Personalization of Large Language Models: A Survey
作者: Zhehao Zhang, Ryan A. Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Barrow, Tong Yu, Sungchul Kim, Ruiyi Zhang, Jiuxiang Gu, Tyler Derr, Hongjie Chen, Junda Wu, Xiang Chen, Zichao Wang, Subrata Mitra, Nedim Lipka, Nesreen Ahmed, Yu Wang
分类: cs.CL
发布日期: 2024-10-29 (更新: 2025-07-13)
备注: Accepted at the Transactions on Machine Learning Research (TMLR) journal
💡 一句话要点
综述:大型语言模型个性化研究,填补文本生成与下游应用间的空白。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 综述 文本生成 下游应用
📋 核心要点
- 现有个性化LLM研究主要集中于个性化文本生成或利用LLM进行下游个性化应用,缺乏对两者的统一视角。
- 本文提出个性化LLM使用的分类法,形式化个性化LLM的基础,并定义个性化的新方面。
- 通过系统的分类法统一不同领域和使用场景的文献,为研究人员和从业人员提供清晰的指导。
📝 摘要(中文)
大型语言模型(LLM)的个性化在各种应用中变得越来越重要。尽管重要性日益增加且近期取得了进展,但现有关于个性化LLM的大部分工作要么完全集中于(a)个性化文本生成,要么(b)利用LLM进行与个性化相关的下游应用,例如推荐系统。本文首次弥合了这两个主要方向之间的差距,引入了个性化LLM使用的分类,并总结了关键差异和挑战。我们形式化了个性化LLM的基础,整合并扩展了LLM个性化的概念,定义并讨论了个性化的新方面、使用方法以及个性化LLM的需求。然后,通过为个性化的粒度、个性化技术、数据集、评估方法和个性化LLM的应用提出系统的分类法,统一了这些不同领域和使用场景的文献。最后,我们强调了仍然需要解决的挑战和重要的开放性问题。通过使用提出的分类法统一和调查最近的研究,我们旨在为现有文献和LLM个性化的不同方面提供清晰的指导,从而增强研究人员和从业人员的能力。
🔬 方法详解
问题定义:现有关于个性化LLM的研究主要分为两个方向:个性化文本生成和利用LLM进行下游个性化应用(如推荐系统)。这两个方向的研究相对独立,缺乏统一的视角和框架。此外,对于个性化LLM的定义、使用方法和评估标准也缺乏明确的规范。
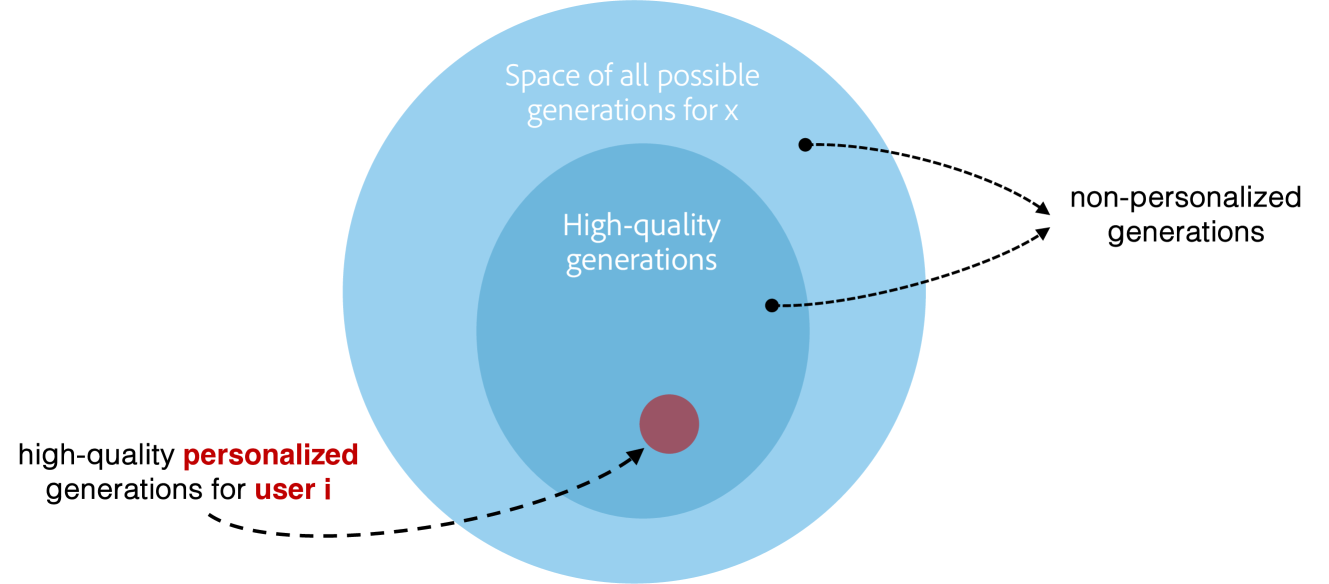
核心思路:本文的核心思路是弥合个性化文本生成和下游个性化应用之间的差距,通过构建一个全面的分类体系,将这两个方向的研究统一起来。通过形式化个性化LLM的基础,定义个性化的新方面,并讨论个性化LLM的需求,为未来的研究提供指导。
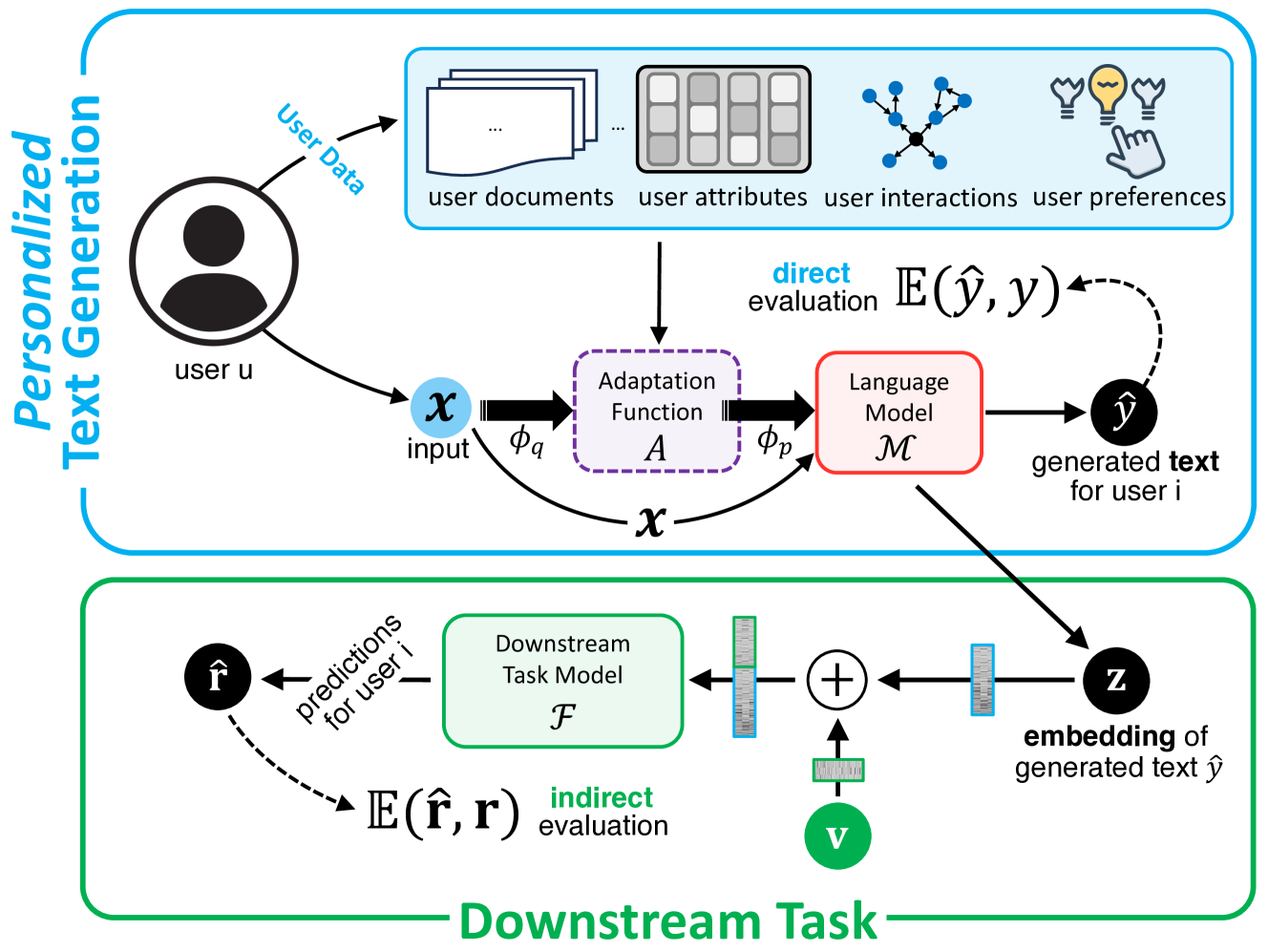
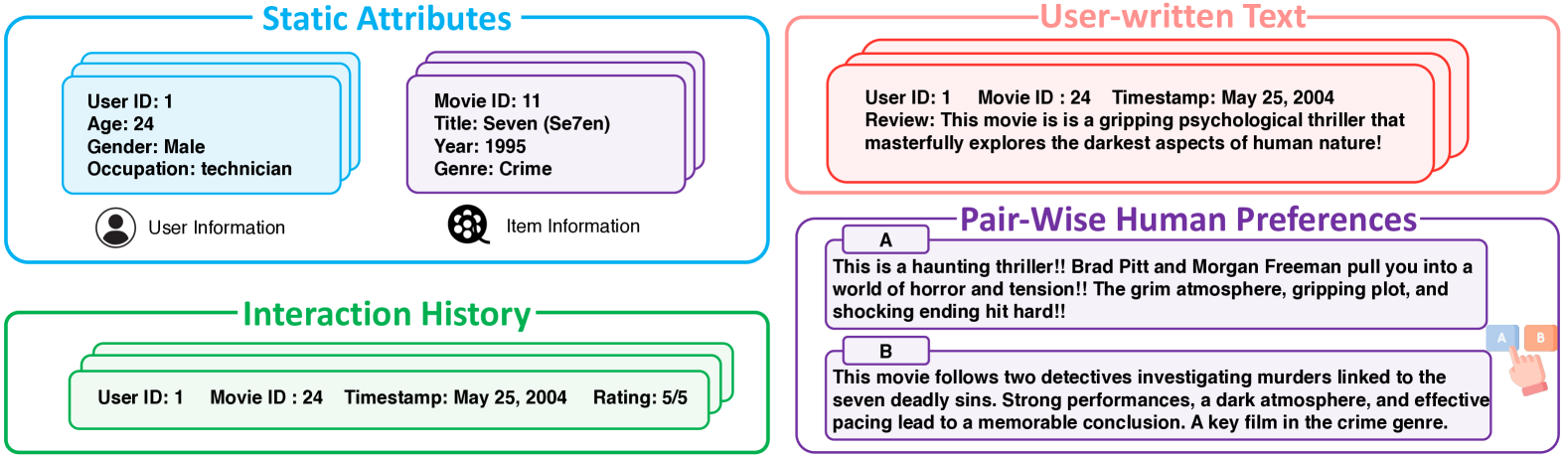
技术框架:本文没有提出具体的算法或模型,而是一个综述性的工作,旨在构建一个关于个性化LLM的知识体系。其框架主要包括以下几个部分: 1. 个性化LLM的定义和形式化 2. 个性化粒度的分类 3. 个性化技术的分类 4. 数据集的分类 5. 评估方法的分类 6. 应用场景的分类
关键创新:本文的创新之处在于首次将个性化文本生成和下游个性化应用这两个方向的研究联系起来,并提出了一个系统的分类体系,为个性化LLM的研究提供了一个统一的框架。此外,本文还形式化了个性化LLM的基础,定义了个性化的新方面,为未来的研究提供了新的思路。
关键设计:本文的关键设计在于其分类体系的构建。该分类体系涵盖了个性化的各个方面,包括粒度、技术、数据集、评估方法和应用场景。通过对这些方面进行分类,本文能够清晰地展示现有研究的现状,并指出未来的研究方向。具体的参数设置、损失函数、网络结构等技术细节不在本文的讨论范围内。
🖼️ 关键图片
📊 实验亮点
本文的主要亮点在于构建了一个关于个性化LLM的全面分类体系,涵盖了个性化的各个方面。通过对现有研究进行分类和总结,本文清晰地展示了现有研究的现状,并指出了未来的研究方向。由于是综述文章,没有具体的性能数据和提升幅度。
🎯 应用场景
该研究成果可应用于各种需要个性化LLM的领域,例如个性化推荐系统、个性化对话系统、个性化内容生成等。通过本文提出的分类体系,研究人员和从业人员可以更好地理解现有研究的现状,并找到未来的研究方向。该研究有助于推动个性化LLM技术的发展,并为用户提供更加个性化的服务。
📄 摘要(原文)
Personalization of Large Language Models (LLMs) has recently become increasingly important with a wide range of applications. Despite the importance and recent progress, most existing works on personalized LLMs have focused either entirely on (a) personalized text generation or (b) leveraging LLMs for personalization-related downstream applications, such as recommendation systems. In this work, we bridge the gap between these two separate main directions for the first time by introducing a taxonomy for personalized LLM usage and summarizing the key differences and challenges. We provide a formalization of the foundations of personalized LLMs that consolidates and expands notions of personalization of LLMs, defining and discussing novel facets of personalization, usage, and desiderata of personalized LLMs. We then unify the literature across these diverse fields and usage scenarios by proposing systematic taxonomies for the granularity of personalization, personalization techniques, datasets, evaluation methods, and applications of personalized LLMs. Finally, we highlight challenges and important open problems that remain to be addressed. By unifying and surveying recent research using the proposed taxonomies, we aim to provide a clear guide to the existing literature and different facets of personalization in LLMs, empowering both researchers and practitioners.