提示调优的语言模型生成相应的否定形式。同时,采用过滤机制去除质量较差的否定句,保证生成数据的有效性。
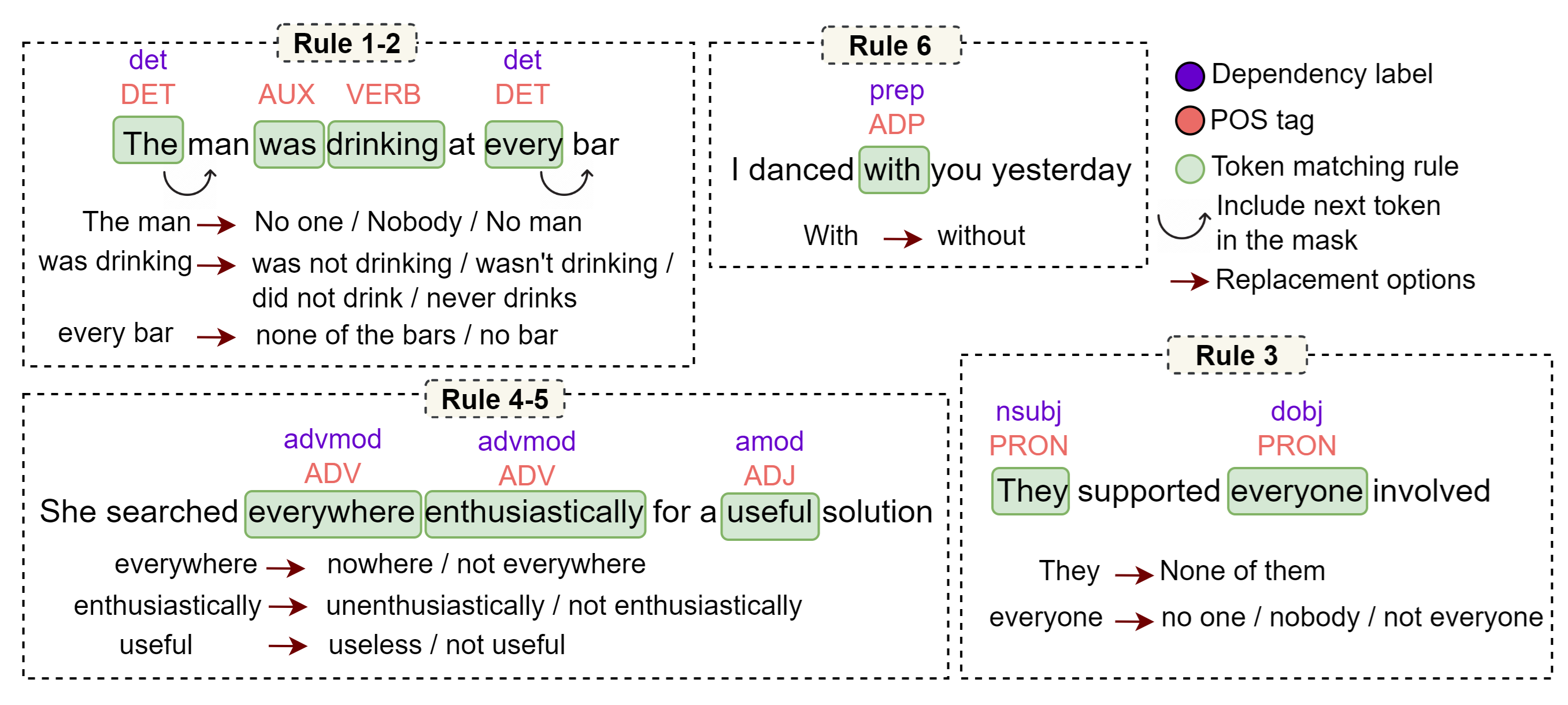
技术框架:NegVerse方法主要包含以下几个阶段:1) 句法分析:对肯定句进行句法分析,提取句法结构信息。2) 掩码生成:基于句法结构,生成掩码,确定句子中可能出现否定的位置。3) 否定生成:使用冻结的基线LLM和提示调优,根据掩码生成否定句。4) 过滤:使用过滤机制识别否定线索并删除退化的例子。
关键创新:NegVerse的关键创新在于:1) 基于句法结构的掩码生成:利用句法信息更准确地定位否定词可能出现的位置。2) 多样化的否定形式生成:不仅生成简单的否定形式,还包括动词、非动词和词缀等多种否定形式。3) 过滤机制:有效去除质量较差的否定句,保证生成数据的质量。
关键设计:论文使用预训练的语言模型作为基线模型,并通过提示调优来控制生成否定句的风格和质量。掩码生成规则基于句法依存关系,例如,优先掩盖动词、形容词和副词等。过滤机制使用正则表达式来识别否定词,并根据否定词的位置和上下文判断否定句的质量。具体的损失函数和网络结构信息未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,NegVerse方法在生成否定句方面优于现有方法。NegVerse生成的否定句与原始肯定句具有更高的词汇相似性,更好地保留了句法结构,并且具有更高的否定多样性。具体性能数据和对比基线信息未知,但论文强调了NegVerse在多个指标上的优越性。
🎯 应用场景
NegVerse生成的否定数据集可以用于训练和评估语言模型在否定推理方面的能力。该技术可应用于自然语言理解、问答系统、情感分析等领域,提高模型在处理包含否定信息的文本时的准确性和鲁棒性。未来,该方法可以扩展到其他语言,并应用于更复杂的否定形式生成。
📄 摘要(原文)
Despite the impressive performance of large language models across various tasks, they often struggle with reasoning under negated statements. Negations are important in real-world applications as they encode negative polarity in verb phrases, clauses, or other expressions. Nevertheless, they are underrepresented in current benchmarks, which mainly include basic negation forms and overlook more complex ones, resulting in insufficient data for training a language model. In this work, we propose NegVerse, a method that tackles the lack of negation datasets by producing a diverse range of negation types from affirmative sentences, including verbal, non-verbal, and affixal forms commonly found in English text. We provide new rules for masking parts of sentences where negations are most likely to occur, based on syntactic structure and use a frozen baseline LLM and prompt tuning to generate negated sentences. We also propose a filtering mechanism to identify negation cues and remove degenerate examples, producing a diverse range of meaningful perturbations. Our results show that NegVerse outperforms existing methods and generates negations with higher lexical similarity to the original sentences, better syntactic preservation and negation diversity. The code is available in https://github.com/DarianRodriguez/NegVerse