NewTerm: Benchmarking Real-Time New Terms for Large Language Models with Annual Updates
作者: Hexuan Deng, Wenxiang Jiao, Xuebo Liu, Min Zhang, Zhaopeng Tu
分类: cs.CL
发布日期: 2024-10-28
备注: Accepted to NeurIPS 2024 Datasets and Benchmarks Track
🔗 代码/项目: GITHUB
💡 一句话要点
NewTerm:构建年度更新的LLM实时新词评测基准,解决知识截断问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 实时信息 新术语 评测基准 自动化构建 知识截断 自然语言处理
📋 核心要点
- 现有LLM由于知识截断,难以处理实时信息,现有评测基准缺乏实时更新能力,且对新术语覆盖不足。
- NewTerm通过高度自动化的构建方法,以最小的人工成本构建高质量的、可灵活更新的实时新词评测基准。
- 实验表明,新术语会导致LLM性能显著下降,即使更新LLM知识也难以完全解决新术语带来的挑战。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出色,但由于开发过程中的知识截断,它们在实时信息(例如,新事实和术语)方面仍然存在困难。现有的基准测试侧重于过时的内容和有限的领域,难以进行实时更新,并且对新术语的探索不足。为了解决这个问题,我们提出了一个自适应基准NewTerm,用于实时评估新术语。我们设计了一种高度自动化的构建方法,以最小的人工成本确保高质量的基准构建,从而可以灵活地更新实时信息。对各种LLM的实证结果表明,新术语会导致超过20%的性能下降。此外,虽然更新LLM的知识截断可以覆盖一些新术语,但它们无法推广到更遥远的新术语。我们还分析了哪些类型的术语更具挑战性,以及LLM为何难以处理新术语,为未来的研究铺平了道路。最后,我们构建了NewTerm 2022和2023来评估每年更新的新术语,并将继续每年更新。基准测试和代码可在https://github.com/hexuandeng/NewTerm找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理实时信息,特别是新出现的术语时遇到的困难。现有基准测试存在内容过时、领域有限以及难以实时更新的问题,无法有效评估LLM对新术语的理解和应用能力。这导致LLM在需要最新知识的任务中表现不佳,限制了其应用范围。
核心思路:论文的核心思路是构建一个自适应的、可实时更新的基准测试集NewTerm,专门用于评估LLM对新术语的掌握程度。通过自动化构建流程,降低人工成本,保证基准测试集能够及时反映最新的术语和知识。同时,分析LLM在新术语处理上的弱点,为未来的研究提供方向。
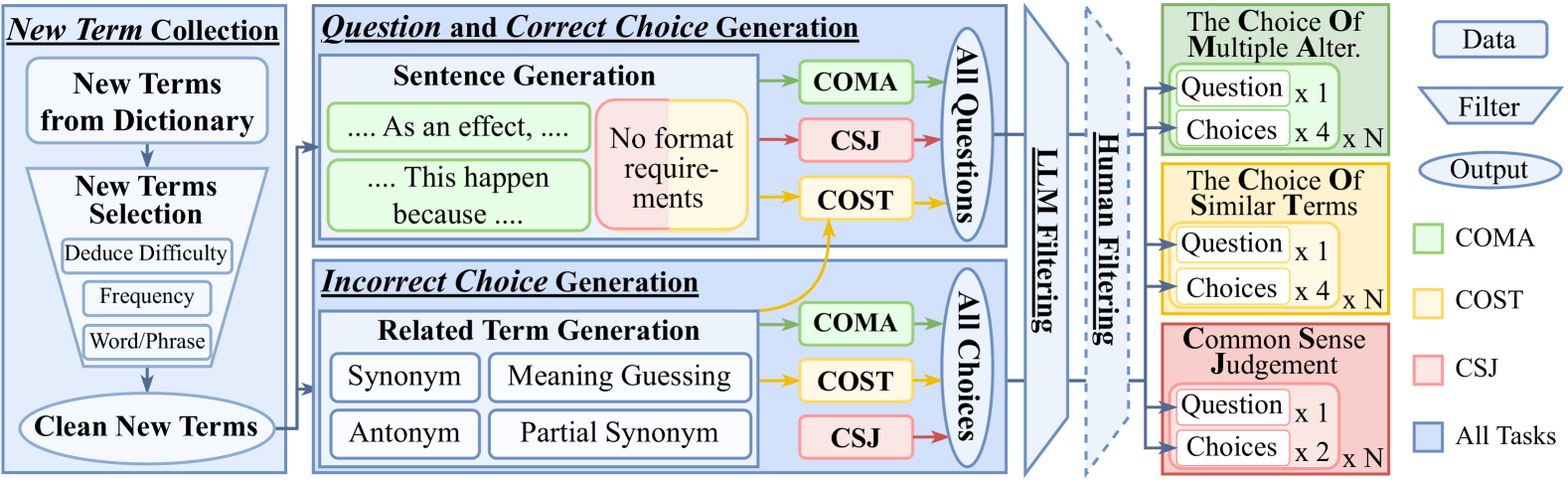
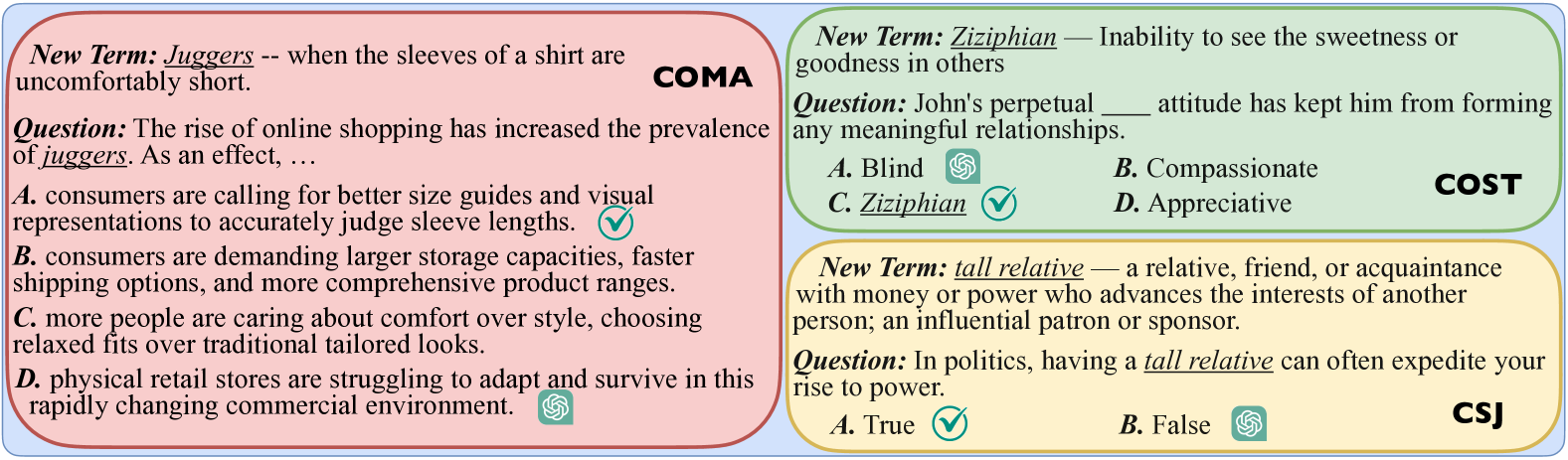
技术框架:NewTerm的构建流程主要包括以下几个阶段:1) 数据收集:从各种来源(如新闻、社交媒体等)收集最新的文本数据。2) 新术语识别:利用自然语言处理技术,自动识别文本数据中的新术语。3) 语料构建:围绕新术语构建高质量的语料库,包括定义、例句、相关知识等。4) 自动化评估:设计自动化评估指标,评估LLM对新术语的理解和应用能力。5) 年度更新:定期更新基准测试集,以反映最新的术语和知识。
关键创新:NewTerm的关键创新在于其高度自动化的构建方法,这使得基准测试集能够以较低的成本进行实时更新,从而能够及时反映最新的术语和知识。此外,NewTerm专注于评估LLM对新术语的理解和应用能力,这与现有基准测试侧重于通用知识或特定领域知识有所不同。
关键设计:NewTerm采用了一种高度自动化的构建方法,以确保基准测试集能够以较低的成本进行实时更新。具体的技术细节包括:1) 使用自然语言处理技术自动识别新术语。2) 设计高质量的语料库构建方法,包括定义、例句、相关知识等。3) 设计自动化评估指标,评估LLM对新术语的理解和应用能力。论文未提供损失函数和网络结构的具体信息,这部分内容未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,新术语会导致LLM性能下降超过20%。即使更新LLM的知识截止日期,也无法完全解决新术语带来的挑战,尤其是在处理更遥远的新术语时。NewTerm 2022和2023的发布,为评估LLM对年度更新的新术语的掌握程度提供了有效的工具。
🎯 应用场景
该研究成果可应用于评估和提升LLM在实时信息处理方面的能力,尤其是在需要处理新术语的场景中,例如舆情分析、智能客服、新闻摘要等。通过使用NewTerm基准测试集,可以更好地了解LLM在新知识方面的表现,并针对性地进行优化,从而提高LLM的实用性和可靠性。
📄 摘要(原文)
Despite their remarkable abilities in various tasks, large language models (LLMs) still struggle with real-time information (e.g., new facts and terms) due to the knowledge cutoff in their development process. However, existing benchmarks focus on outdated content and limited fields, facing difficulties in real-time updating and leaving new terms unexplored. To address this problem, we propose an adaptive benchmark, NewTerm, for real-time evaluation of new terms. We design a highly automated construction method to ensure high-quality benchmark construction with minimal human effort, allowing flexible updates for real-time information. Empirical results on various LLMs demonstrate over 20% performance reduction caused by new terms. Additionally, while updates to the knowledge cutoff of LLMs can cover some of the new terms, they are unable to generalize to more distant new terms. We also analyze which types of terms are more challenging and why LLMs struggle with new terms, paving the way for future research. Finally, we construct NewTerm 2022 and 2023 to evaluate the new terms updated each year and will continue updating annually. The benchmark and codes can be found at https://github.com/hexuandeng/NewTerm.