Dynamic layer selection in decoder-only transformers
作者: Theodore Glavas, Joud Chataoui, Florence Regol, Wassim Jabbour, Antonios Valkanas, Boris N. Oreshkin, Mark Coates
分类: cs.CL, cs.LG
发布日期: 2024-10-26
💡 一句话要点
研究decoder-only Transformer的动态层选择,实现高效自然语言生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态推理 层选择 Decoder-only Transformer 自然语言生成 模型优化
📋 核心要点
- 大型语言模型推理成本高昂,动态推理是降低成本的有效途径,但如何有效应用仍是挑战。
- 探索层跳跃和提前退出两种动态推理方法,着重研究decoder-only Transformer的层选择策略。
- 实验表明层跳跃更适合decoder-only模型,且基于序列的动态计算分配能显著提升效率。
📝 摘要(中文)
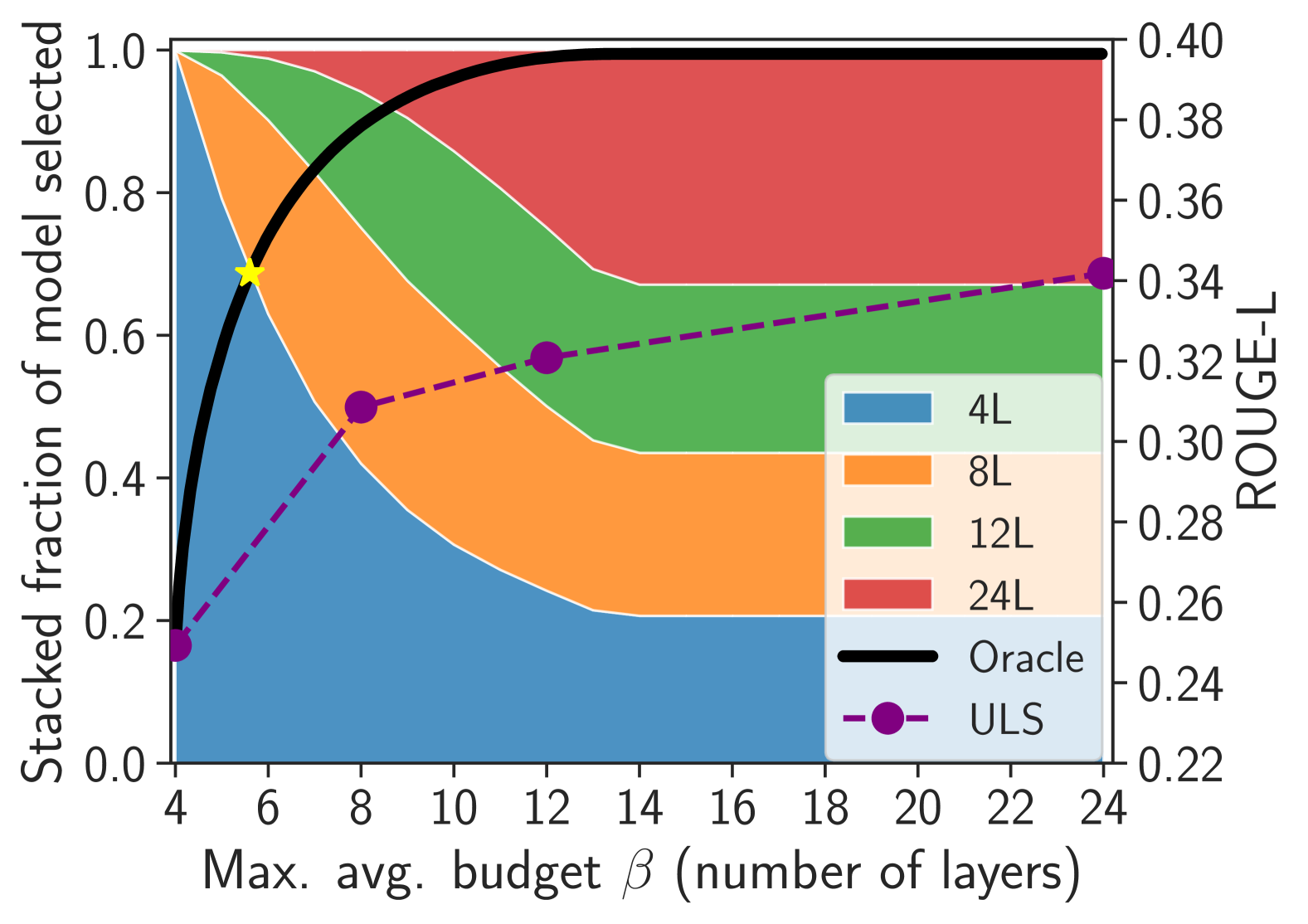
大型语言模型(LLM)的巨大规模促使人们寻求优化推理的方法。一种有效的方法是动态推理,它根据具体样本调整架构,以降低整体计算成本。本文实证研究了自然语言生成(NLG)中两种常见的动态推理方法:层跳跃(layer skipping)和提前退出(early exiting)。研究发现,预训练的decoder-only模型在通过层跳跃移除层时,比提前退出更具鲁棒性。本文还展示了使用隐藏状态信息在每个token的基础上调整计算以进行层跳跃的难度。最后,通过构建一个oracle控制器,证明了在每个序列的基础上进行动态计算分配,有望通过显著的效率提升。值得注意的是,研究发现存在一种分配方案,仅使用平均23.3%的层即可实现与完整模型相同的性能。
🔬 方法详解
问题定义:大型语言模型在推理时计算成本高昂,尤其是在自然语言生成任务中。现有的静态模型对所有输入都执行相同的计算,忽略了不同输入可能需要的计算量差异。提前退出和层跳跃是两种常见的动态推理方法,但它们在decoder-only Transformer上的表现和适用性尚不明确。
核心思路:本文的核心思路是探索decoder-only Transformer中动态层选择的有效策略,通过自适应地调整模型使用的层数来降低推理成本。具体而言,研究比较了层跳跃和提前退出两种方法,并探索了基于token和基于序列的动态计算分配策略。
技术框架:本文主要研究了两种动态推理方法:1) 层跳跃:允许模型跳过某些层,直接将上一层的输出传递到后面的层。2) 提前退出:在某些层之后添加退出点,如果模型在该点已经足够自信,则提前结束推理。研究通过构建一个oracle控制器来评估基于序列的动态计算分配的潜力。该控制器可以根据序列的特性选择最佳的层配置。
关键创新:本文的关键创新在于发现decoder-only Transformer对层跳跃比提前退出更具鲁棒性。此外,本文还证明了基于序列的动态计算分配具有显著的效率提升潜力,并构建了一个oracle控制器来验证这一潜力。
关键设计:本文使用了预训练的decoder-only Transformer模型,并对其进行了微调以适应自然语言生成任务。对于层跳跃,研究尝试使用隐藏状态信息来预测是否跳过某一层,但效果不佳。对于基于序列的动态计算分配,研究构建了一个oracle控制器,该控制器通过穷举搜索找到每个序列的最佳层配置。评估指标包括模型的性能(如困惑度)和计算成本(如使用的层数)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,decoder-only Transformer模型对层跳跃具有较强的鲁棒性。更重要的是,通过构建oracle控制器,研究发现存在一种层分配方案,仅使用平均23.3%的层即可达到与完整模型相同的性能,这表明动态层选择具有巨大的效率提升潜力。
🎯 应用场景
该研究成果可应用于各种自然语言生成任务,例如文本摘要、机器翻译和对话生成。通过动态调整模型使用的层数,可以显著降低推理成本,使得大型语言模型能够在资源受限的环境中部署,并加速AI应用的普及。
📄 摘要(原文)
The vast size of Large Language Models (LLMs) has prompted a search to optimize inference. One effective approach is dynamic inference, which adapts the architecture to the sample-at-hand to reduce the overall computational cost. We empirically examine two common dynamic inference methods for natural language generation (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only model is significantly more robust to layer removal via layer skipping, as opposed to early exit. We demonstrate the difficulty of using hidden state information to adapt computation on a per-token basis for layer skipping. Finally, we show that dynamic computation allocation on a per-sequence basis holds promise for significant efficiency gains by constructing an oracle controller. Remarkably, we find that there exists an allocation which achieves equal performance to the full model using only 23.3% of its layers on average.