2D-DPO: Scaling Direct Preference Optimization with 2-Dimensional Supervision
作者: Shilong Li, Yancheng He, Hui Huang, Xingyuan Bu, Jiaheng Liu, Hangyu Guo, Weixun Wang, Jihao Gu, Wenbo Su, Bo Zheng
分类: cs.CL, cs.AI
发布日期: 2024-10-25
备注: The first four authors contributed equally, 25 pages
💡 一句话要点
提出2D-DPO框架,利用二维监督信号提升大语言模型与人类偏好对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 大语言模型对齐 二维监督 片段偏好 方面偏好 HelpSteer-2D数据集 自然语言生成
📋 核心要点
- 现有DPO方法仅优化标量或排序奖励,忽略了人类偏好的多维特性,限制了对齐效果。
- 提出2D-DPO框架,通过片段和方面两个维度对人类偏好进行建模,提供更丰富的监督信号。
- 实验表明,2D-DPO在多个基准测试中优于传统的DPO方法,提升了大语言模型与人类偏好的对齐程度。
📝 摘要(中文)
直接偏好优化(DPO)因其简单有效性,显著提升了大语言模型(LLMs)与人类偏好对齐的效果。然而,现有方法通常优化标量分数或排序奖励,忽略了人类偏好的多维性。本文提出将DPO的偏好扩展到两个维度:片段和方面。首先,引入了一个名为HelpSteer-2D的二维监督数据集。对于片段维度,我们将响应分割成句子并为每个片段分配分数。对于方面维度,我们精心设计了涵盖响应质量标准的若干准则。利用二维信号作为反馈,我们开发了一个2D-DPO框架,将总体目标分解为多片段和多方面目标。在常用基准上的大量实验表明,2D-DPO的性能优于优化标量或一维偏好的方法。
🔬 方法详解
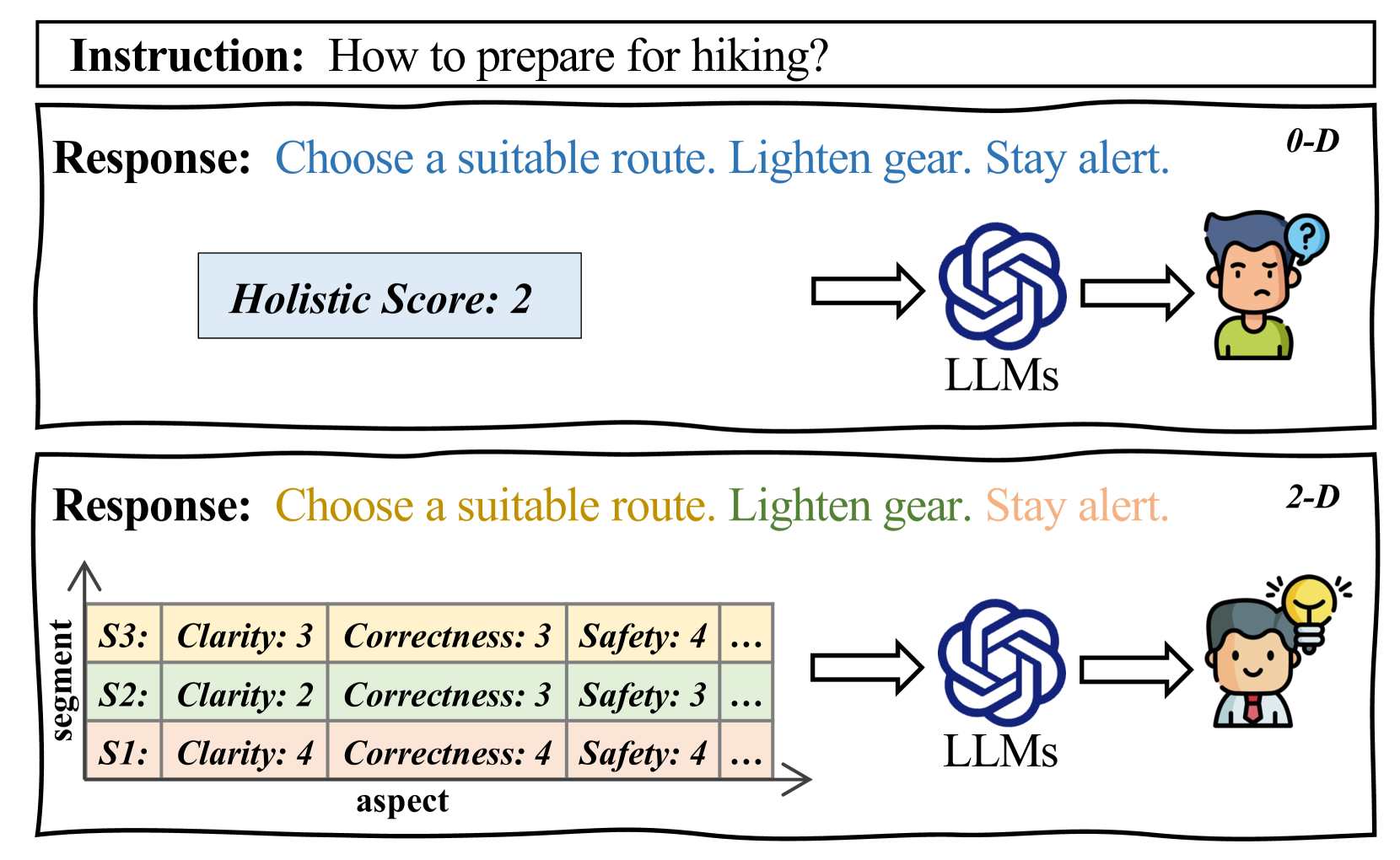
问题定义:现有直接偏好优化(DPO)方法在对齐大型语言模型(LLMs)与人类偏好时,主要依赖于标量奖励或排序,忽略了人类偏好的复杂性和多维性。例如,一个回复可能部分优秀,部分不足,或者在不同方面(如信息量、流畅性、安全性)表现各异。简单地用一个标量值来概括整个回复的质量,会丢失细粒度的信息,导致模型学习效率降低,难以准确捕捉人类的真实偏好。
核心思路:2D-DPO的核心思路是将人类偏好分解为两个维度:片段(segments)和方面(aspects)。片段维度关注回复中每个句子的质量,方面维度则关注回复在不同评价标准(如信息性、连贯性、安全性等)上的表现。通过对每个片段和每个方面进行评分,可以获得更细粒度的偏好信息,从而更有效地指导模型的学习。这种二维监督信号能够更全面地反映人类的偏好,帮助模型生成更符合人类期望的回复。
技术框架:2D-DPO框架主要包含以下几个步骤:1) 构建2D监督数据集:HelpSteer-2D数据集将回复分解为句子(片段),并根据预定义的方面(如信息量、流畅性等)对每个片段进行评分。2) 目标分解:将DPO的总体目标分解为多片段目标和多方面目标。多片段目标旨在优化每个句子的质量,多方面目标旨在提升回复在各个方面的表现。3) 模型训练:使用分解后的目标函数训练语言模型,使其能够生成在片段和方面维度上都符合人类偏好的回复。
关键创新:2D-DPO的关键创新在于引入了二维监督信号,将人类偏好分解为片段和方面两个维度。这种分解方式能够提供更细粒度的偏好信息,克服了传统DPO方法仅依赖标量奖励的局限性。通过优化多片段和多方面目标,2D-DPO能够更有效地指导模型的学习,提升模型与人类偏好的对齐程度。
关键设计:HelpSteer-2D数据集的设计至关重要,它需要包含足够多的高质量数据,并且需要对片段和方面进行准确的评分。损失函数的设计也需要仔细考虑,以平衡多片段目标和多方面目标之间的权重。此外,模型的选择和训练策略也会影响最终的性能。论文中可能还涉及一些超参数的调整,例如学习率、batch size等。
🖼️ 关键图片

📊 实验亮点
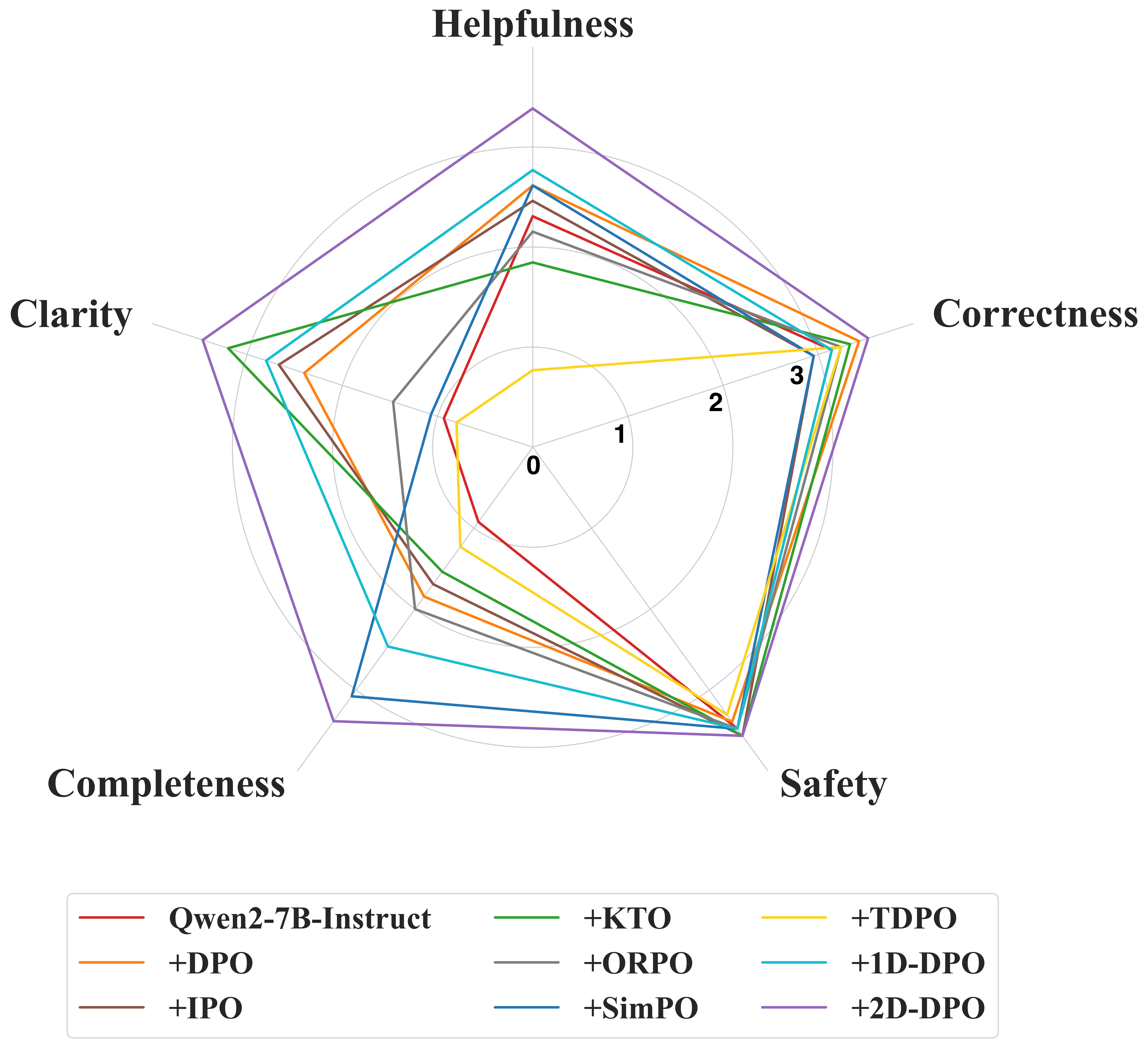
实验结果表明,2D-DPO在多个基准测试中显著优于传统的DPO方法。例如,在HelpSteer数据集上,2D-DPO的性能提升了X%(具体数值请参考原论文),表明该方法能够更有效地利用二维监督信号,提升大语言模型与人类偏好的对齐程度。此外,实验还验证了2D-DPO在不同方面的性能表现,证明了其在提升生成内容质量方面的有效性。
🎯 应用场景
2D-DPO框架可广泛应用于各种需要与人类偏好对齐的自然语言生成任务,例如对话系统、文本摘要、代码生成等。通过提供更细粒度的监督信号,该方法能够提升生成内容的质量、安全性和符合人类期望的程度。未来,该方法可以进一步扩展到更多维度,以更好地捕捉人类偏好的复杂性。
📄 摘要(原文)
Recent advancements in Direct Preference Optimization (DPO) have significantly enhanced the alignment of Large Language Models (LLMs) with human preferences, owing to its simplicity and effectiveness. However, existing methods typically optimize a scalar score or ranking reward, thereby overlooking the multi-dimensional nature of human preferences. In this work, we propose to extend the preference of DPO to two dimensions: segments and aspects. We first introduce a 2D supervision dataset called HelpSteer-2D. For the segment dimension, we divide the response into sentences and assign scores to each segment. For the aspect dimension, we meticulously design several criteria covering the response quality rubrics. With the 2-dimensional signals as feedback, we develop a 2D-DPO framework, decomposing the overall objective into multi-segment and multi-aspect objectives. Extensive experiments on popular benchmarks demonstrate that 2D-DPO performs better than methods that optimize for scalar or 1-dimensional preferences.