A Survey on Automatic Credibility Assessment Using Textual Credibility Signals in the Era of Large Language Models
作者: Ivan Srba, Olesya Razuvayevskaya, João A. Leite, Robert Moro, Ipek Baris Schlicht, Sara Tonelli, Francisco Moreno García, Santiago Barrio Lottmann, Denis Teyssou, Valentin Porcellini, Carolina Scarton, Kalina Bontcheva, Maria Bielikova
分类: cs.CL
发布日期: 2024-10-28 (更新: 2025-10-13)
备注: Accepted to ACM Transactions on Intelligent Systems and Technology (ACM TIST)
期刊: ACM Transactions on Intelligent Systems and Technology. 2025. 81 pages
DOI: 10.1145/3770077
💡 一句话要点
在大语言模型时代,综述基于文本可信度信号的自动可信度评估方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可信度评估 文本可信度信号 自然语言处理 大语言模型 虚假信息检测
📋 核心要点
- 现有自动可信度评估研究分散,缺乏对多种可信度信号的综合检测与聚合。
- 该综述系统回顾了175篇论文,重点关注NLP领域中基于文本的可信度信号。
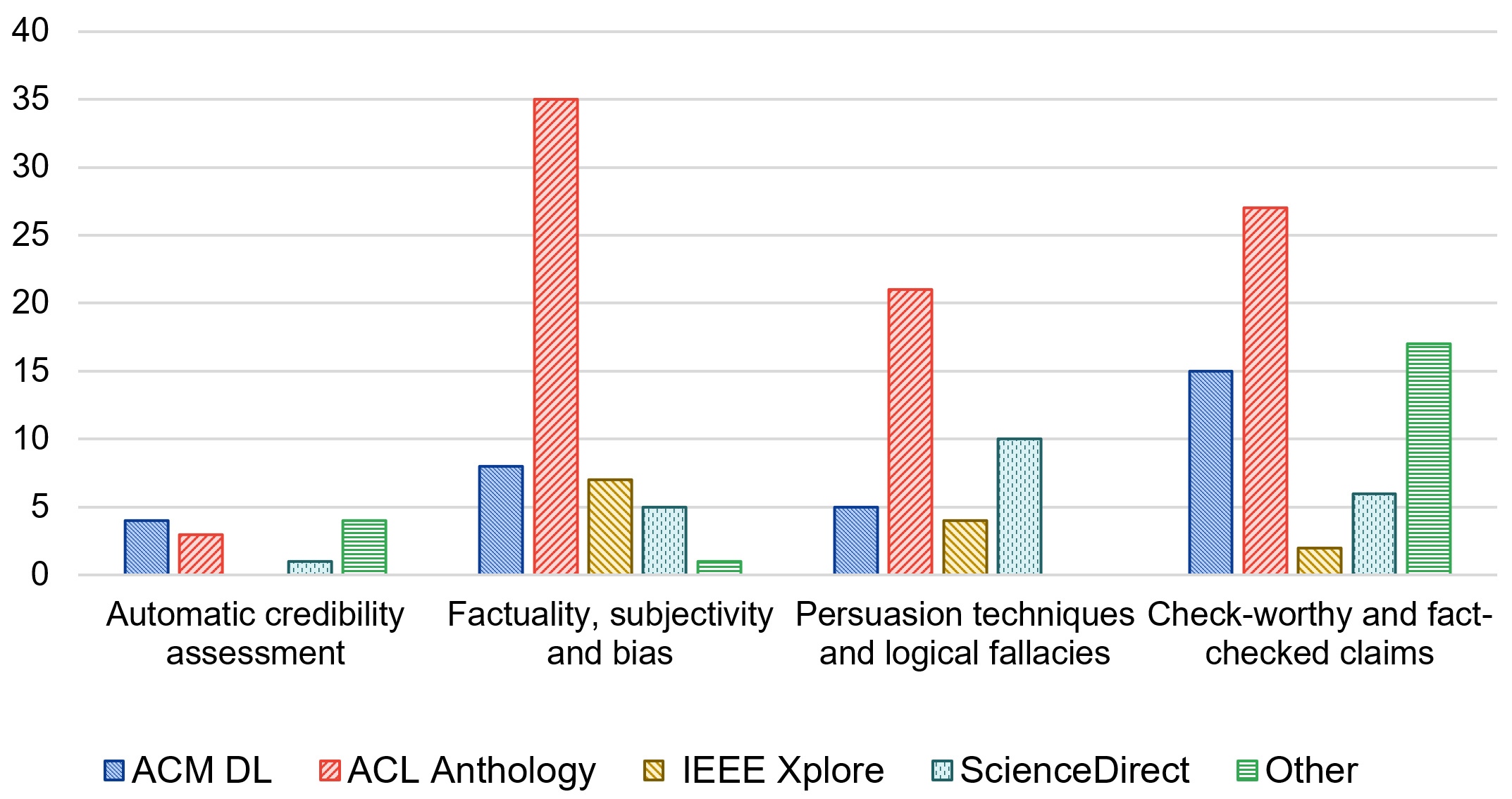
- 分析了事实性、主观性与偏见、说服技巧与谬误、待核实与已核实声明三大类信号。
📝 摘要(中文)
在社交媒体和生成式人工智能时代,自动评估在线内容可信度的能力变得至关重要,是对传统虚假信息检测方法的补充。可信度评估依赖于聚合各种可信度信号——例如内容的主观性、偏见或说服技巧的存在——形成最终的可信度标签/分数。然而,目前自动可信度评估和可信度信号检测的研究仍然高度分散,许多信号被孤立地研究,缺乏整合。特别值得注意的是,缺乏同时检测和聚合多个可信度信号的方法。此外,也缺乏对现有研究工作的全面和最新的概述,以在共同框架下连接这些研究工作,并识别共同的趋势、挑战和未解决的问题。本综述旨在填补这一空白,系统全面地回顾了175篇研究论文,重点关注自然语言处理(NLP)领域中基于文本的可信度信号,该领域正因大语言模型(LLM)的进步而发生快速转变。在将NLP研究置于更广泛的多学科背景下的同时,我们考察了自动可信度评估方法以及九类可信度信号的检测。我们深入分析了三个关键类别:1) 事实性、主观性和偏见,2) 说服技巧和逻辑谬误,3) 值得核实和已核实的主张。除了总结现有的方法、数据集和工具外,我们还概述了未来的研究方向和新兴机遇,特别关注生成式人工智能带来的不断变化的挑战。
🔬 方法详解
问题定义:当前自动可信度评估研究面临的主要问题是缺乏对多种文本可信度信号的综合考虑和有效整合。现有方法通常孤立地研究单个信号,无法充分利用不同信号之间的关联性。此外,随着生成式AI的发展,虚假信息的生成变得更加容易,对可信度评估提出了新的挑战。
核心思路:本综述的核心思路是通过系统性地梳理和分析现有文献,构建一个统一的框架,将各种文本可信度信号及其检测方法联系起来。通过识别共同的趋势、挑战和未解决的问题,为未来的研究提供指导。同时,关注大语言模型对可信度评估带来的影响。
技术框架:该综述首先对自动可信度评估的背景和相关概念进行介绍,然后详细分析了九类文本可信度信号,并对每类信号的检测方法进行总结。重点分析了事实性、主观性与偏见、说服技巧与谬误、待核实与已核实声明这三个关键类别。最后,对现有数据集和工具进行总结,并展望未来的研究方向。
关键创新:本综述的主要创新在于其全面性和系统性。它不仅涵盖了大量的研究论文,而且对各种可信度信号及其检测方法进行了深入的分析和比较。此外,该综述还特别关注了大语言模型对可信度评估的影响,并提出了未来的研究方向。与以往的综述相比,本综述更加全面和及时,能够为研究人员提供更有效的指导。
关键设计:本综述的关键设计在于其分类框架,将文本可信度信号分为九类,并对每类信号的检测方法进行详细的分析。此外,该综述还对现有数据集和工具进行了总结,为研究人员提供了方便的资源。在分析大语言模型的影响时,该综述重点关注了生成式AI带来的新挑战,并提出了相应的解决方案。
🖼️ 关键图片


📊 实验亮点
该综述回顾了175篇相关研究论文,对九类文本可信度信号进行了深入分析,并重点关注了事实性、主观性与偏见、说服技巧与谬误、待核实与已核实声明这三个关键类别。此外,该综述还总结了现有数据集和工具,并展望了未来的研究方向,为研究人员提供了宝贵的资源和指导。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻媒体、搜索引擎等领域,帮助用户识别虚假信息,提高信息的可信度。通过自动评估文本的可信度,可以减少人工审核的工作量,提高信息过滤的效率,从而构建更健康的网络生态环境。未来,该研究还可应用于教育领域,帮助学生提高辨别信息真伪的能力。
📄 摘要(原文)
In the age of social media and generative AI, the ability to automatically assess the credibility of online content has become increasingly critical, complementing traditional approaches to false information detection. Credibility assessment relies on aggregating diverse credibility signals - small units of information, such as content subjectivity, bias, or a presence of persuasion techniques - into a final credibility label/score. However, current research in automatic credibility assessment and credibility signals detection remains highly fragmented, with many signals studied in isolation and lacking integration. Notably, there is a scarcity of approaches that detect and aggregate multiple credibility signals simultaneously. These challenges are further exacerbated by the absence of a comprehensive and up-to-date overview of research works that connects these research efforts under a common framework and identifies shared trends, challenges, and open problems. In this survey, we address this gap by presenting a systematic and comprehensive literature review of 175 research papers, focusing on textual credibility signals within the field of Natural Language Processing (NLP), which undergoes a rapid transformation due to advancements in Large Language Models (LLMs). While positioning the NLP research into the the broader multidisciplinary landscape, we examine both automatic credibility assessment methods as well as the detection of nine categories of credibility signals. We provide an in-depth analysis of three key categories: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) check-worthy and fact-checked claims. In addition to summarising existing methods, datasets, and tools, we outline future research direction and emerging opportunities, with particular attention to evolving challenges posed by generative AI.