Long$^2$RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall
作者: Zehan Qi, Rongwu Xu, Zhijiang Guo, Cunxiang Wang, Hao Zhang, Wei Xu
分类: cs.CL
发布日期: 2024-10-30 (更新: 2025-01-27)
备注: Accepted to EMNLP'24 (Findings). Camera-ready version
💡 一句话要点
提出Long$^2$RAG基准和KPR指标,用于评估长文本检索增强生成模型的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 长文本处理 大型语言模型 评估基准 关键点召回
📋 核心要点
- 现有RAG评估基准缺乏对长文本处理能力的有效评估,数据集未能充分反映真实检索文档的特性。
- Long$^2$RAG基准和KPR指标旨在更全面地评估LLM在长文本检索和长篇生成任务中的性能。
- Long$^2$RAG包含多领域、多类型问题,并结合KPR指标,能够更准确地衡量LLM对检索信息的利用程度。
📝 摘要(中文)
检索增强生成(RAG)是一种有前景的方法,可以解决大型语言模型(LLM)中固定知识的局限性。然而,目前用于评估RAG系统的基准存在两个主要缺陷:(1)由于缺乏反映检索文档特征的数据集,它们未能充分衡量LLM处理长上下文检索的能力;(2)它们缺乏一种全面的评估方法来评估LLM生成长篇回复的能力,而这些回复能有效利用检索到的信息。为了解决这些缺点,我们引入了Long$^2$RAG基准和关键点召回率(KPR)指标。Long$^2$RAG包含280个问题,涵盖10个领域和8个问题类别,每个问题都与5个检索到的文档相关联,平均长度为2444个单词。KPR评估LLM将从检索文档中提取的关键点纳入其生成回复的程度,从而更细致地评估它们利用检索信息的能力。
🔬 方法详解
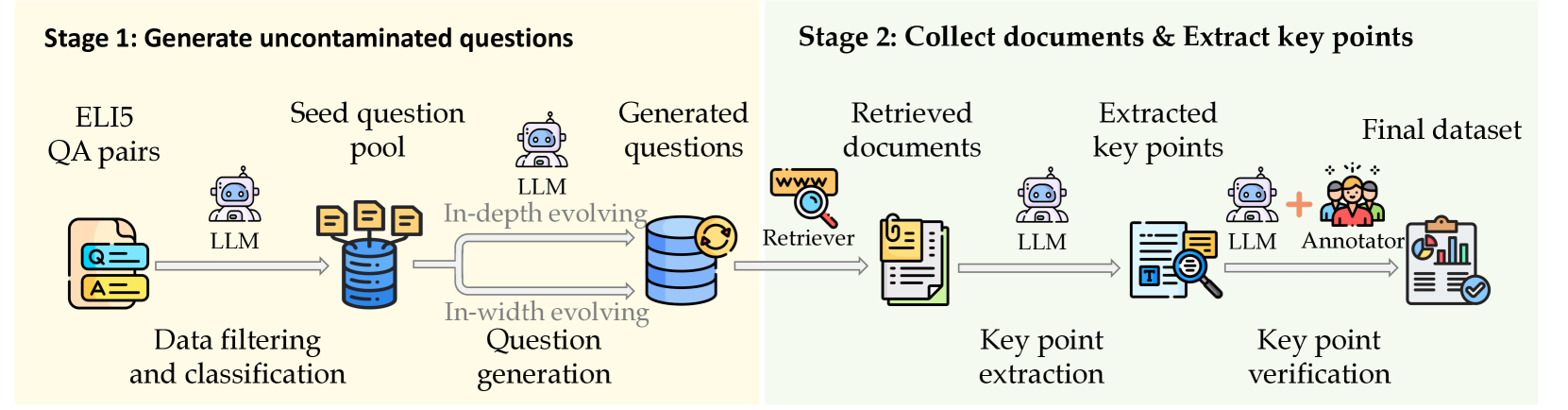
问题定义:现有RAG评估基准无法充分评估LLM在处理长上下文检索和生成长篇回复时的能力。现有数据集缺乏对检索文档特征的有效模拟,评估指标也未能准确衡量LLM对检索信息的利用程度,尤其是在长文本场景下。
核心思路:论文的核心思路是构建一个更具挑战性的长文本RAG评估基准,并设计一个更细粒度的评估指标。通过Long$^2$RAG基准提供更长的上下文和更复杂的检索场景,并通过KPR指标来衡量LLM是否能够准确地从检索文档中提取关键信息并融入到生成内容中。
技术框架:Long$^2$RAG基准包含以下几个关键组成部分:1) 一个包含280个问题的数据集,覆盖10个领域和8个问题类别;2) 每个问题关联5个检索到的文档,平均长度为2444个单词;3) 关键点召回率(KPR)指标,用于评估LLM生成回复中包含检索文档关键信息的程度。整体流程是:给定一个问题,LLM首先检索相关文档,然后基于检索到的文档生成回复,最后使用KPR指标评估生成回复的质量。
关键创新:Long$^2$RAG的关键创新在于其对长文本RAG场景的模拟和KPR指标的设计。与现有基准相比,Long$^2$RAG提供了更长的上下文和更复杂的检索场景,更贴近实际应用。KPR指标则提供了一种更细粒度的评估方法,能够更准确地衡量LLM对检索信息的利用程度。
关键设计:KPR指标的关键设计在于如何准确地提取检索文档中的关键点。具体方法未知,但推测可能使用了基于关键词提取、句子重要性排序或摘要生成等技术。此外,如何将提取的关键点与LLM生成的回复进行匹配也是一个关键设计,可能使用了基于语义相似度计算或信息检索等技术。
🖼️ 关键图片


📊 实验亮点
论文提出了Long$^2$RAG基准和KPR指标,为长文本RAG评估提供了一种新的方法。虽然论文中没有给出具体的性能数据,但通过Long$^2$RAG基准,可以更全面地评估LLM在长文本检索和生成任务中的性能,并发现现有RAG系统的不足之处。KPR指标则提供了一种更细粒度的评估方法,能够更准确地衡量LLM对检索信息的利用程度。
🎯 应用场景
该研究成果可应用于各种需要长文本检索和生成的场景,例如:智能客服、文档问答、报告生成等。通过Long$^2$RAG基准和KPR指标,可以更有效地评估和优化RAG系统,提高LLM在长文本场景下的应用效果,从而提升用户体验和工作效率。未来,该研究可以推动RAG技术在更多领域的应用。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is a promising approach to address the limitations of fixed knowledge in large language models (LLMs). However, current benchmarks for evaluating RAG systems suffer from two key deficiencies: (1) they fail to adequately measure LLMs' capability in handling long-context retrieval due to a lack of datasets that reflect the characteristics of retrieved documents, and (2) they lack a comprehensive evaluation method for assessing LLMs' ability to generate long-form responses that effectively exploits retrieved information. To address these shortcomings, we introduce the Long$^2$RAG benchmark and the Key Point Recall (KPR) metric. Long$^2$RAG comprises 280 questions spanning 10 domains and across 8 question categories, each associated with 5 retrieved documents with an average length of 2,444 words. KPR evaluates the extent to which LLMs incorporate key points extracted from the retrieved documents into their generated responses, providing a more nuanced assessment of their ability to exploit retrieved information.