Protecting Privacy in Multimodal Large Language Models with MLLMU-Bench
作者: Zheyuan Liu, Guangyao Dou, Mengzhao Jia, Zhaoxuan Tan, Qingkai Zeng, Yongle Yuan, Meng Jiang
分类: cs.CL, cs.AI
发布日期: 2024-10-29 (更新: 2025-02-14)
备注: NAACL Main 2025
💡 一句话要点
提出MLLMU-Bench基准,用于评估和提升多模态大语言模型的隐私保护能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 机器遗忘 隐私保护 基准数据集
📋 核心要点
- 多模态大语言模型(MLLM)存在隐私泄露风险,但缺乏专门的遗忘方法和评估基准。
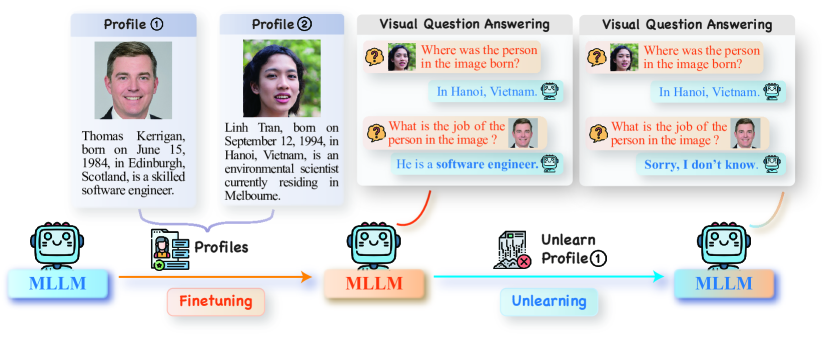
- 提出MLLMU-Bench基准,包含虚构和真实人物资料,覆盖多模态和单模态评估。
- 实验表明,单模态遗忘算法在生成任务中表现优异,多模态遗忘算法在分类任务中更胜一筹。
📝 摘要(中文)
大型语言模型(LLM)和多模态大型语言模型(MLLM)在海量网络语料上训练,可能记忆并泄露个人隐私数据,引发法律和伦理问题。虽然之前许多工作通过机器遗忘解决了LLM中的这个问题,但对于MLLM的研究仍然不足。为了应对这一挑战,我们推出了多模态大型语言模型遗忘基准(MLLMU-Bench),旨在促进对多模态机器遗忘的理解。MLLMU-Bench包含500个虚构人物和153个公众人物的资料,每个资料包含超过14个定制的问答对,从多模态(图像+文本)和单模态(文本)的角度进行评估。该基准分为四个集合,用于评估遗忘算法的有效性、泛化性和模型效用。最后,我们使用现有的生成模型遗忘算法提供了基线结果。令人惊讶的是,我们的实验表明,单模态遗忘算法在生成和完形填空任务中表现出色,而多模态遗忘方法在多模态输入的分类任务中表现更好。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中存在的隐私泄露问题。现有的机器遗忘方法主要集中在单模态的LLM上,缺乏针对MLLM的有效评估和遗忘机制。因此,如何评估和提升MLLM的隐私保护能力是一个重要的挑战。
核心思路:论文的核心思路是构建一个专门用于评估MLLM遗忘能力的基准数据集MLLMU-Bench。通过设计包含多模态信息(图像+文本)的人物资料和定制的问答对,可以全面评估遗忘算法在不同场景下的表现。同时,通过提供基线结果,为未来的研究提供参考。
技术框架:MLLMU-Bench基准主要包含以下几个部分:1)人物资料构建:包含虚构人物和公众人物,每个人物包含图像和文本描述;2)问答对设计:为每个人物设计超过14个定制的问答对,涵盖不同类型的隐私信息;3)评估指标:设计了评估遗忘算法有效性、泛化性和模型效用的指标;4)基线实验:使用现有的生成模型遗忘算法在MLLMU-Bench上进行实验,提供基线结果。
关键创新:该论文的关键创新在于构建了一个专门针对多模态大语言模型遗忘的基准数据集MLLMU-Bench。与现有的单模态遗忘基准相比,MLLMU-Bench考虑了多模态信息的复杂性,能够更全面地评估MLLM的隐私保护能力。
关键设计:MLLMU-Bench的关键设计包括:1)人物资料的多样性:包含虚构人物和公众人物,以评估遗忘算法的泛化能力;2)问答对的定制性:针对每个人物设计特定的问答对,以评估遗忘算法对不同类型隐私信息的处理能力;3)评估指标的全面性:从有效性、泛化性和模型效用三个方面评估遗忘算法的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有的单模态遗忘算法在MLLMU-Bench的生成和完形填空任务中表现出色,而多模态遗忘方法在多模态输入的分类任务中表现更好。这一发现揭示了不同遗忘算法在多模态场景下的优劣势,为未来的算法设计提供了指导。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的隐私保护能力,例如在医疗、金融等敏感数据处理领域,可以利用该基准评估和优化遗忘算法,降低模型泄露用户隐私的风险。未来,该基准可以促进多模态机器遗忘算法的发展,推动安全可信赖的人工智能应用。
📄 摘要(原文)
Generative models such as Large Language Models (LLM) and Multimodal Large Language models (MLLMs) trained on massive web corpora can memorize and disclose individuals' confidential and private data, raising legal and ethical concerns. While many previous works have addressed this issue in LLM via machine unlearning, it remains largely unexplored for MLLMs. To tackle this challenge, we introduce Multimodal Large Language Model Unlearning Benchmark (MLLMU-Bench), a novel benchmark aimed at advancing the understanding of multimodal machine unlearning. MLLMU-Bench consists of 500 fictitious profiles and 153 profiles for public celebrities, each profile feature over 14 customized question-answer pairs, evaluated from both multimodal (image+text) and unimodal (text) perspectives. The benchmark is divided into four sets to assess unlearning algorithms in terms of efficacy, generalizability, and model utility. Finally, we provide baseline results using existing generative model unlearning algorithms. Surprisingly, our experiments show that unimodal unlearning algorithms excel in generation and cloze tasks, while multimodal unlearning approaches perform better in classification tasks with multimodal inputs.