Retrieving Implicit and Explicit Emotional Events Using Large Language Models
作者: Guimin Hu, Hasti Seifi
分类: cs.CL
发布日期: 2024-10-24 (更新: 2024-12-01)
💡 一句话要点
利用大型语言模型进行隐式和显式情感事件检索
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 情感检索 常识推理 监督对比学习 隐式情感 显式情感 情感计算
📋 核心要点
- 现有研究对大型语言模型的情感检索能力,尤其是在隐式情感方面,探索不足。
- 论文提出一种监督对比探测方法,用于评估LLMs在隐式和显式情感检索上的性能。
- 实验结果揭示了LLMs在情感检索方面的优势和局限性,为后续研究提供了参考。
📝 摘要(中文)
近年来,大型语言模型(LLMs)因其卓越的性能而备受关注。尽管大量研究从各个角度评估了这些模型,但LLMs在执行隐式和显式情感检索方面的能力在很大程度上仍未得到探索。为了弥补这一差距,本研究调查了LLMs在常识推理中的情感检索能力。通过涉及多个模型的广泛实验,我们系统地评估了LLMs在情感检索方面的能力。具体来说,我们提出了一种监督对比探测方法,以验证LLMs在隐式和显式情感检索以及它们检索的情感事件多样性方面的性能。结果为LLMs在处理情感检索方面的优势和局限性提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在常识推理中检索隐式和显式情感事件的能力。现有方法缺乏对LLMs情感检索能力的系统性评估,尤其是在区分和理解隐式情感方面存在挑战。这限制了我们对LLMs在情感理解和推理方面的能力的全面认识。
核心思路:论文的核心思路是利用监督对比学习来探测LLMs的情感检索能力。通过构建包含情感事件对的数据集,并训练LLMs区分具有相似或不同情感的事件,从而评估其情感理解和检索能力。这种方法允许研究者量化LLMs在隐式和显式情感理解方面的表现。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 构建包含情感事件对的数据集,这些事件对可以是具有相似情感的(正例对)或具有不同情感的(负例对)。2) 使用LLMs对每个情感事件进行编码,生成事件的向量表示。3) 利用监督对比学习的目标函数,训练LLMs区分正例对和负例对。4) 通过评估LLMs在区分情感事件对上的准确率和召回率,来衡量其情感检索能力。
关键创新:该研究的关键创新在于提出了一种基于监督对比学习的探测方法,用于评估LLMs在隐式和显式情感检索方面的能力。与传统的评估方法相比,该方法能够更细粒度地分析LLMs的情感理解能力,并区分其在处理不同类型情感事件时的表现。
关键设计:论文的关键设计包括:1) 精心构建包含情感事件对的数据集,确保数据集的多样性和代表性。2) 选择合适的LLMs作为研究对象,例如BERT、RoBERTa等。3) 设计有效的监督对比学习目标函数,例如InfoNCE损失函数,以最大化正例对之间的相似性,最小化负例对之间的相似性。4) 采用合适的评估指标,例如准确率、召回率和F1值,来衡量LLMs的情感检索性能。
🖼️ 关键图片

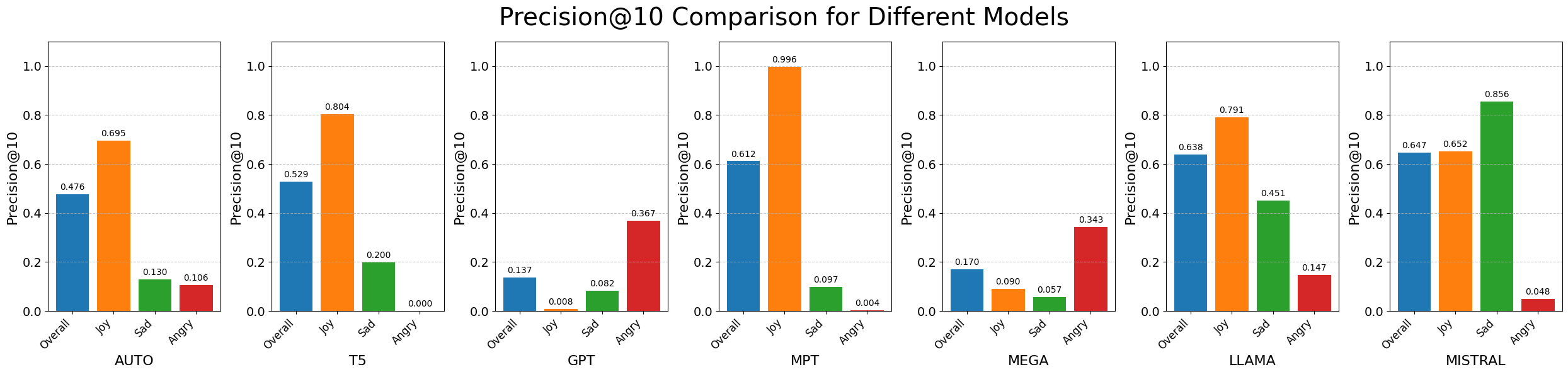

📊 实验亮点
实验结果表明,LLMs在显式情感检索方面表现良好,但在隐式情感检索方面仍存在一定的局限性。监督对比探测方法能够有效地评估LLMs的情感检索能力,并揭示其在处理不同类型情感事件时的优势和不足。具体性能数据未知,但该研究为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于情感计算、人机交互、智能客服等领域。例如,可以利用LLMs的情感检索能力来改善聊天机器人的情感理解能力,使其能够更好地理解用户的情感需求并做出相应的回应。此外,该研究还可以为开发更具情感智能的AI系统提供理论基础和技术支持。
📄 摘要(原文)
Large language models (LLMs) have garnered significant attention in recent years due to their impressive performance. While considerable research has evaluated these models from various perspectives, the extent to which LLMs can perform implicit and explicit emotion retrieval remains largely unexplored. To address this gap, this study investigates LLMs' emotion retrieval capabilities in commonsense. Through extensive experiments involving multiple models, we systematically evaluate the ability of LLMs on emotion retrieval. Specifically, we propose a supervised contrastive probing method to verify LLMs' performance for implicit and explicit emotion retrieval, as well as the diversity of the emotional events they retrieve. The results offer valuable insights into the strengths and limitations of LLMs in handling emotion retrieval.