DeCoRe: Decoding by Contrasting Retrieval Heads to Mitigate Hallucinations
作者: Aryo Pradipta Gema, Chen Jin, Ahmed Abdulaal, Tom Diethe, Philip Teare, Beatrice Alex, Pasquale Minervini, Amrutha Saseendran
分类: cs.CL, cs.AI
发布日期: 2024-10-24
💡 一句话要点
提出DeCoRe,通过对比检索头解码来缓解大语言模型的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉缓解 对比学习 检索头 解码策略
📋 核心要点
- 大语言模型存在幻觉问题,即生成不忠实或错误的输出,现有方法难以有效缓解。
- DeCoRe通过对比基础LLM和屏蔽检索头的LLM的输出,动态地放大上下文信息,从而减少幻觉。
- 实验表明,DeCoRe在摘要、指令遵循和开放式问答等任务上显著提高了性能,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)常常产生幻觉,即通过错误地表达上下文或不正确地回忆内部知识来生成不忠实或在事实上不正确的输出。最近的研究表明,Transformer架构中存在特定的注意力头,被称为检索头,负责提取相关的上下文信息。我们假设,屏蔽这些检索头会诱发幻觉,并且对比基础LLM和屏蔽LLM的输出可以减少幻觉。为此,我们提出了一种新颖的、无需训练的解码策略,称为通过对比检索头解码(DeCoRe),该策略放大了上下文中和模型参数中包含的信息。DeCoRe通过动态对比基础LLM和屏蔽LLM的输出,并使用条件熵作为指导,来减轻潜在的幻觉响应。我们的大量实验证实,DeCoRe显著提高了在需要高上下文忠实度的任务上的性能,例如摘要(XSum提高了18.6%),指令遵循(MemoTrap提高了10.9%)和开放式问答(NQ-Open提高了2.4%,NQ-Swap提高了5.5%)。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中普遍存在的幻觉问题,即模型生成不忠实于上下文或包含错误信息的输出。现有的方法往往难以有效地抑制幻觉,尤其是在需要高度上下文理解的任务中。这些方法可能无法充分利用上下文信息,或者过度依赖模型自身的知识,导致生成不准确或不相关的答案。
核心思路:DeCoRe的核心思路是通过对比LLM在正常状态和屏蔽特定注意力头(检索头)状态下的输出,来突出上下文信息的重要性。作者认为,屏蔽检索头会诱发幻觉,因此对比两种状态下的输出可以帮助模型更好地关注上下文,从而减少幻觉。这种对比过程利用条件熵来动态调整,引导模型生成更忠实于上下文的响应。
技术框架:DeCoRe是一种无需训练的解码策略,它主要包含以下几个步骤:1) 使用基础LLM生成初始输出;2) 屏蔽LLM中的检索头,生成另一个输出;3) 计算两个输出之间的条件熵,作为对比的权重;4) 根据条件熵,动态地对比两个输出,生成最终的输出。整个过程不需要额外的训练数据或参数调整,可以直接应用于现有的LLM。
关键创新:DeCoRe的关键创新在于它利用了Transformer架构中检索头的特性,并通过对比的方式来增强上下文信息的利用。与传统的解码策略不同,DeCoRe不是简单地选择概率最高的token,而是通过对比不同状态下的输出,来动态地调整生成过程,从而减少幻觉。这种对比机制能够有效地抑制模型自身的偏见,并鼓励模型更多地依赖上下文信息。
关键设计:DeCoRe的关键设计在于条件熵的使用。条件熵被用来衡量两个输出之间的差异,并作为对比的权重。具体来说,条件熵越高,说明两个输出之间的差异越大,模型越需要关注上下文信息。作者通过实验验证了不同检索头屏蔽策略和条件熵计算方法的有效性,并选择了最优的配置。
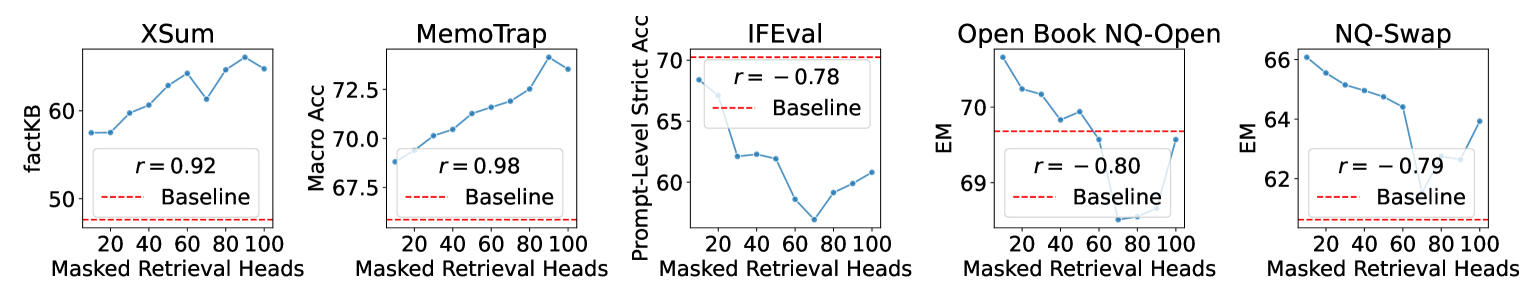
🖼️ 关键图片


📊 实验亮点
DeCoRe在多个需要高上下文忠实度的任务上取得了显著的性能提升。在XSum摘要任务上,DeCoRe的性能提升了18.6%。在MemoTrap指令遵循任务上,性能提升了10.9%。在NQ-Open和NQ-Swap开放式问答任务上,分别提升了2.4%和5.5%。这些结果表明,DeCoRe能够有效地减少LLM的幻觉问题,并提高其在各种任务上的性能。
🎯 应用场景
DeCoRe具有广泛的应用前景,可以应用于各种需要高上下文忠实度的自然语言处理任务,例如文档摘要、机器翻译、问答系统和对话生成。该方法可以提高这些任务的准确性和可靠性,减少模型产生幻觉的风险。此外,DeCoRe无需训练的特性使其易于集成到现有的LLM应用中,具有很高的实用价值。
📄 摘要(原文)
Large Language Models (LLMs) often hallucinate, producing unfaithful or factually incorrect outputs by misrepresenting the provided context or incorrectly recalling internal knowledge. Recent studies have identified specific attention heads within the Transformer architecture, known as retrieval heads, responsible for extracting relevant contextual information. We hypothesise that masking these retrieval heads can induce hallucinations and that contrasting the outputs of the base LLM and the masked LLM can reduce hallucinations. To this end, we propose Decoding by Contrasting Retrieval Heads (DeCoRe), a novel training-free decoding strategy that amplifies information found in the context and model parameters. DeCoRe mitigates potentially hallucinated responses by dynamically contrasting the outputs of the base LLM and the masked LLM, using conditional entropy as a guide. Our extensive experiments confirm that DeCoRe significantly improves performance on tasks requiring high contextual faithfulness, such as summarisation (XSum by 18.6%), instruction following (MemoTrap by 10.9%), and open-book question answering (NQ-Open by 2.4% and NQ-Swap by 5.5%).