UniHGKR: Unified Instruction-aware Heterogeneous Knowledge Retrievers
作者: Dehai Min, Zhiyang Xu, Guilin Qi, Lifu Huang, Chenyu You
分类: cs.IR, cs.CL
发布日期: 2024-10-26 (更新: 2025-02-11)
备注: NAACL 2025, Main, Long Paper
💡 一句话要点
提出UniHGKR,统一指令感知的异构知识检索器,提升开放域问答性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异构知识检索 指令感知 统一检索空间 自监督学习 开放域问答
📋 核心要点
- 现有检索模型难以处理现实世界中普遍存在的异构知识和查询结构。
- UniHGKR通过统一检索空间和指令感知检索,实现对异构知识的有效检索。
- 在CompMix-IR和ConvMix上,UniHGKR显著优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种统一的指令感知异构知识检索器UniHGKR,旨在解决现有信息检索模型在处理异构知识源和用户查询时存在的局限性。UniHGKR构建了一个统一的检索空间来处理异构知识,并遵循不同的用户指令来检索指定类型的知识。该模型包含三个主要阶段:异构自监督预训练、文本锚定的嵌入对齐和指令感知的检索器微调,使其能够泛化到不同的检索场景。该框架具有高度可扩展性,包括一个基于BERT的版本和一个基于大型语言模型的UniHGKR-7B版本。此外,本文还提出了CompMix-IR,这是第一个原生异构知识检索基准,包含两个检索场景,超过9400个问答对和一个包含四种不同类型数据的1000万条条目的语料库。实验结果表明,UniHGKR在CompMix-IR上始终优于最先进的方法,在两个场景中分别实现了高达6.36%和54.23%的相对改进。最后,通过将检索器应用于开放域异构问答系统,在ConvMix任务上取得了新的state-of-the-art结果,绝对提升高达5.90个点。
🔬 方法详解
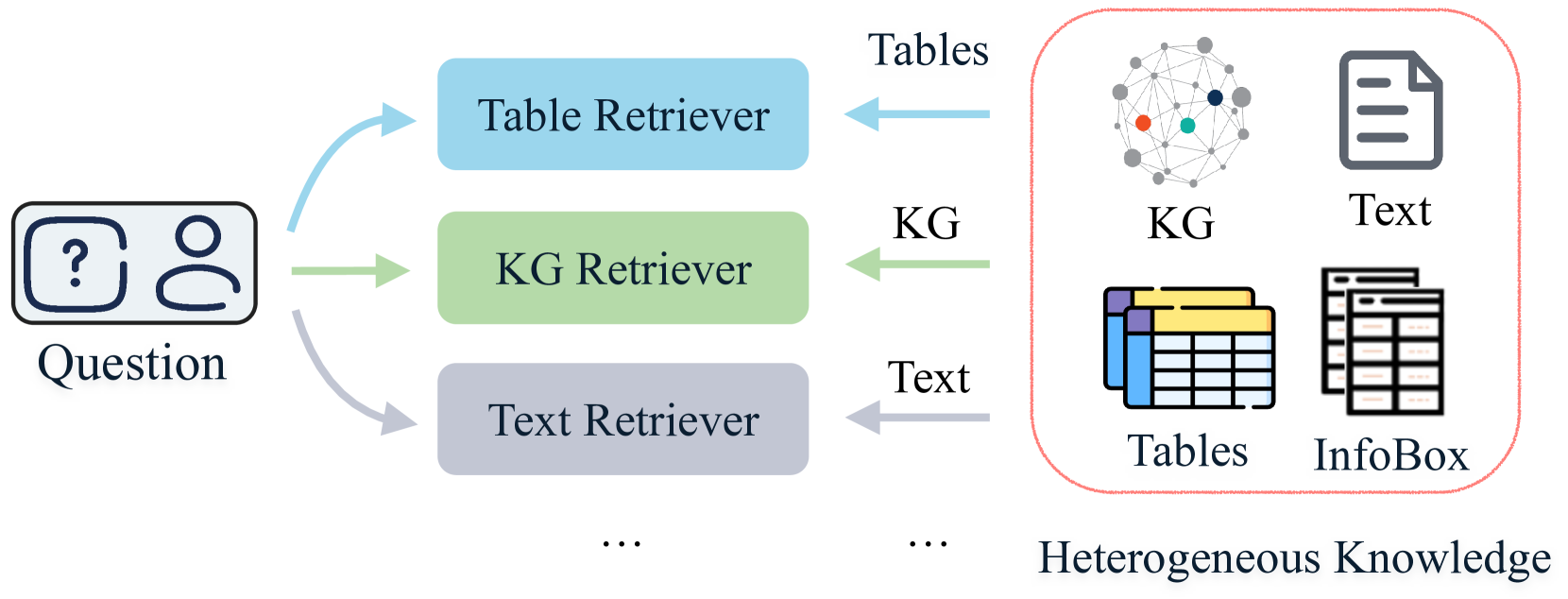
问题定义:现有信息检索模型通常假设知识源和用户查询具有同构结构,这限制了它们在实际场景中的应用,因为实际的检索本质上是异构和多样的。现有的方法难以有效地处理不同类型的知识,并且缺乏根据用户指令检索特定类型知识的能力。
核心思路:UniHGKR的核心思路是构建一个统一的检索空间,将不同类型的知识嵌入到该空间中,并利用指令来指导检索过程。通过这种方式,模型可以根据用户的具体需求,从异构知识源中检索出相关的知识。这种设计使得模型能够更好地适应现实世界中复杂多样的检索场景。
技术框架:UniHGKR包含三个主要阶段:1) 异构自监督预训练:利用自监督学习方法,在大规模异构数据上预训练模型,使其能够理解不同类型知识的语义信息。2) 文本锚定的嵌入对齐:通过文本锚点将不同类型的知识嵌入对齐到统一的语义空间中,使得模型能够比较和匹配不同类型的知识。3) 指令感知的检索器微调:利用指令数据微调检索器,使其能够根据用户指令检索特定类型的知识。
关键创新:UniHGKR的关键创新在于其统一的检索空间和指令感知的检索机制。传统的检索模型通常针对特定类型的知识进行优化,而UniHGKR能够处理多种类型的知识,并根据用户的指令进行灵活的检索。此外,CompMix-IR基准的提出也为异构知识检索的研究提供了新的评估标准。
关键设计:在异构自监督预训练阶段,采用了对比学习的方法,通过最大化正样本之间的相似度,最小化负样本之间的相似度,来学习知识的表示。在文本锚定的嵌入对齐阶段,使用了余弦相似度作为对齐的度量标准。在指令感知的检索器微调阶段,使用了交叉熵损失函数来优化模型。
🖼️ 关键图片


📊 实验亮点
UniHGKR在CompMix-IR基准测试中,相较于现有最佳方法,在两个检索场景中分别取得了6.36%和54.23%的相对提升。此外,在ConvMix开放域问答任务中,UniHGKR取得了新的state-of-the-art结果,绝对提升高达5.90个点,验证了其在实际应用中的有效性。
🎯 应用场景
UniHGKR可应用于开放域问答系统、智能助手、知识图谱构建等领域。通过整合不同来源的异构知识,并根据用户指令进行精准检索,可以显著提升这些应用的性能和用户体验。未来,该技术有望推动知识驱动的人工智能应用发展。
📄 摘要(原文)
Existing information retrieval (IR) models often assume a homogeneous structure for knowledge sources and user queries, limiting their applicability in real-world settings where retrieval is inherently heterogeneous and diverse. In this paper, we introduce UniHGKR, a unified instruction-aware heterogeneous knowledge retriever that (1) builds a unified retrieval space for heterogeneous knowledge and (2) follows diverse user instructions to retrieve knowledge of specified types. UniHGKR consists of three principal stages: heterogeneous self-supervised pretraining, text-anchored embedding alignment, and instruction-aware retriever fine-tuning, enabling it to generalize across varied retrieval contexts. This framework is highly scalable, with a BERT-based version and a UniHGKR-7B version trained on large language models. Also, we introduce CompMix-IR, the first native heterogeneous knowledge retrieval benchmark. It includes two retrieval scenarios with various instructions, over 9,400 question-answer (QA) pairs, and a corpus of 10 million entries, covering four different types of data. Extensive experiments show that UniHGKR consistently outperforms state-of-the-art methods on CompMix-IR, achieving up to 6.36% and 54.23% relative improvements in two scenarios, respectively. Finally, by equipping our retriever for open-domain heterogeneous QA systems, we achieve a new state-of-the-art result on the popular ConvMix task, with an absolute improvement of up to 5.90 points.