Danoliteracy of Generative Large Language Models
作者: Søren Vejlgaard Holm, Lars Kai Hansen, Martin Carsten Nielsen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-30 (更新: 2025-03-04)
备注: 16 pages, 13 figures, Accepted to NoDaLiDa/Baltic-HLT 2025
期刊: Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025)
💡 一句话要点
提出Danoliteracy基准以评估丹麦语生成模型能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成模型 丹麦语 语言评估 低资源语言 基准测试 文化能力 机器学习
📋 核心要点
- 现有方法在低资源语言如丹麦语的评估上缺乏有效的量化标准,难以验证生成模型的实际能力。
- 论文提出了Danoliteracy基准,旨在通过多样化场景评估丹麦语生成模型的语言和文化能力。
- 实验结果显示,该基准与人类反馈高度相关,且模型在丹麦语场景中的表现受一致性因素的影响显著。
📝 摘要(中文)
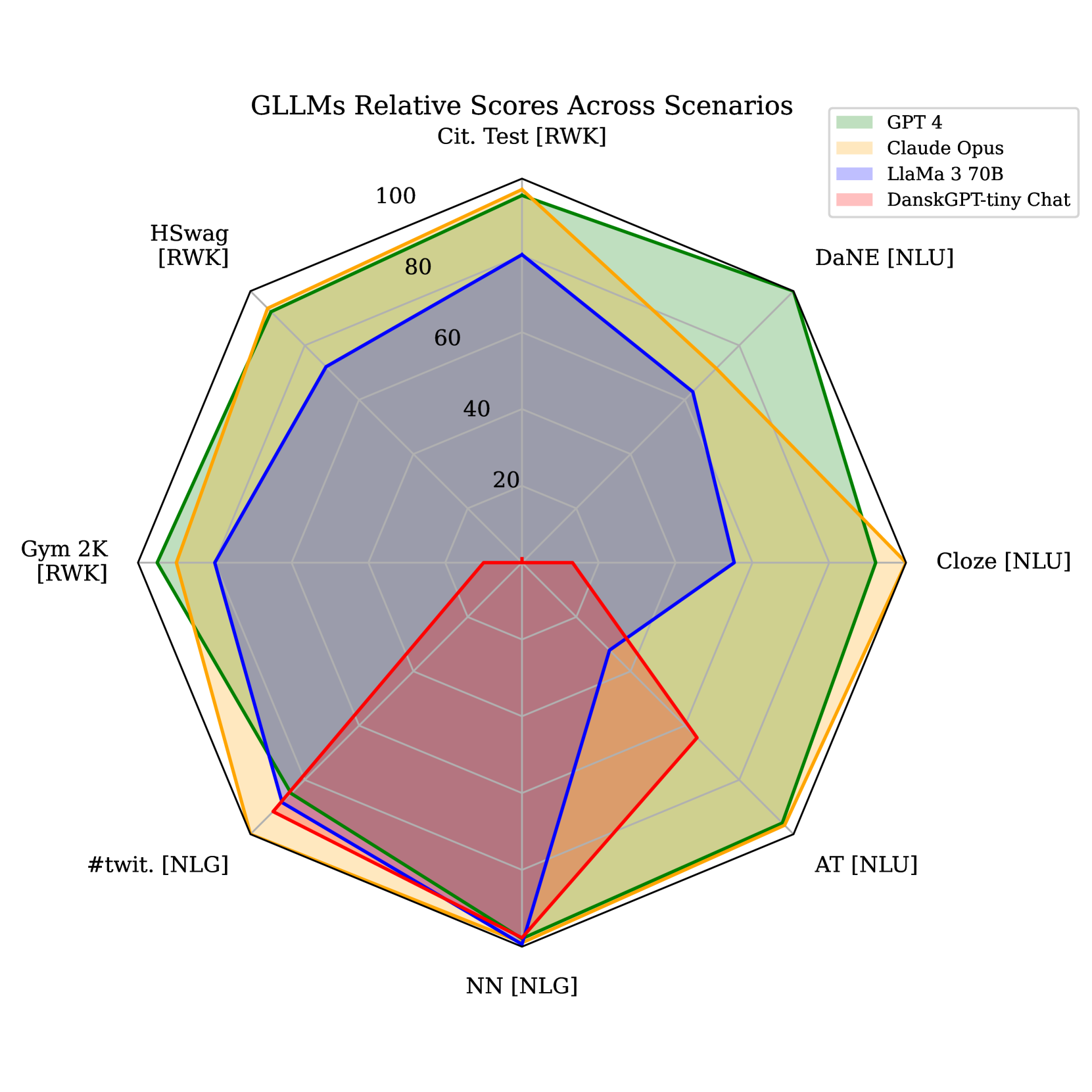
生成大型语言模型(GLLMs)在技术应用、投资和宣传方面的影响并不限于英语,低资源语言同样受益。然而,直到最近,由于缺乏适用的评估语料库,验证这些模型在丹麦语等语言中的能力变得困难。本文提出了一种GLLM基准,用于评估丹麦语言和文化能力(Danoliteracy),涵盖丹麦公民测试和社交媒体问答等八个多样化场景。该基准的结果与人类反馈的相关性高达ρ∼0.8,GPT-4和Claude Opus模型在排名中表现最佳。分析结果显示,95%的场景表现方差可由一个强大的潜在因素解释,表明模型在语言适应中的一致性存在一个g因子。
🔬 方法详解
问题定义:本文旨在解决生成大型语言模型在低资源语言(如丹麦语)能力评估中的不足,现有方法缺乏量化评估标准,难以验证模型的实际应用能力。
核心思路:通过构建Danoliteracy基准,涵盖多种场景(如公民测试和社交媒体问答),提供一种系统的评估方式,以量化模型在丹麦语的表现。
技术框架:整体架构包括数据收集、基准设计和模型评估三个主要模块。首先,收集相关的丹麦语语料;其次,设计多样化的评估场景;最后,利用这些场景对不同GLLMs进行评估和排名。
关键创新:最重要的创新在于提出了Danoliteracy这一概念,并通过构建基准实现了对丹麦语生成模型能力的量化评估,这在现有文献中尚属首次。
关键设计:基准设计中,选择了八个多样化的场景,确保覆盖不同的语言使用情境;在评估过程中,采用了与人类反馈的相关性分析,以确保评估结果的有效性和可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Danoliteracy基准与人类反馈的相关性高达ρ∼0.8,显示出良好的评估效果。GPT-4和Claude Opus模型在该基准中表现最佳,展示了其在丹麦语场景中的强大能力。此外,分析结果表明,95%的场景表现方差由模型一致性因素解释,揭示了模型在语言适应中的重要特征。
🎯 应用场景
该研究的潜在应用领域包括教育、语言学习和社交媒体内容生成等。通过量化评估生成模型在丹麦语的能力,可以为相关技术的开发和优化提供指导,促进低资源语言的技术应用与发展,具有重要的实际价值和未来影响。
📄 摘要(原文)
The language technology moonshot moment of Generative Large Language Models (GLLMs) was not limited to English: These models brought a surge of technological applications, investments, and hype to low-resource languages as well. However, the capabilities of these models in languages such as Danish were, until recently, difficult to verify beyond qualitative demonstrations due to a lack of applicable evaluation corpora. We present a GLLM benchmark to evaluate \emph{Danoliteracy}, a measure of Danish language and cultural competency across eight diverse scenarios such as Danish citizenship tests and abstractive social media question answering. This limited-size benchmark was found to produce a robust ranking that correlates to human feedback at $ρ\sim 0.8$ with GPT-4 and Claude Opus models achieving the highest rankings. Analyzing these model results across scenarios, we find one strong underlying factor explaining $95\%$ of scenario performance variance for GLLMs in Danish, suggesting a $g$ factor of model consistency in language adaptation.