Mathematical Derivation Graphs: A Relation Extraction Task in STEM Manuscripts
作者: Vishesh Prasad, Brian Kim, Nickvash Kani
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-10-26 (更新: 2026-01-14)
备注: 29 pages, 11 figures
💡 一句话要点
提出数学推导图数据集MDGD,用于STEM文献中公式间关系抽取任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学公式识别 关系抽取 知识图谱 大型语言模型 STEM文献
📋 核心要点
- 现有NLP方法在处理自然语言文本方面表现出色,但在理解STEM文献中数学公式间的复杂关系方面仍存在挑战。
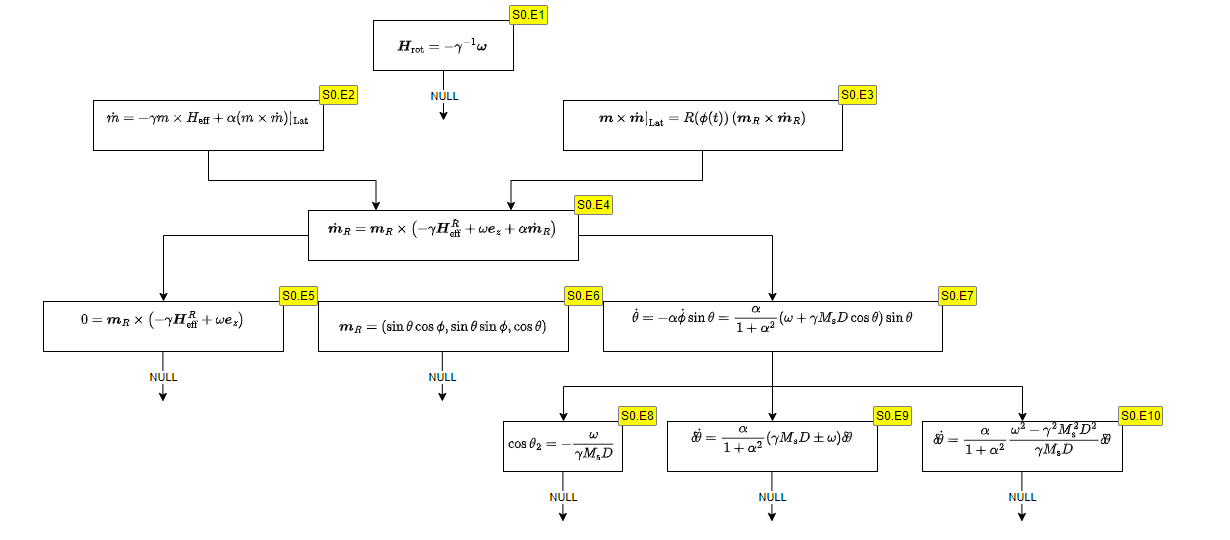
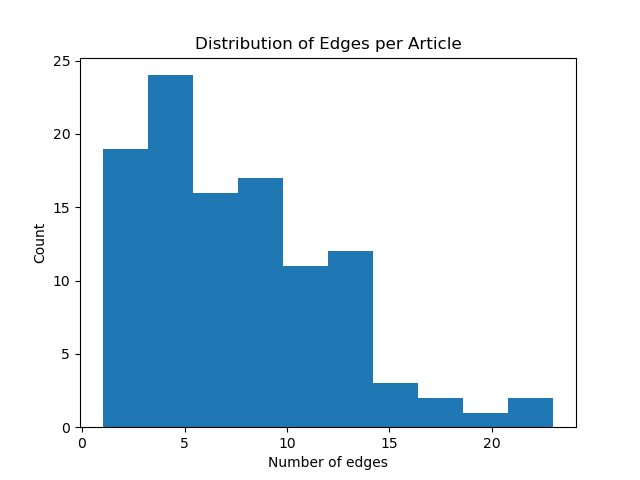
- 论文提出构建数学推导图(MDGD)数据集,通过人工标注公式间的依赖关系,为数学关系抽取任务提供高质量数据。
- 实验评估了多种分析和机器学习模型,包括LLM,在MDGD数据集上的性能,并探索了结合分析算法以提升LLM性能的方法。
📝 摘要(中文)
自然语言处理(NLP)的最新进展,特别是大型语言模型(LLM)的出现,极大地促进了文本分析领域的发展。然而,尽管这些进展在分析自然语言文本方面取得了显著成果,但在将分析应用于数学公式及其在文本中的关系时,结果却喜忧参半。本文旨在扩展关系抽取问题,使其能够理解STEM文章中数学表达式之间的依赖关系,并迈出了初步的探索性步伐。作者构建了数学推导图数据集(MDGD),该数据集来源于arXiv语料库的随机抽样,包含对107篇已发表的STEM手稿的分析,并手动标注了2000多个公式间的依赖关系,从而形成了一种新的对象,称为推导图,它总结了手稿的数学内容。作者详尽地评估了基于分析和机器学习(ML)的模型,以评估它们识别和提取每篇文章的推导关系的能力,并将结果与ground truth进行比较。结果表明,最佳的LLM的F1分数约为45%-52%,并尝试通过将它们与分析算法和其他方法相结合来提高其性能。
🔬 方法详解
问题定义:论文旨在解决STEM文献中数学公式间依赖关系的自动抽取问题。现有方法在处理数学公式及其关系时效果不佳,缺乏专门的数据集和有效的模型来理解公式间的推导逻辑。因此,如何准确识别和提取公式间的依赖关系,构建公式推导图,成为一个重要的研究挑战。
核心思路:论文的核心思路是通过构建一个大规模的、人工标注的数学推导图数据集(MDGD),为训练和评估关系抽取模型提供高质量的ground truth。同时,探索利用现有的NLP模型(特别是LLM)以及结合分析算法的方法,来提高公式间依赖关系抽取的准确率。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据集构建:从arXiv语料库中随机抽取STEM手稿,人工标注公式间的依赖关系,构建MDGD数据集。2) 模型评估:评估现有的分析算法和机器学习模型(包括LLM)在MDGD数据集上的性能。3) 模型优化:尝试将分析算法与LLM相结合,以提高关系抽取的准确率。
关键创新:论文的关键创新在于:1) 构建了首个大规模的数学推导图数据集(MDGD),为公式间关系抽取任务提供了宝贵的数据资源。2) 探索了将分析算法与LLM相结合的方法,以提高关系抽取的准确率。
关键设计:论文中关于数据集构建的关键设计包括:1) 从arXiv语料库中随机抽样,保证数据集的多样性。2) 采用人工标注的方式,保证标注的准确性。3) 定义了清晰的公式间依赖关系类型,方便标注和模型训练。关于模型评估的关键设计包括:1) 采用F1 score作为评估指标,综合考虑了准确率和召回率。2) 对比了多种分析算法和机器学习模型,全面评估了现有方法的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最佳的LLM在MDGD数据集上的F1分数约为45%-52%。通过将LLM与分析算法相结合,可以进一步提高关系抽取的准确率,但提升幅度有限。MDGD数据集的发布为后续研究提供了基准和数据支持,促进了数学公式关系抽取领域的发展。
🎯 应用场景
该研究成果可应用于智能教育、科研文献分析、自动定理证明等领域。通过自动构建数学推导图,可以帮助学生更好地理解数学知识,辅助科研人员快速掌握文献中的数学推导过程,并为自动定理证明提供知识基础。未来,该技术有望促进数学知识的自动化理解和应用。
📄 摘要(原文)
Recent advances in natural language processing (NLP), particularly with the emergence of large language models (LLMs), have significantly enhanced the field of textual analysis. However, while these developments have yielded substantial progress in analyzing natural language text, applying analysis to mathematical equations and their relationships within texts has produced mixed results. This paper takes the initial steps in expanding the problem of relation extraction towards understanding the dependency relationships between mathematical expressions in STEM articles. The authors construct the Mathematical Derivation Graphs Dataset (MDGD), sourced from a random sampling of the arXiv corpus, containing an analysis of $107$ published STEM manuscripts with over $2000$ manually labeled inter-equation dependency relationships, resulting in a new object referred to as a derivation graph that summarizes the mathematical content of the manuscript. The authors exhaustively evaluate analytical and machine learning (ML) based models to assess their capability to identify and extract the derivation relationships for each article and compare the results with the ground truth. The authors show that the best tested LLMs achieve $F_1$ scores of $\sim45\%-52\%$, and attempt to improve their performance by combining them with analytic algorithms and other methods.