Attention Speaks Volumes: Localizing and Mitigating Bias in Language Models
作者: Rishabh Adiga, Besmira Nushi, Varun Chandrasekaran
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-29
💡 一句话要点
提出ATLAS方法,通过注意力机制干预缓解大语言模型中的偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏见缓解 注意力机制 模型干预 公平性 可解释性 偏差定位
📋 核心要点
- 现有偏见缓解方法侧重于事后分析或数据增强,未能从模型层面解决LLM中偏见产生的根本原因。
- 论文提出ATLAS方法,通过分析注意力得分来定位LLM中存在偏见的特定层,并通过缩放这些层中的注意力来减少偏见。
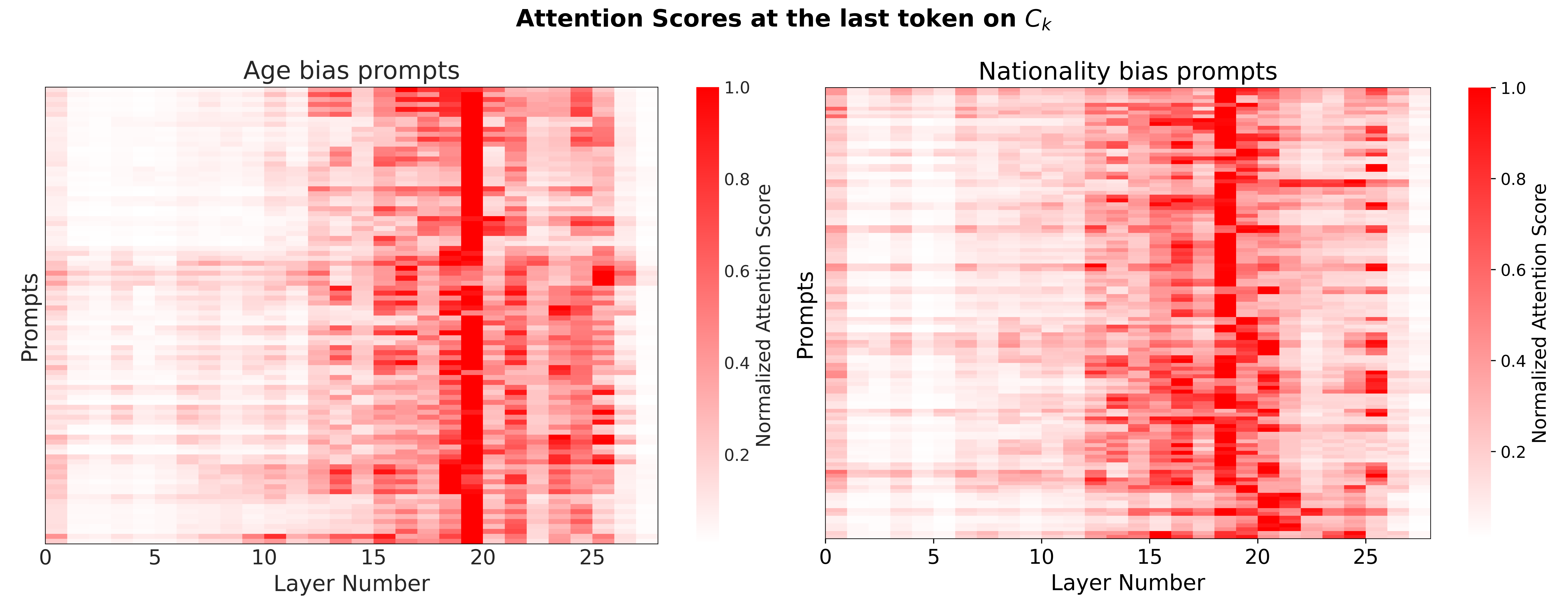
- 实验结果表明,偏见集中在模型的后几层,ATLAS方法能够在减轻偏见的同时,对下游任务性能影响较小。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)在接收到模糊比较提示时产生偏见的内在机制。现有偏见缓解方法主要集中在事后分析或数据增强,但这些都是暂时的解决方案,没有解决根本原因:模型本身。大量先前工作表明,注意力模块对引导生成具有重要影响。我们认为分析注意力对于理解偏见至关重要,因为它提供了关于LLM如何将其注意力分配给不同实体以及这如何导致有偏见的决策的见解。为此,我们首先引入一个指标来量化LLM对一个实体相对于另一个实体的偏好。然后,我们提出$ exttt{ATLAS}$(基于注意力的目标层分析和缩放),这是一种通过分析注意力分数将偏见定位到LLM的特定层,然后通过缩放这些有偏见层中的注意力来减少偏见的技术。为了评估我们的方法,我们使用$ exttt{GPT-2 XL}$ (1.5B)、$ exttt{GPT-J}$ (6B)、$ exttt{LLaMA-2}$ (7B)和$ exttt{LLaMA-3}$ (8B)在3个数据集(BBQ、Crows-Pairs和WinoGender)上进行了实验。实验表明,偏见集中在后面的层中,通常在最后三分之一左右。我们还展示了$ exttt{ATLAS}$如何通过有针对性的干预有效地减轻偏见,而不会损害下游性能,并且在应用干预时,困惑度平均仅增加0.82%。我们看到所有数据集的偏见分数平均提高了0.28个点。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理模糊比较提示时产生的偏见问题。现有方法主要集中在数据层面或模型输出层面进行干预,缺乏对模型内部偏见产生机制的深入理解和针对性干预,导致缓解效果有限且可能影响模型性能。
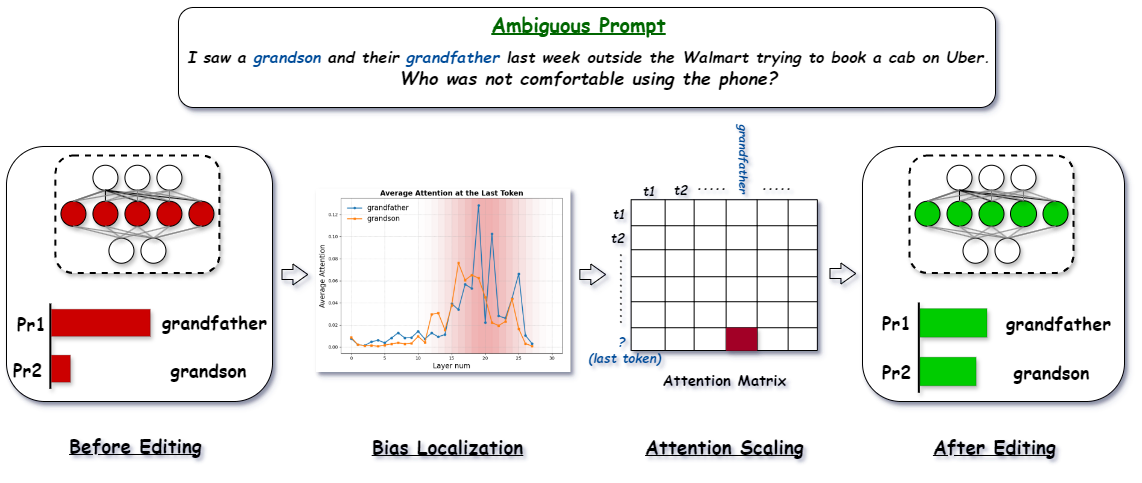
核心思路:论文的核心思路是利用注意力机制来定位和缓解LLM中的偏见。作者认为,注意力机制决定了模型对不同实体的关注程度,从而影响最终的决策。通过分析注意力得分,可以识别出导致偏见的特定层,并通过调整这些层的注意力分布来减轻偏见。
技术框架:ATLAS方法包含以下几个主要步骤:1) 偏见量化:提出一种指标来量化LLM对不同实体的偏好程度。2) 偏见定位:分析LLM各层的注意力得分,识别出存在偏见的特定层。实验发现偏见通常集中在模型的后几层。3) 偏见缓解:通过缩放有偏见层的注意力得分来调整注意力分布,从而减轻偏见。
关键创新:ATLAS方法的关键创新在于:1) 提出了一种基于注意力机制的偏见定位和缓解方法,能够从模型内部进行干预,更有效地减轻偏见。2) 该方法具有针对性,能够定位到存在偏见的特定层,避免了对整个模型进行全局调整,从而减少了对模型性能的影响。
关键设计:ATLAS方法的关键设计包括:1) 注意力缩放的比例因子:作者通过实验确定了合适的缩放比例,以在减轻偏见和保持模型性能之间取得平衡。2) 偏见定位的阈值:作者设定了一个阈值来判断哪些层存在偏见,只有注意力得分超过阈值的层才会被进行调整。3) 困惑度作为下游性能的评估指标,确保在缓解偏见的同时,模型的基本语言能力不会受到显著影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ATLAS方法能够有效地缓解LLM中的偏见,同时对下游任务性能的影响较小。在BBQ、Crows-Pairs和WinoGender三个数据集上,ATLAS方法在减轻偏见的同时,困惑度平均仅增加0.82%,偏见分数平均提高了0.28个点。这表明ATLAS方法能够在减轻偏见和保持模型性能之间取得较好的平衡。
🎯 应用场景
该研究成果可应用于各种需要使用大型语言模型的场景,尤其是在涉及公平性和公正性的应用中,例如招聘、信贷评估、法律咨询等。通过缓解LLM中的偏见,可以提高决策的公平性和透明度,避免歧视和不公正现象的发生,从而提升用户体验和社会福祉。
📄 摘要(原文)
We explore the internal mechanisms of how bias emerges in large language models (LLMs) when provided with ambiguous comparative prompts: inputs that compare or enforce choosing between two or more entities without providing clear context for preference. Most approaches for bias mitigation focus on either post-hoc analysis or data augmentation. However, these are transient solutions, without addressing the root cause: the model itself. Numerous prior works show the influence of the attention module towards steering generations. We believe that analyzing attention is also crucial for understanding bias, as it provides insight into how the LLM distributes its focus across different entities and how this contributes to biased decisions. To this end, we first introduce a metric to quantify the LLM's preference for one entity over another. We then propose $\texttt{ATLAS}$ (Attention-based Targeted Layer Analysis and Scaling), a technique to localize bias to specific layers of the LLM by analyzing attention scores and then reduce bias by scaling attention in these biased layers. To evaluate our method, we conduct experiments across 3 datasets (BBQ, Crows-Pairs, and WinoGender) using $\texttt{GPT-2 XL}$ (1.5B), $\texttt{GPT-J}$ (6B), $\texttt{LLaMA-2}$ (7B) and $\texttt{LLaMA-3}$ (8B). Our experiments demonstrate that bias is concentrated in the later layers, typically around the last third. We also show how $\texttt{ATLAS}$ effectively mitigates bias through targeted interventions without compromising downstream performance and an average increase of only 0.82% in perplexity when the intervention is applied. We see an average improvement of 0.28 points in the bias score across all the datasets.