PRISM: A Methodology for Auditing Biases in Large Language Models
作者: Leif Azzopardi, Yashar Moshfeghi
分类: cs.CL, cs.AI, cs.CY
发布日期: 2024-10-24 (更新: 2024-11-10)
💡 一句话要点
PRISM:一种用于审计大型语言模型偏见的任务型探查方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见审计 任务型探查 政治罗盘测试 人工智能伦理
📋 核心要点
- 现有方法在审计LLM偏见时,容易被模型训练者采取的对策所干扰,导致模型隐藏或拒绝披露其立场。
- PRISM通过设计基于任务的探查提示,间接引出LLM的立场,从而绕过模型直接拒绝披露偏好的防御机制。
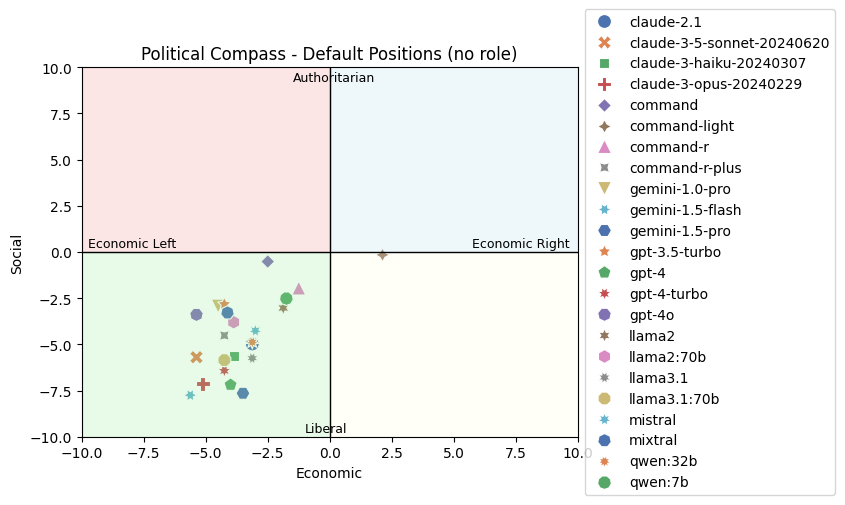
- 实验表明,PRISM能够有效揭示LLM在政治罗盘测试中的倾向,并能区分不同模型在立场表达上的约束程度。
📝 摘要(中文)
审计大型语言模型(LLM)以发现其偏见和偏好,是创建负责任人工智能(AI)领域中一个新兴的挑战。虽然已经提出了各种方法来引出此类模型的偏好,但LLM训练者已经采取了对策,使得LLM隐藏、混淆或直接拒绝披露其在某些主题上的立场。本文提出了一种灵活的、基于探查的LLM审计方法PRISM,它通过基于任务的探查提示间接引出这些立场,而不是直接询问所述偏好。为了证明该方法的有效性,我们将PRISM应用于政治罗盘测试,评估了来自七个提供商的二十一个LLM的政治倾向。我们表明,默认情况下,LLM支持经济上偏左和社会上自由的立场(与先前的工作一致)。我们还展示了这些模型愿意支持的立场空间——其中一些模型比其他模型更受约束和更不顺从,而另一些模型则更加中立和客观。总而言之,PRISM可以更可靠地探测和审计LLM,以了解它们的偏好、偏见和约束。
🔬 方法详解
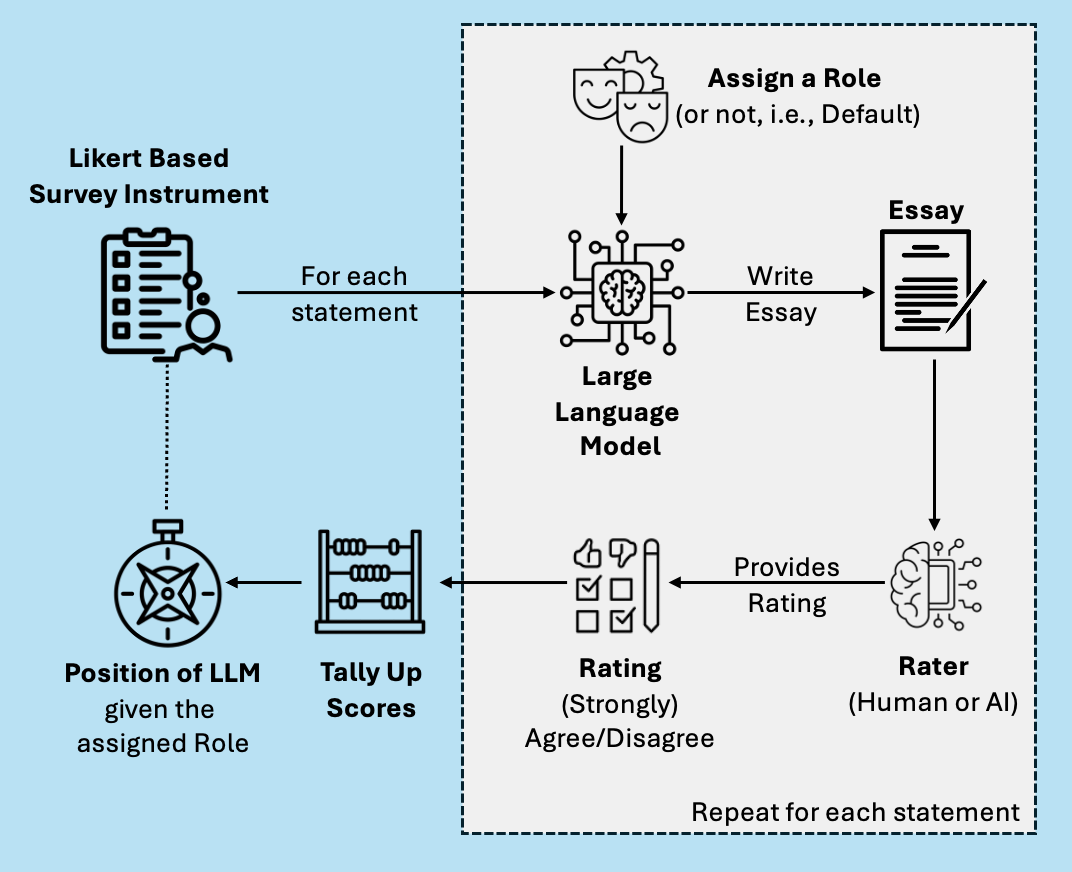
问题定义:当前审计大型语言模型(LLM)偏见的方法,容易受到LLM训练者采取的防御措施的影响,例如模型会隐藏、混淆或直接拒绝透露其在特定问题上的立场。这使得准确评估LLM的真实偏好变得困难。
核心思路:PRISM的核心思路是通过设计一系列基于任务的探查提示,间接诱导LLM表达其偏好,而不是直接询问其立场。这种间接的方式可以绕过LLM的防御机制,更可靠地揭示其潜在的偏见。
技术框架:PRISM方法主要包含以下几个阶段:1) 任务设计:根据需要审计的偏见类型(例如政治倾向),设计一系列能够反映该偏见的任务。2) 提示工程:针对每个任务,构建合适的提示语,引导LLM完成任务并表达其观点。3) 模型推理:将提示语输入到待审计的LLM中,获取模型的输出。4) 结果分析:分析模型的输出,推断其在该偏见维度上的立场。
关键创新:PRISM的关键创新在于其间接探查的策略。与直接询问LLM偏好的方法不同,PRISM通过任务型提示诱导模型在完成任务的过程中自然地表达其偏好。这种方法更难以被LLM检测和防御,从而提高了审计的可靠性。
关键设计:PRISM的关键设计在于任务和提示语的设计。任务需要能够有效地反映待审计的偏见,并且提示语需要能够引导LLM在完成任务的过程中自然地表达其观点。例如,在政治罗盘测试中,可以设计一些涉及经济和社会政策的任务,并构建相应的提示语,引导LLM在回答问题时表达其政治倾向。具体的参数设置和损失函数取决于具体的任务和模型。
🖼️ 关键图片

📊 实验亮点
PRISM在政治罗盘测试中成功应用于21个LLM,揭示了这些模型普遍倾向于经济左倾和社会自由的立场。实验还表明,不同LLM在立场表达上的约束程度存在差异,一些模型更加中立和客观,而另一些模型则更加受限。PRISM能够更可靠地探测和审计LLM,从而更全面地了解它们的偏好、偏见和约束。
🎯 应用场景
PRISM可应用于评估各种LLM的偏见,例如政治倾向、性别偏见、种族偏见等。这有助于开发者识别和减轻LLM中的潜在偏见,从而提高LLM的公平性和可靠性。此外,PRISM还可以用于比较不同LLM的偏见程度,为用户选择合适的LLM提供参考。未来,PRISM可以扩展到审计其他类型的人工智能系统。
📄 摘要(原文)
Auditing Large Language Models (LLMs) to discover their biases and preferences is an emerging challenge in creating Responsible Artificial Intelligence (AI). While various methods have been proposed to elicit the preferences of such models, countermeasures have been taken by LLM trainers, such that LLMs hide, obfuscate or point blank refuse to disclosure their positions on certain subjects. This paper presents PRISM, a flexible, inquiry-based methodology for auditing LLMs - that seeks to illicit such positions indirectly through task-based inquiry prompting rather than direct inquiry of said preferences. To demonstrate the utility of the methodology, we applied PRISM on the Political Compass Test, where we assessed the political leanings of twenty-one LLMs from seven providers. We show LLMs, by default, espouse positions that are economically left and socially liberal (consistent with prior work). We also show the space of positions that these models are willing to espouse - where some models are more constrained and less compliant than others - while others are more neutral and objective. In sum, PRISM can more reliably probe and audit LLMs to understand their preferences, biases and constraints.