Counting Ability of Large Language Models and Impact of Tokenization
作者: Xiang Zhang, Juntai Cao, Chenyu You
分类: cs.CL, cs.AI
发布日期: 2024-10-25 (更新: 2024-10-29)
💡 一句话要点
研究揭示分词策略对大语言模型计数能力的影响,并提出改进方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 计数能力 分词策略 Transformer 思维链 字节对编码 推理能力
📋 核心要点
- Transformer架构的固有局限性,使其在处理需要深度推理的任务(如计数)时面临挑战。
- 该研究着重考察了通用大语言模型中,分词策略对模型计数能力的影响,这是以往研究较少关注的。
- 通过理论分析和实验验证,揭示了不同分词策略对模型性能的显著影响,并为改进分词方法提供了思路。
📝 摘要(中文)
Transformer架构是现代大语言模型(LLMs)的基础,但其固有的架构限制阻碍了其推理能力。与循环网络不同,Transformer缺乏循环连接,将其限制在恒定深度的计算中。这种限制使其在复杂度类别中属于TC$^0$,理论上无法解决需要随着输入长度增长而增加推理深度的任务。计数是许多推理任务的基本组成部分,也需要推理深度线性增长才能进行归纳执行。虽然之前的研究已经确定了基于Transformer的专家模型(即专门为计数任务训练的模型)的计数能力的上限,但由于推理机制的差异,这些发现并不能直接推广到通用LLM。最近的研究强调了思维链(CoT)推理如何帮助缓解Transformer在计数任务中的一些架构限制。然而,很少有人关注分词在这种模型中的作用。与通常使用字符级分词的专家模型不同,LLM通常依赖于字节级(BPE)分词器,这从根本上改变了推理的处理方式。本文研究了分词对LLM计数能力的影响,揭示了基于输入分词差异的显著性能变化。我们提供了理论和实验分析,深入了解了分词选择如何破坏模型的理论可计算性,从而激发了新的分词方法的设计,以增强LLM的推理能力。
🔬 方法详解
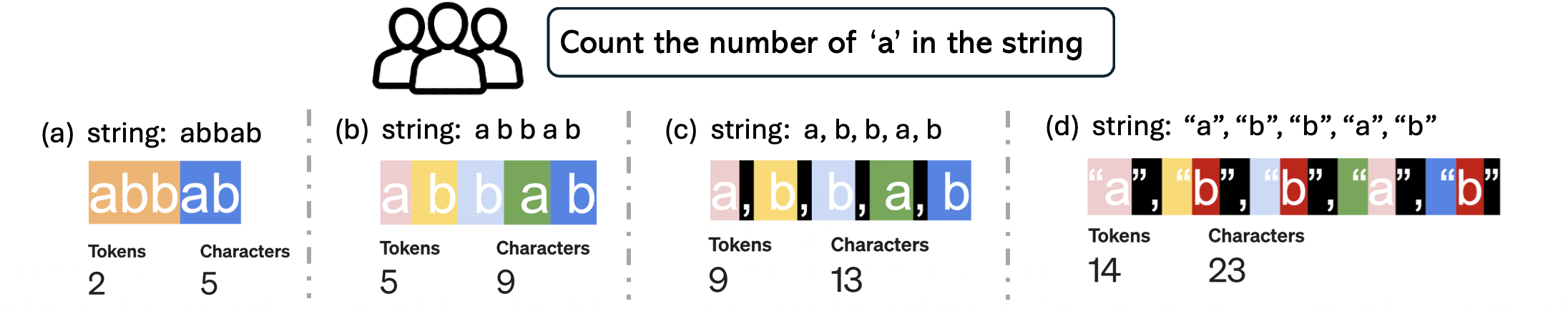
问题定义:论文旨在研究通用大语言模型(LLMs)在计数任务中的能力,并着重关注分词策略对模型性能的影响。现有研究主要集中在专家模型上,且忽略了通用LLM中常用的字节对编码(BPE)分词器对计数能力的影响。现有方法的痛点在于,没有充分考虑分词策略对LLM理论计算能力和实际性能的潜在影响。
核心思路:论文的核心思路是,通过理论分析和实验验证,揭示分词策略如何影响LLM的计数能力。具体来说,研究考察了不同分词策略下,模型对计数任务的性能差异,并分析了这些差异背后的原因。研究认为,分词策略的选择会影响模型对输入信息的编码方式,从而影响其推理能力。
技术框架:论文的技术框架主要包括以下几个部分:1) 理论分析:分析不同分词策略对模型理论计算能力的影响;2) 实验设计:设计一系列计数任务,评估不同分词策略下LLM的性能;3) 结果分析:分析实验结果,揭示分词策略对模型计数能力的影响;4) 改进建议:基于分析结果,提出改进分词策略的建议。
关键创新:论文的关键创新在于,首次系统性地研究了分词策略对通用LLM计数能力的影响。以往研究主要集中在专家模型上,且忽略了分词策略的重要性。该研究揭示了分词策略的选择会显著影响LLM的计数能力,并为改进分词方法提供了新的思路。
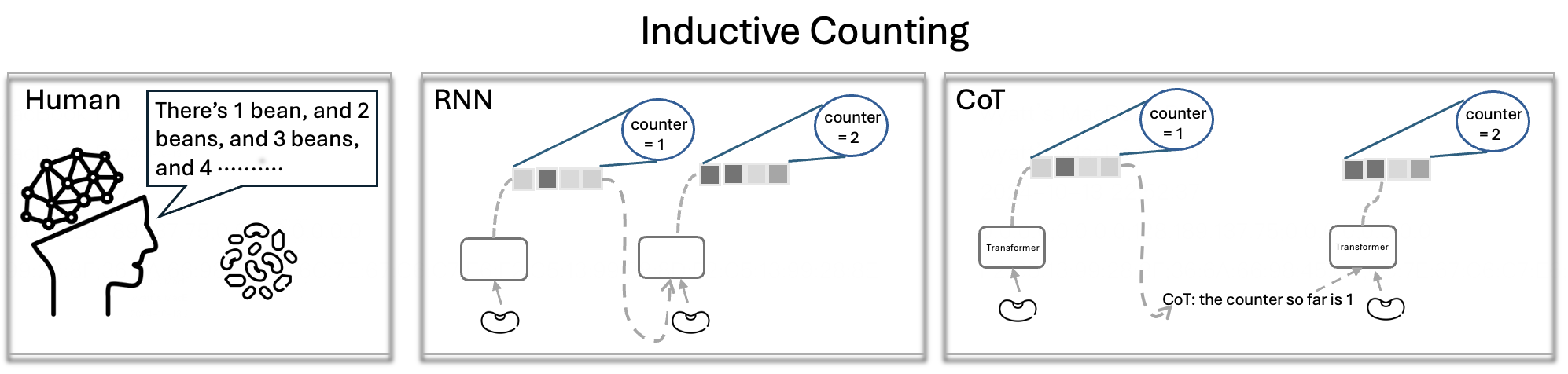
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM模型进行实验;2) 设计多种计数任务,覆盖不同的难度级别;3) 采用不同的分词策略,包括字符级分词和字节对编码(BPE)分词;4) 使用思维链(CoT)推理,以提高模型的计数能力;5) 对实验结果进行详细的统计分析,并进行理论解释。
🖼️ 关键图片

📊 实验亮点
研究表明,分词策略对LLM的计数能力有显著影响。例如,在特定计数任务中,使用字符级分词的模型性能优于使用BPE分词的模型。实验结果还表明,思维链(CoT)推理可以缓解分词策略带来的负面影响,但不能完全消除。具体性能数据和提升幅度在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于提升大语言模型在需要精确计数的任务中的表现,例如文本摘要、机器翻译、问答系统等。通过优化分词策略,可以提高模型对输入信息的理解和推理能力,从而提升整体性能。此外,该研究也为未来设计更高效的分词算法提供了理论指导。
📄 摘要(原文)
Transformers, the backbone of modern large language models (LLMs), face inherent architectural limitations that impede their reasoning capabilities. Unlike recurrent networks, Transformers lack recurrent connections, confining them to constant-depth computation. This restriction places them in the complexity class TC$^0$, making them theoretically incapable of solving tasks that demand increasingly deep reasoning as input length grows. Counting, a fundamental component of many reasoning tasks, also requires reasoning depth to grow linearly to be performed inductively. While previous studies have established the upper limits of counting ability in Transformer-based expert models (i.e., models specifically trained for counting tasks), these findings do not directly extend to general-purpose LLMs due to differences in reasoning mechanisms. Recent work has highlighted how Chain of Thought (CoT) reasoning can help alleviate some of the architectural limitations of Transformers in counting tasks. However, little attention has been paid to the role of tokenization in these models. Unlike expert models that often use character-level tokenization, LLMs typically rely on byte-level (BPE) tokenizers, which fundamentally alters the way reasoning is processed. Our work investigates the impact of tokenization on the counting abilities of LLMs, uncovering substantial performance variations based on input tokenization differences. We provide both theoretical and experimental analyses, offering insights into how tokenization choices can undermine models' theoretical computability, thereby inspiring the design of new tokenization methods to enhance reasoning in LLMs.