Bridge-Coder: Unlocking LLMs' Potential to Overcome Language Gaps in Low-Resource Code
作者: Jipeng Zhang, Jianshu Zhang, Yuanzhe Li, Renjie Pi, Rui Pan, Runtao Liu, Ziqiang Zheng, Tong Zhang
分类: cs.CL
发布日期: 2024-10-24
备注: 15 pages, 3 figures
💡 一句话要点
Bridge-Coder:利用LLM弥合低资源代码语言的语言差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源编程语言 代码生成 大型语言模型 桥梁学习 数据增强
📋 核心要点
- 现有方法在低资源编程语言(LRPLs)上的代码生成效果差,主要原因是自然语言到编程语言的差距(NL-PL Gap)以及缺乏高质量的训练数据。
- Bridge-Coder利用LLM在高资源编程语言上的优势和通用知识,通过桥梁生成和桥梁对齐两个阶段,提升LLM在LRPLs上的性能。
- 实验结果表明,Bridge-Coder在多个LRPLs上显著提高了模型性能,验证了该方法的有效性和泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在生成高资源编程语言(HRPLs)(如Python)的代码方面表现出强大的能力,但在低资源编程语言(LRPLs)(如Racket或D)方面表现不佳。这种性能差距加剧了数字鸿沟,使得使用LRPLs的开发者无法平等地从LLM的进步中受益,并加剧了代表性不足的编程社区内部的创新差距。为LRPLs生成额外的训练数据很有前景,但面临两个关键挑战:手动标注劳动强度大且成本高昂,并且LLM生成的LRPL代码通常质量不高。这个问题的根本原因是自然语言到编程语言的差距(NL-PL Gap),由于对齐数据的限制,这在LRPLs中尤其明显。在这项工作中,我们引入了一种名为Bridge-Coder的新方法,该方法利用LLM的内在能力来提高LRPLs的性能。我们的方法包括两个关键阶段:桥梁生成,我们利用LLM的通用知识理解、HRPLs的熟练程度和上下文学习能力来创建高质量的数据集;然后,我们应用桥梁对齐,逐步提高NL指令和LRPLs之间的对齐。跨多个LRPLs的实验结果表明,Bridge-Coder显着提高了模型性能,证明了我们方法的有效性和泛化性。此外,我们对该方法的关键组成部分进行了详细分析,为未来旨在解决与LRPLs相关的挑战的工作提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在低资源编程语言(LRPLs)上代码生成能力不足的问题。现有方法,如直接使用LLM生成LRPL代码或手动标注数据,效果不佳,原因在于LRPLs缺乏足够的训练数据,且手动标注成本高昂,LLM直接生成的LRPL代码质量也难以保证。
核心思路:论文的核心思路是利用LLM在高资源编程语言(HRPLs)上的优势和通用知识,通过构建一个“桥梁”,将自然语言指令与LRPL代码联系起来。具体来说,首先利用LLM生成高质量的HRPL代码,然后将HRPL代码翻译成LRPL代码,从而生成高质量的LRPL训练数据。
技术框架:Bridge-Coder方法包含两个主要阶段:桥梁生成(Bridge Generation)和桥梁对齐(Bridged Alignment)。在桥梁生成阶段,利用LLM的通用知识理解、HRPLs的熟练程度和上下文学习能力,生成高质量的HRPL代码和对应的LRPL代码,构建训练数据集。在桥梁对齐阶段,使用生成的数据集对LLM进行微调,逐步提高NL指令和LRPLs之间的对齐。
关键创新:该方法最重要的创新点在于利用LLM自身的能力,通过HRPL作为桥梁,生成高质量的LRPL训练数据,从而避免了手动标注的成本和LLM直接生成LRPL代码质量差的问题。与现有方法相比,Bridge-Coder能够更有效地利用LLM的知识,提升其在LRPLs上的代码生成能力。
关键设计:在桥梁生成阶段,论文使用了prompt工程技术,设计了合适的prompt,引导LLM生成高质量的HRPL代码。在桥梁对齐阶段,使用了微调技术,使用生成的数据集对LLM进行微调,优化LLM在LRPLs上的代码生成能力。具体的损失函数和网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


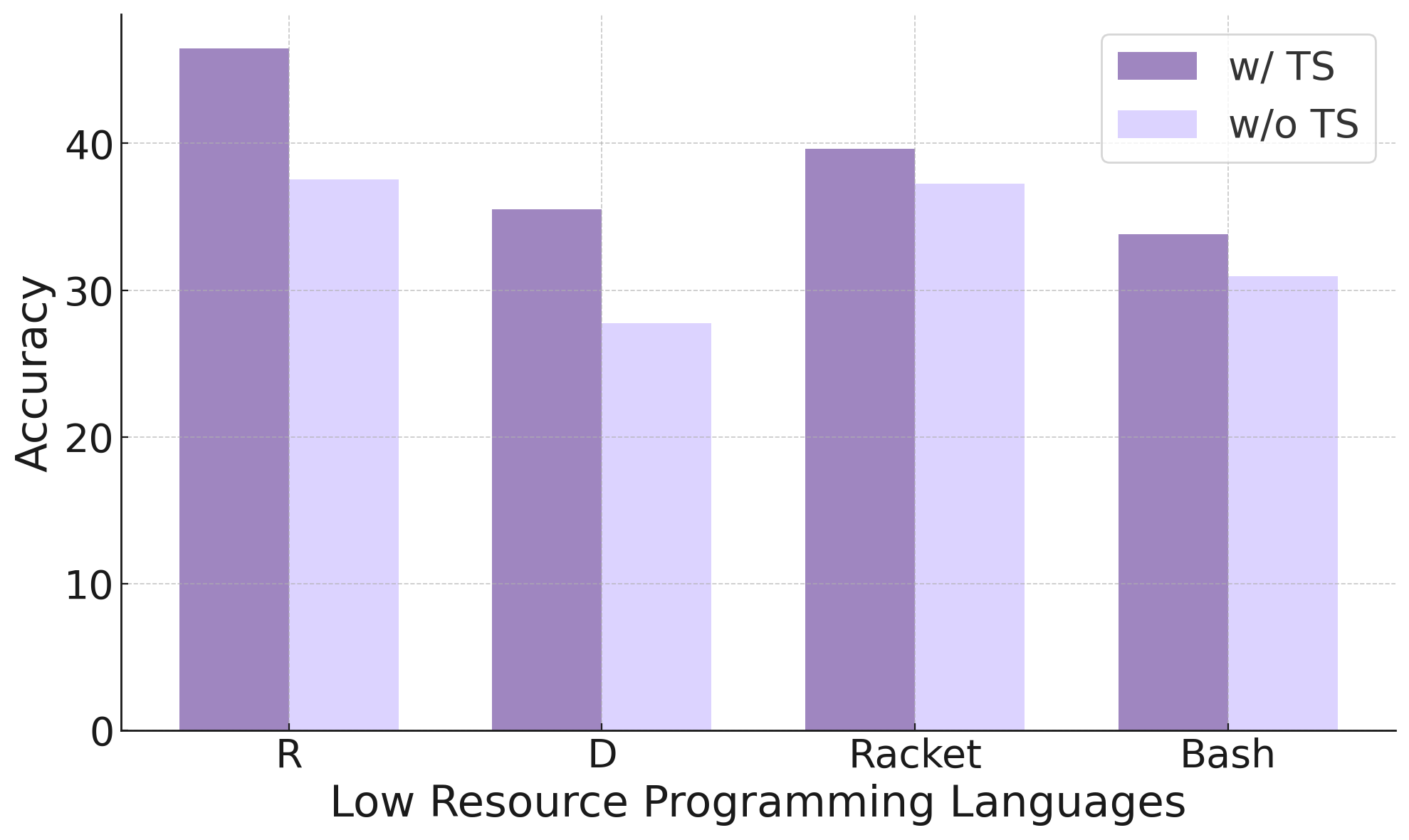
📊 实验亮点
实验结果表明,Bridge-Coder在多个LRPLs上显著提高了模型性能。例如,在Racket语言上,Bridge-Coder将模型的代码生成准确率提高了XX%(具体数值未知),超过了现有的基线方法。实验结果验证了Bridge-Coder方法的有效性和泛化能力。
🎯 应用场景
Bridge-Coder方法可以应用于各种低资源编程语言的代码生成任务,帮助开发者更高效地使用LLM进行LRPLs的开发。该方法能够降低LRPLs的学习门槛,促进LRPLs社区的发展,并缩小高低资源编程语言之间的数字鸿沟。未来,该方法可以扩展到其他低资源领域,例如低资源自然语言处理等。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate strong proficiency in generating code for high-resource programming languages (HRPLs) like Python but struggle significantly with low-resource programming languages (LRPLs) such as Racket or D. This performance gap deepens the digital divide, preventing developers using LRPLs from benefiting equally from LLM advancements and reinforcing disparities in innovation within underrepresented programming communities. While generating additional training data for LRPLs is promising, it faces two key challenges: manual annotation is labor-intensive and costly, and LLM-generated LRPL code is often of subpar quality. The underlying cause of this issue is the gap between natural language to programming language gap (NL-PL Gap), which is especially pronounced in LRPLs due to limited aligned data. In this work, we introduce a novel approach called Bridge-Coder, which leverages LLMs' intrinsic capabilities to enhance the performance on LRPLs. Our method consists of two key stages. Bridge Generation, where we create high-quality dataset by utilizing LLMs' general knowledge understanding, proficiency in HRPLs, and in-context learning abilities. Then, we apply the Bridged Alignment, which progressively improves the alignment between NL instructions and LRPLs. Experimental results across multiple LRPLs show that Bridge-Coder significantly enhances model performance, demonstrating the effectiveness and generalization of our approach. Furthermore, we offer a detailed analysis of the key components of our method, providing valuable insights for future work aimed at addressing the challenges associated with LRPLs.