Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance
作者: Omer Nahum, Nitay Calderon, Orgad Keller, Idan Szpektor, Roi Reichart
分类: cs.CL
发布日期: 2024-10-24 (更新: 2025-09-12)
💡 一句话要点
利用大语言模型检测并纠正数据集中的标签错误,提升模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 标签错误检测 大语言模型 LLM-as-a-judge 数据集质量 模型性能提升
📋 核心要点
- 现有NLP基准数据集依赖专家标注,成本高昂;众包标注质量难以保证,影响模型训练效果。
- 利用LLM作为评判者,通过LLM集成来识别潜在的错误标注样本,降低标注成本并提高标注质量。
- 实验表明,纠正检测到的标签错误能显著提升模型性能,表明部分模型“错误”实为标签错误。
📝 摘要(中文)
自然语言处理基准测试依赖于标准化数据集来训练和评估模型,这对于推动该领域的发展至关重要。传统上,专家标注确保高质量的标签;然而,专家标注的成本无法很好地随着现代模型所需更大数据集的需求而扩展。众包提供了一种更具可扩展性的解决方案,但通常以标注精度和一致性为代价。大型语言模型(LLM)的最新进展为增强标注过程提供了新的机会,尤其是在检测现有数据集中的标签错误方面。在这项工作中,我们考虑了最近的 LLM-as-a-judge 方法,利用 LLM 集成来标记可能被错误标记的示例。我们对来自 TRUE 基准测试的四个事实一致性数据集(涵盖不同的 NLP 任务)以及 SummEval(使用 Likert 量表对多个维度的摘要质量进行评级)进行了案例研究。我们实证分析了现有数据集的标注质量,并在一致性、标签质量和效率方面比较了专家、众包和基于 LLM 的标注,展示了每种标注方法的优势和局限性。我们的研究结果表明存在大量的标签错误,纠正这些错误可以显著提高报告的模型性能。这表明 LLM 的许多所谓错误是由于标签错误而不是真正的模型失败。此外,我们讨论了错误标记数据的影响,并提出了在训练中减轻这些影响以提高性能的方法。
🔬 方法详解
问题定义:论文旨在解决NLP基准数据集中标签错误的问题。现有方法,如专家标注成本高,众包标注质量差,导致模型训练受到影响,性能评估不准确。
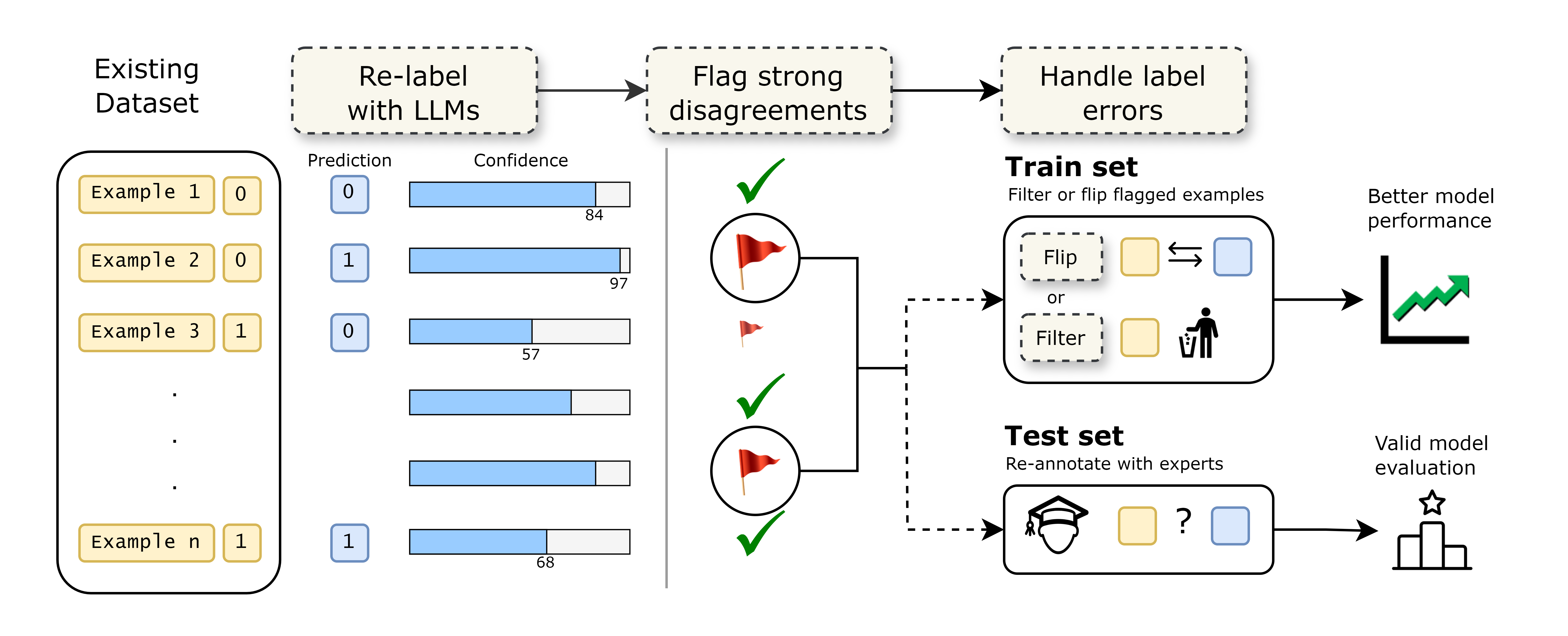
核心思路:论文的核心思路是利用大语言模型(LLM)作为“评判者”,通过集成多个LLM的判断结果,来识别数据集中潜在的错误标签。这种方法旨在降低标注成本,同时提高标注质量。
技术框架:整体流程包括:1) 选择数据集;2) 使用LLM集成对数据集进行标注,识别潜在错误标签;3) 对比LLM标注、专家标注和众包标注的一致性、质量和效率;4) 纠正错误标签并重新训练模型,评估性能提升。主要模块包括LLM集成模块和错误标签纠正模块。
关键创新:关键创新在于将LLM应用于标签错误检测,并将其作为一种可行的、低成本的替代方案。与传统方法相比,LLM能够利用其强大的语言理解能力,对数据进行更细致的分析,从而发现潜在的错误标签。
关键设计:论文使用了LLM集成,具体使用了哪些LLM模型以及如何进行集成(例如,投票机制、置信度加权等)的具体细节未知。此外,如何确定LLM判断的置信度阈值,以及如何处理LLM判断不一致的情况,也是关键的设计细节,但论文摘要中未提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在TRUE基准测试和SummEval数据集上,通过纠正LLM检测到的标签错误,模型性能得到了显著提升。这表明现有数据集中的标签错误对模型性能评估产生了负面影响,而LLM可以有效地识别并纠正这些错误,从而更准确地评估模型的能力。
🎯 应用场景
该研究成果可应用于各种NLP任务的数据集清洗和质量提升,例如文本分类、情感分析、机器翻译等。通过自动检测和纠正标签错误,可以提高模型的泛化能力和鲁棒性,减少人工干预,降低数据标注成本,加速NLP模型的开发和部署。
📄 摘要(原文)
NLP benchmarks rely on standardized datasets for training and evaluating models and are crucial for advancing the field. Traditionally, expert annotations ensure high-quality labels; however, the cost of expert annotation does not scale well with the growing demand for larger datasets required by modern models. While crowd-sourcing provides a more scalable solution, it often comes at the expense of annotation precision and consistency. Recent advancements in large language models (LLMs) offer new opportunities to enhance the annotation process, particularly for detecting label errors in existing datasets. In this work, we consider the recent approach of LLM-as-a-judge, leveraging an ensemble of LLMs to flag potentially mislabeled examples. We conduct a case study on four factual consistency datasets from the TRUE benchmark, spanning diverse NLP tasks, and on SummEval, which uses Likert-scale ratings of summary quality across multiple dimensions. We empirically analyze the labeling quality of existing datasets and compare expert, crowd-sourced, and LLM-based annotations in terms of the agreement, label quality, and efficiency, demonstrating the strengths and limitations of each annotation method. Our findings reveal a substantial number of label errors, which, when corrected, induce a significant upward shift in reported model performance. This suggests that many of the LLMs' so-called mistakes are due to label errors rather than genuine model failures. Additionally, we discuss the implications of mislabeled data and propose methods to mitigate them in training to improve performance.