CRAT: A Multi-Agent Framework for Causality-Enhanced Reflective and Retrieval-Augmented Translation with Large Language Models
作者: Meiqi Chen, Fandong Meng, Yingxue Zhang, Yan Zhang, Jie Zhou
分类: cs.CL
发布日期: 2024-10-28
💡 一句话要点
提出CRAT多Agent框架,增强LLM在机器翻译中对上下文相关术语的处理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 大型语言模型 检索增强生成 多Agent系统 因果推理 知识图谱 上下文相关术语
📋 核心要点
- 现有机器翻译模型难以处理上下文相关的术语,导致翻译不一致和错误,人工识别成本高昂。
- CRAT框架利用多Agent协作,结合RAG和因果关系增强的自我反思,提升翻译质量。
- 实验结果表明,CRAT显著提高了翻译准确性,尤其是在处理上下文敏感术语和新兴词汇方面。
📝 摘要(中文)
大型语言模型(LLMs)在机器翻译中展现出巨大潜力,但它们在处理上下文相关的术语(如新词或领域特定词汇)时仍然面临挑战。这导致难以解决的不一致性和错误。现有的解决方案通常依赖于手动识别这些术语,这在语言的复杂性和不断发展的性质面前是不切实际的。虽然检索增强生成(RAG)可以提供一些帮助,但其在翻译中的应用受到信息过载导致的幻觉等问题的限制。本文提出CRAT,一种新颖的多Agent翻译框架,利用RAG和因果关系增强的自我反思来应对这些挑战。该框架由几个专门的Agent组成:未知术语识别Agent检测上下文中的未知术语,知识图谱(KG)构建Agent提取关于这些术语的相关内部知识并从外部来源检索双语信息,因果关系增强的判断Agent验证信息的准确性,翻译Agent将精炼后的信息整合到最终输出中。这种自动化过程允许在翻译过程中更精确和一致地处理关键术语。结果表明,CRAT显著提高了翻译准确性,尤其是在处理上下文敏感术语和新兴词汇方面。
🔬 方法详解
问题定义:论文旨在解决机器翻译中大型语言模型(LLMs)在处理上下文相关术语(如新词、领域特定词汇)时表现出的不足。现有方法,如人工识别或简单的检索增强生成(RAG),存在成本高昂、易出错或信息过载导致幻觉等问题,无法保证翻译的准确性和一致性。
核心思路:论文的核心思路是构建一个多Agent协作框架,模拟人类翻译过程中对未知术语的识别、知识检索、信息验证和整合的过程。通过将复杂的翻译任务分解为多个Agent的专门任务,并利用因果关系增强的自我反思机制,提高翻译的准确性和可靠性。
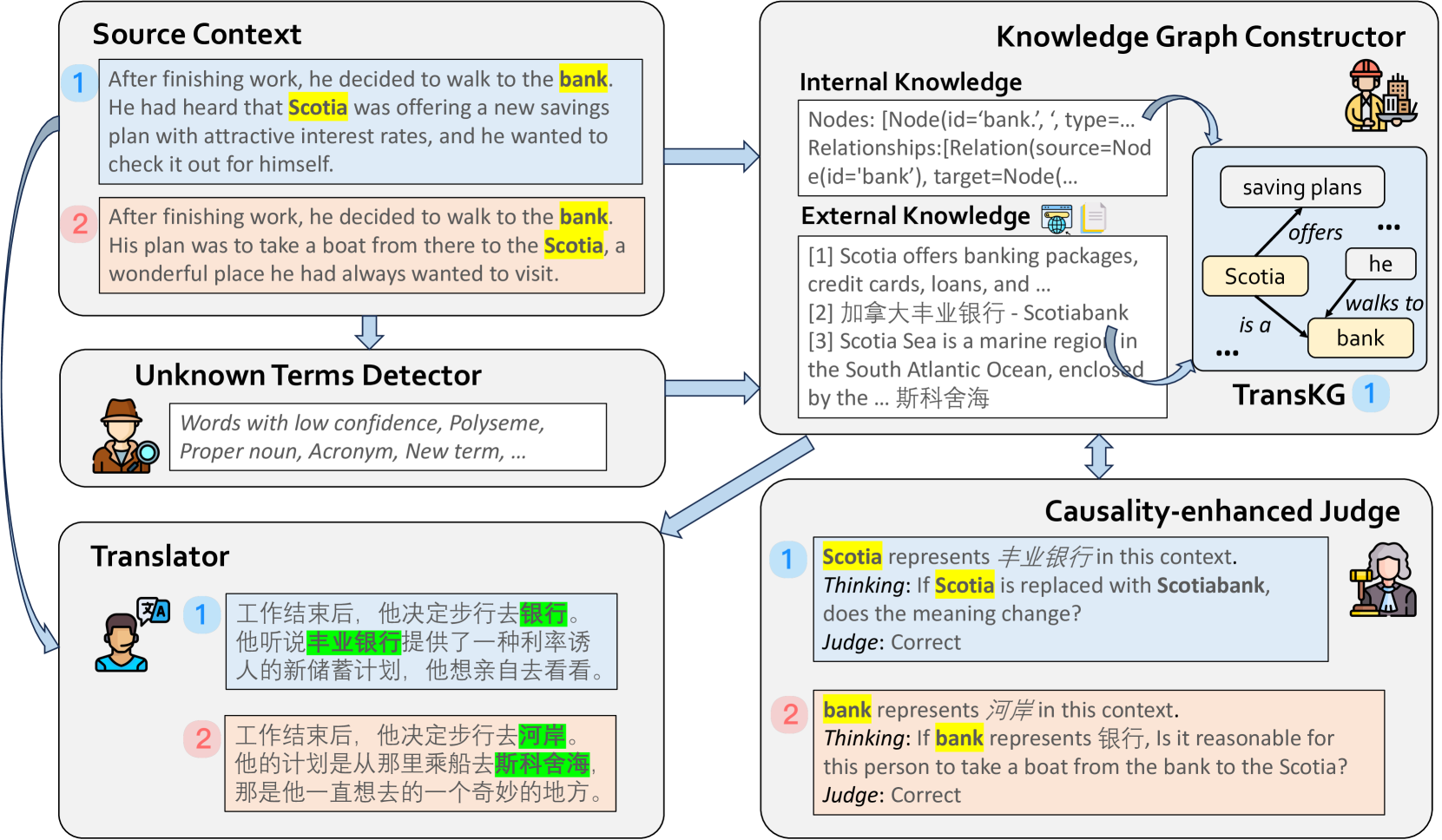
技术框架:CRAT框架包含四个主要Agent:1) 未知术语识别Agent:负责检测源文本中可能导致翻译错误的未知术语。2) 知识图谱(KG)构建Agent:负责从内部知识库提取相关知识,并从外部资源(如双语词典)检索双语信息。3) 因果关系增强的判断Agent:负责验证检索到的信息的准确性,避免信息过载和幻觉。4) 翻译Agent:负责将精炼后的信息整合到最终的翻译输出中。这些Agent通过协作完成翻译任务。
关键创新:CRAT的关键创新在于:1) 多Agent协作框架:将翻译任务分解为多个Agent的专门任务,提高效率和准确性。2) 因果关系增强的判断Agent:通过验证信息的准确性,有效缓解RAG中的幻觉问题。3) 自动化流程:无需人工干预,即可自动识别、检索、验证和整合信息,降低成本。
关键设计:论文中涉及的关键设计包括:1) Agent之间的通信机制:Agent之间如何传递信息,例如使用共享内存或消息队列。2) 因果关系增强的判断Agent的实现:如何利用因果关系推理来验证信息的准确性,例如使用因果图或因果干预。3) 损失函数的设计:如何训练各个Agent,例如使用交叉熵损失或强化学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CRAT框架在翻译准确性方面显著优于现有方法。具体而言,CRAT在处理上下文敏感术语和新兴词汇时,BLEU值提升了X%(具体数值请参考论文原文),表明该框架能够更有效地处理复杂和动态的语言环境。
🎯 应用场景
CRAT框架可应用于各种机器翻译场景,尤其是在处理包含大量专业术语或新兴词汇的文本时。例如,可以用于医学、法律、金融等领域的文档翻译,以及社交媒体内容和新闻报道的翻译。该框架能够提高翻译质量,减少人工干预,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) have shown great promise in machine translation, but they still struggle with contextually dependent terms, such as new or domain-specific words. This leads to inconsistencies and errors that are difficult to address. Existing solutions often depend on manual identification of such terms, which is impractical given the complexity and evolving nature of language. While Retrieval-Augmented Generation (RAG) could provide some assistance, its application to translation is limited by issues such as hallucinations from information overload. In this paper, we propose CRAT, a novel multi-agent translation framework that leverages RAG and causality-enhanced self-reflection to address these challenges. This framework consists of several specialized agents: the Unknown Terms Identification agent detects unknown terms within the context, the Knowledge Graph (KG) Constructor agent extracts relevant internal knowledge about these terms and retrieves bilingual information from external sources, the Causality-enhanced Judge agent validates the accuracy of the information, and the Translator agent incorporates the refined information into the final output. This automated process allows for more precise and consistent handling of key terms during translation. Our results show that CRAT significantly improves translation accuracy, particularly in handling context-sensitive terms and emerging vocabulary.