Vulnerability of LLMs to Vertically Aligned Text Manipulations
作者: Zhecheng Li, Yiwei Wang, Bryan Hooi, Yujun Cai, Zhen Xiong, Nanyun Peng, Kai-wei Chang
分类: cs.CL
发布日期: 2024-10-26 (更新: 2025-09-25)
备注: Accepted to ACL 2025 (Main)
💡 一句话要点
揭示LLM在垂直对齐文本输入下的脆弱性,并分析其内在原因
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 垂直文本 文本分类 脆弱性分析 对抗性攻击
📋 核心要点
- 现有LLM在处理垂直文本等非标准格式输入时存在明显脆弱性,容易被误导,影响其在实际场景中的可靠性。
- 该研究通过系统性实验,分析了垂直文本输入对LLM性能的影响,并深入探究了其内在原因,为提升模型鲁棒性提供依据。
- 实验结果表明,垂直文本输入会显著降低LLM的文本分类准确率,思维链推理无法有效缓解,但少量样本学习在特定情况下有所帮助。
📝 摘要(中文)
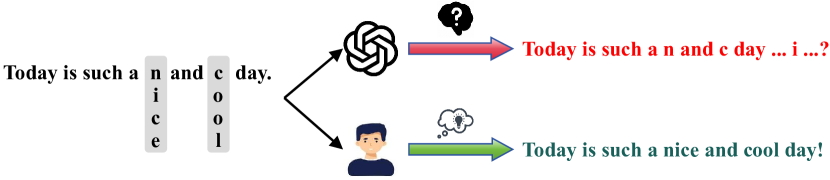
本文研究了大型语言模型(LLM)在垂直文本输入下的脆弱性。垂直文本在数学计算和填字游戏中很常见。尽管LLM在自然语言任务中表现出色,但它们对文本格式的变化仍然很敏感。研究表明,垂直对齐单词等输入格式的修改会显著降低文本分类任务的准确性。虽然人类容易理解,但这些输入可能会严重误导模型,从而可能绕过涉及有害或敏感信息的实际场景中的检测。随着LLM应用的扩展,一个关键问题是:基于解码器的LLM是否表现出与垂直格式文本输入相似的脆弱性?本文通过多个文本分类数据集,研究了垂直文本输入对各种LLM性能的影响,并分析了其根本原因。研究发现:(i)垂直文本输入会显著降低LLM在文本分类任务中的准确性。(ii)思维链(CoT)推理无助于LLM识别垂直输入或减轻其脆弱性,但通过仔细分析的少量样本学习可以。(iii)通过分析分词和注意力矩阵中的固有问题,探索了这种脆弱性的根本原因。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理垂直对齐文本输入时的脆弱性。现有LLM在处理标准自然语言任务时表现出色,但对于非标准格式的文本,例如垂直排列的文本,其性能会显著下降。这种脆弱性可能被恶意利用,绕过安全检测,造成潜在风险。
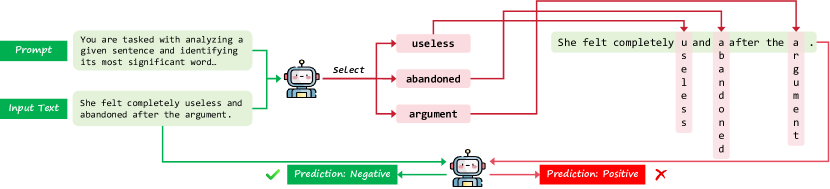
核心思路:论文的核心思路是通过系统性地实验,评估不同LLM在垂直文本输入下的性能表现,并深入分析导致这种脆弱性的内在原因。通过分析分词过程和注意力机制,揭示模型在处理非标准格式文本时遇到的挑战。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个文本分类数据集;2) 将数据集中的文本转换为垂直对齐的格式;3) 使用不同的LLM(包括不同架构和规模的模型)对垂直文本进行分类;4) 评估模型的分类准确率,并与在标准文本上的性能进行比较;5) 分析分词结果和注意力矩阵,以探究模型出错的原因。
关键创新:该研究的关键创新在于:1) 首次系统性地研究了LLM在垂直文本输入下的脆弱性;2) 通过分析分词和注意力机制,揭示了导致这种脆弱性的内在原因;3) 验证了思维链推理在这种情况下无效,但少量样本学习在特定情况下可以缓解这种脆弱性。
关键设计:在实验设计方面,论文选择了多个具有代表性的文本分类数据集,并使用了多种不同架构和规模的LLM,以保证研究结果的泛化性。在分析方面,论文重点关注分词结果和注意力矩阵,通过可视化和统计分析,揭示模型在处理垂直文本时遇到的问题。此外,论文还尝试了不同的缓解策略,例如思维链推理和少量样本学习,以评估其有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,垂直文本输入会导致LLM在文本分类任务中的准确率显著下降。例如,在某些数据集上,准确率下降幅度超过50%。思维链推理无法有效缓解这种脆弱性,但通过仔细分析的少量样本学习可以在一定程度上提高模型的性能。研究还发现,分词和注意力机制是导致这种脆弱性的关键因素。
🎯 应用场景
该研究成果可应用于提升LLM在处理非标准格式文本时的鲁棒性,例如在OCR识别、数学公式识别等领域。此外,该研究也提醒开发者关注LLM在面对对抗性攻击时的潜在风险,并采取相应的防御措施,提高模型的安全性。
📄 摘要(原文)
Vertical text input is commonly encountered in various real-world applications, such as mathematical computations and word-based Sudoku puzzles. While current large language models (LLMs) have excelled in natural language tasks, they remain vulnerable to variations in text formatting. Recent research demonstrates that modifying input formats, such as vertically aligning words for encoder-based models, can substantially lower accuracy in text classification tasks. While easily understood by humans, these inputs can significantly mislead models, posing a potential risk of bypassing detection in real-world scenarios involving harmful or sensitive information. With the expanding application of LLMs, a crucial question arises: Do decoder-based LLMs exhibit similar vulnerabilities to vertically formatted text input? In this paper, we investigate the impact of vertical text input on the performance of various LLMs across multiple text classification datasets and analyze the underlying causes. Our findings are as follows: (i) Vertical text input significantly degrades the accuracy of LLMs in text classification tasks. (ii) Chain-of-Thought (CoT) reasoning does not help LLMs recognize vertical input or mitigate its vulnerability, but few-shot learning with careful analysis does. (iii) We explore the underlying cause of the vulnerability by analyzing the inherent issues in tokenization and attention matrices.