Anticipating Future with Large Language Model for Simultaneous Machine Translation
作者: Siqi Ouyang, Oleksii Hrinchuk, Zhehuai Chen, Vitaly Lavrukhin, Jagadeesh Balam, Lei Li, Boris Ginsburg
分类: cs.CL
发布日期: 2024-10-29 (更新: 2025-05-31)
备注: NAACL 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
提出TAF:利用大语言模型预测未来词汇,提升同步机器翻译质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 同步机器翻译 大语言模型 未来预测 低延迟 机器翻译 实时翻译
📋 核心要点
- 现有同步机器翻译方法依赖已接收到的部分输入,忽略了预测未来信息的能力,限制了翻译质量。
- TAF方法利用大型语言模型预测未来源语言词汇,从而在低延迟下更准确地进行翻译。
- 实验结果表明,TAF在多个语言方向上显著提升了翻译质量,BLEU值最高提升5个点。
📝 摘要(中文)
同步机器翻译(SMT)接收流式输入的语句,并增量式地生成目标文本。现有的SMT方法主要使用已到达的输入部分语句和已生成的假设。受到人类译员在听到未来词汇之前预测它们的技术的启发,我们提出了通过预测未来进行翻译(TAF),这是一种在降低延迟的同时提高翻译质量的方法。其核心思想是使用大型语言模型(LLM)来预测未来的源词,并伺机进行翻译,而不会引入太多的风险。我们在四个语言方向上评估了我们的TAF和多个SMT基线。实验表明,TAF在相同的延迟(三个词)下,实现了最佳的翻译质量-延迟权衡,并且优于基线高达5个BLEU点。代码已在https://github.com/owaski/TAF发布。
🔬 方法详解
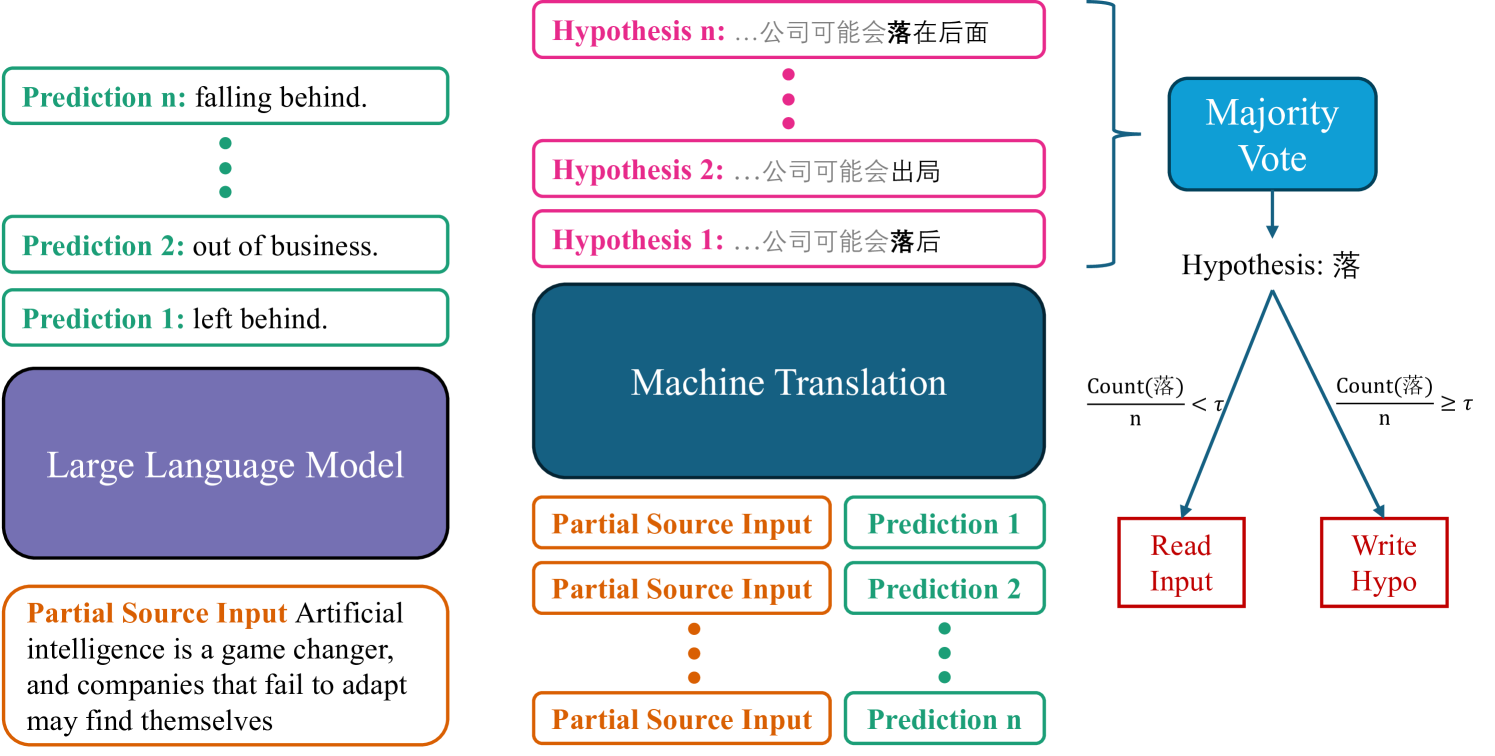
问题定义:同步机器翻译需要在接收到部分源语言输入时,实时生成目标语言翻译。现有方法主要依赖已接收到的源语言片段,缺乏对未来信息的利用,导致翻译质量受限。痛点在于如何在低延迟要求下,有效利用上下文信息,提高翻译的准确性和流畅性。
核心思路:TAF的核心思路是借鉴人类译员预测未来词汇的技巧,利用大型语言模型(LLM)预测未来源语言的词汇,从而在翻译过程中获得更全面的上下文信息。通过预测未来,TAF可以在不显著增加延迟的情况下,做出更明智的翻译决策。
技术框架:TAF包含以下主要模块:1) 源语言输入流;2) LLM未来词汇预测模块;3) 翻译模型(基于已接收到的源语言片段和LLM预测的未来词汇);4) 目标语言输出流。整体流程是,接收到部分源语言输入后,LLM预测未来词汇,然后翻译模型结合已接收到的和预测的词汇进行翻译,最后输出目标语言。
关键创新:TAF的关键创新在于将大型语言模型引入同步机器翻译,用于预测未来源语言词汇。与传统方法仅依赖已接收到的信息不同,TAF通过预测未来,扩展了翻译模型的上下文视野,从而提高了翻译质量。这种方法在同步翻译中引入了“预见性”,更接近人类翻译的模式。
关键设计:TAF的关键设计包括:1) LLM的选择和训练:选择合适的LLM,并针对同步翻译任务进行微调,以提高预测的准确性;2) 预测词汇的使用策略:如何将LLM预测的词汇有效地融入到翻译模型中,避免引入噪声;3) 延迟控制机制:设计合理的延迟控制机制,确保在提高翻译质量的同时,满足低延迟的要求。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TAF在四个语言方向上均优于现有的同步机器翻译基线方法。在相同的延迟(三个词)下,TAF的BLEU值最高提升了5个点。这表明TAF能够有效地利用LLM预测的未来信息,从而显著提高翻译质量,同时保持较低的延迟。
🎯 应用场景
TAF方法可应用于实时会议翻译、在线客服、直播字幕等需要低延迟和高质量翻译的场景。该研究的实际价值在于提升了同步机器翻译的性能,使得机器翻译在实时交互场景中更加实用。未来,TAF可以与其他技术结合,例如语音识别、语音合成等,构建更完善的实时翻译系统。
📄 摘要(原文)
Simultaneous machine translation (SMT) takes streaming input utterances and incrementally produces target text. Existing SMT methods mainly use the partial utterance that has already arrived at the input and the generated hypothesis. Motivated by human interpreters' technique to forecast future words before hearing them, we propose $\textbf{T}$ranslation by $\textbf{A}$nticipating $\textbf{F}$uture (TAF), a method to improve translation quality while retraining low latency. Its core idea is to use a large language model (LLM) to predict future source words and opportunistically translate without introducing too much risk. We evaluate our TAF and multiple baselines of SMT on four language directions. Experiments show that TAF achieves the best translation quality-latency trade-off and outperforms the baselines by up to 5 BLEU points at the same latency (three words). Code is released at https://github.com/owaski/TAF